| ||||
|
||||
'ORACLE > ADMIN' 카테고리의 다른 글
| 아카이브 로그 관련정보 (0) | 2006.06.26 |
|---|---|
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
| [Oracle]오라클 어드민 팁 (0) | 2006.03.17 |
| Oracle 장애의 유형과 문제해결 (0) | 2006.03.15 |
| 오라클 SID변경 작업 (0) | 2006.03.09 |
| ||||
|
||||
| 아카이브 로그 관련정보 (0) | 2006.06.26 |
|---|---|
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
| [Oracle]오라클 어드민 팁 (0) | 2006.03.17 |
| Oracle 장애의 유형과 문제해결 (0) | 2006.03.15 |
| 오라클 SID변경 작업 (0) | 2006.03.09 |
오라클 관계형 데이터베이스 소개
* oracle 시스템 데이터 Dictionary에 들어 있는 정보
1. 테이블과 뷰, 스냅샷, 인덱스, 동의어, 프로시저, 함수를 포함한 모든 데이터베이스 오브젝트의 이름
2. 오라클 데이터베이스 사용자의 이름
3. 각 사용자에게 주어진 특권과 역할
4. 무결성 제한의 명세
5. 열을 위한 초기 값
6. 스페이스 소비와 할당
7. 정보 오디팅(auditing)
* oracle 시스템 데이터 Dictionary의 필수적인 두 컴포넌트
1. 베이스 테이블
2. 사용자가 액세스 할 수 있는 뷰
* 데이터 Dictionary는 sys 사용자의 소유이다.
* 오라클 데이터베이스 논리구조 특징 정의
1. 테이블스페이스
2. 세그먼트
3. 영역(extents)
4. data block
논리적 데이터베이스 저장구조
* 테이블 스페이스를 사용하여 관리자가 하는 일
1. 데이터 베이스에 의한 물리적 디스크 스페이스 사용을 컨트롤 한다.
2. 특정 디스크 쿼타를 개별 사용자에게 할당한다.
3. 여러 물리적 저장장치에 걸쳐 데이터 저장을 할당한다.
* 테이블 스페이스를 나누는 잇점
1. 시스템 데이타와 사용자 데이터를 구분한다.
2. 애플리케이션들을 서로 구분할 수 있다.
3. 각 테이블스페이스를 하나는 온라인으로 다른 것은 오프라인으로 할 수 있는 기회를 제공한다..
4. 퍼포먼스를 개선하고 데이터 회선을 줄이기 위하여 서로 다른 테이블스페이스를 별도의 디스크 드라이브에 저장할 수 있는 능력
* 시스템 테이블 스페이스에 포함되는 것들
1. 프로시저 함수, 트리거, 패키지와 같은 PL/SQL, 롤백 세그먼트(rollback segment)
* 시스템 테이블 스페이스는 항상 온라인으로 있어야 한다.
* 테이블 스페이스가 오프라인일 필요가 있는 경우
1. 데이터베이스에서 유지 또는 백업을 수행하기 위해
2. 애플리케이션에의 업그레이드나 수정 중에 이용할 수 없는 테이블 그룹을 만들기 위해
3. 데이타 베이스가 온라인으로 있을때 일부를 이용할 수 없도록 만들때
* 테이블 스페이스 만들기
create tablespace dbt_user_01
datafile '<directory>/datafile_01' size 10m
default storage (
initial 50k
next 50k
minextents 10
maxextents 50
pctincrease 0)
offline;
* 기존의 테이블 스페이스에 새로운 데이터 파일 추가
alter tablespace dbt_user_01
add datafile '<directory>/new_file_name_2' size 5m
* 테이블 스페이스의 정보 보기
select tablespace_name, initial_extent, next_extent, max_extents, pct_increase,
from sys.dba_tablespace;
* segment
데이터를 저장하는 데이터베이스 오브젝트의 물리적인 부분
종류: 테이블, 인덱스, 롤백, 템포러리
* 테이블 세그먼트
테이블, 클러스터, 스냅샷으로부터의 데이터를 저장한다.
pctfree명령은 세그먼트가 가지는 프리스페이스의 양을 모니터링한다.
* 인덱스 세그먼트
인덱스 데이터를 수용한다.
* 롤백 세그먼트
원하면 롤백 하여야 할 sql트랜잭션의 활동을 기록하는 데이타베이스의 일부분이다
변경된 데이타를 위한 블록 id와 파일명, 마지막 트랜잭션 이전에 존재하였던 데이타를 포함
* Temporary 세그먼트
sql트랜잭션의 중간 결과를 수용
* Extents(영역)
연속적인 블록 번호들로 이루어지는 논리적 저장구조
* 데이터 블록
데이터를 저장하기 위하여 오라클이 사용하는 최소 저장단위
헤더,테이블디렉토리,로우디렉토리,로우데이타,프리스페이스를 포함한다.
* pctfree와 pctused
pctfree와 pctused 는 개발자가 데이터 블록 프리스페이스의 사용을 콘트롤 하는데 이용할 수 있다. 이 2개의 파라미터는 테이블과 클러스터를 만들거나 변경할 때에만 지정할 수 있다.
pctfree 35 : create와 함께 사용되며, 그 테이블을 위하여 사용되는 데이터 테이블의 35%를 가능한 장래의 갱신을 위한 프리로 남겨두라는 것
pctused 40 : create와 함께 사용되어 오라클로 하여금 그 블록의 40% 이상이 프리 일경우에만 데이타를 삽입하라는 것.
데이터 타입
* 데이터 타입
값의 범위를 제한해줌
* char type
1부터 255의 범위 문자 숫자 데이타를 저장한다.데이타 길이는 고정된다.
실제 들어가는 데이타가 할당된 것보다 적으면 나머지 부분엔 공백이 들어가고 그 반대의 경우엔 에러가 난다.
* varchar2
1부터 2000바이트의 범위(variable length)
* long
2기가 바이트까지의 정보를 포함하는 문자 데이터(variable length)
* row, long row
2진 데이타를 위한 것으로 이 데이타들은 멀티미디어 데이타나 2진 데이타를 위해 적절하다.
raw는 varchar2와 비슷하고 long law는 long과 비슷하다.
* row id
클러스터되지 않은 오라클 테이블에서 행의 물리적 주소에 해당
다음과 같이 사용 가능하다.
select rowid, ename from emp
row id EMP_NAME
--------------------------
000c0b7.0000.0001 'WHITE'
000c0b7 : 데이터 블록
0000 : 행 시퀀스 번호
0001 : 데이터 파일 번호
* row id의 특징
1. 가장 빠른 행 액세스 속도
2. 테이블이 어떻게 조직되는지 보는데 사용할 수 있다.
3. 주어진 테이블에 있는 행들을 위한 고유한 식별자. rowid는 인덱스 구축에 사용됨
* mlslabel 데이타 타입
Trusted Oracle을 위해 사용되며 255바이트의 최대 크기를 갖는다.
테이블
* 테이블 만들기
create table emp (
empno number(15) primary key,
first_name varchar2(20) not null,
last_name varchar2(40) not null,
deptno varchar2(12),
hire_date date not null)
pctfree 20
pctused 40
tablespace emp_01
storage (initial 50k
next 50k
maxextense 15
pctincrease 25);
empno는 주키로 사용된다.
pctfree는 장래의 확장을 위하여 프리 스페이스로서 예비된 각 데이터블럭의 퍼센티지를 나타내다. 20%가 예비된다.
pctused는 새로운 레코드를 삽입하기 위해 남아 있어야 할 양이다.
pctfree 값을 크게 하면 사용되지 않는 공간을 증가시키지만 sql명령의 효율을 증가시킨다.
pctused값을 크게 하면 미사용저장 공간을 줄이긴 하지만 insert, update실행의 퍼포먼스를 저하시킨다.
* 테이블 코멘트
테이블이나 열에 대한 코멘트를 데이타 사전에 추가하려면 comment명령을 사용한다.
comment on column emp.hire_date IS '무라무라';
코멘트를 제거하려면
comment on column emp.hire_date IS ''
* 테이블 제작중에 테이블 로드하기
앞의 테이블 작성 예에 다음을 추가한다.
as select empid, f_name, l_name, dept, hire_date from uk_emp;
* 테이블 클러스터 만들기
클러스터는 테이블 테이터를 저장하는 선택적인 방법. 자주 함께 액세스되는 테이블은 동일한 데이터 블럭에 물리적으로 함께 저장된다.
create cluster emp_dept ( deptno number(5))
pstused 80
pctfree 5;
* 클러스터 인덱스 만들기
create index i_emp_dept
on cluster emp_dept;
* 테이블 변경
alter table dept
add (dept_mgr varchar2(35));
alter table emp
modify (sal not null);
alter table emp
add constraint s_dept_man_id_fk foreign key (deptno) references dept;
change dept to emp
alter table dept
drop constraint s_dept_man_id_fk
alter table emp
* 테이블 잘라내기
truncate table명령 사용
장점 : 롤백세그먼트를 사용하지 않는다.실행즉시 테이블스페이스를 해제한다.
단점 : 롤백되지 않으므로 사용에 신중해야 한다.
시노님(Synonym)
* 시노님(Synonym)
오라클 오브젝트를 위한 앨리어스(alias)이다.실제적인 오라클 오브젝트가 아니라 오브젝트에 대한 직접적인 참조이다. 이 오브젝트는 테이블, 뷰, 스냅샷, 시퀀스, 프로시저, 함수, 패키지 또는 다른 시노님이 될 수 있다.
제약: 프로시저 안에 포함될 수 없다.
* 시노님 사용 이유
1. 데이터 사전에 대한 정의 외에는 어떤 스토리지도 요구하지 않는다.
2. sql코딩을 단순화한다.
3. 데이터베이스 보안을 개선한다.
4. 오라클 오브젝트에의 퍼블릭 액세스를 제공한다.
* 시노님 만들기
create public synonym emp FOR emp_01.emply;
create synonym emp for emp_01.emply
public을 쓰지 않으면 전용 시노님이 된다.(반대: 공용)
리모트의 데이타베이스를 참조하는 시노님은 다음과 같이 만든다.
create synonym part for master_part.part_number@corp;
* 시노님 사용하기
select * from emp;
시노님을 사용하지 않는다면
select * from emp_01.emply;
* 시노님 이름 바꾸기
rename dept to bus_unit;
인덱스와 시퀀스
(Indexs and Sequence)
* 인덱스 생성 지침
1. 테이블에서 행의 15%이하만을 검색하는 경우가 많을때
2. 인덱스 열은 다수의 테이블 조인을 개선하기 위한 연결에 이용될때
3. 행이 몇 안되는 작은 테이블은 인덱스 않는다.
4. 주요키와 고유키는 자동적으로 인덱스를 갖지만 대개는 모든 외부 키에도 인덱스를 만드는 것이 좋다
5. 열에 널 값이 없는것이 좋다
6. 테이블이 읽기 전용이면 인덱스가 많을수록 편리 하고 갱신이 많을경우엔 인덱스가 적을수록 좋다
예.emp테이블에서 phone열에 고유한 인덱스를 만든다.
create unique index i_emp_phone_uk on emp(phone);
또한 복수 열에 대해서 인덱스를 만들수도 있다.
예. create index i_emp_city_zip
on emp(city, zip);
=> 이런 경우 가장 많이 쓰이는 열을 우선 놓는다. 모두 16개까지 열을 넣을 수 있다.
* 인덱스 생성시의 파라메터
1. tablespace : 인덱스가 생성되는 테이블 스페이스를 지정할 수 있다.
2. cluster : 클러스터를 위하여 인덱스된 클러스터 키의 이름을 제공
3. pctfree : table의 pctfree와 같은 용도
4. initrans : 인덱스된 세그먼트의 데이터 블록에 트랜잭션 엔트리를 위하여 초기에 얼마나 많은 스페이스를 할당될 수 있는지 정의
5. maxtrans : 인덱스된 데이터 블록에 트랜잭션 엔트리를 위하여 초기에 할당할 수 있는 최대 스페이스 수를 정의
6. storage : 스토리지 파라미터로서 작은 영역을 많이 갖는것 보다 많은 영역을 적게 갖는게 좋다.
* 인덱스 없애기
drop index i_emp_city_zip;
* 클러스터된 인덱스
클러스터된 테이블이 만들어지고 나면 데이타 입력 전에 우선 그 크럴스터에 대한 인덱스부터 만들어야 한다.
* 시퀀스 만들기
create sequence s_empno
increment by 1
start with 1
nomaxvalue
nocycle
cache 15;
=> s_empno라는 시퀀스를 만들고 번호들의 시퀀스 리스트는 1의 값부터 시작되며 연속되는 번호마다 1씩 증가한다. 이 시퀀스에는 최대값이 없으므로
그 시퀀스는 초기값으로부터 순환하지 않으며 서버의 퍼포먼드를 위해 메모리에 15개까지의 시퀀스를 미리 만들어둔다
* 시퀀스 확인
select sequence_name, min_value, max_value, increment_by, last_number
from user_sequences;
* 시퀀스 변경하기
alter sequence s_empno
maxvalue 50000
cache 20
cycle;
* 시퀀스의 사용
insert into emp (empno, first_name, last_name)
values (s_empno.nextval, 'thomas', 'smith');
* 시퀀스의 .nextval, .currval등의 의사열을 쓸 수 있는 상황
1. insert문에서 value절
2. select 문의 선택 리스트
3. update명령의 set 절
* 시퀀스의 .nextval, .currval등의 의사열을 쓸 수 있는 상황
1. distinct 절이 있는 select문
2. order by또는 group by절이 있는 select문
3. 연산자 union, minus또는 intersect에서 사용되는 select 문
4. 서브쿼리, 뷰 쿼리, 스냅샷 쿼리
뷰(Views)
* 뷰(view)를 사용하는 이유
1. 테이블의 사전 정의된 행과 열 세트에 대해서 액세스를 제한함으로써 데이터베이스 보안의 추가적인 단계를 제공
2. 기저 조인과 테이블 구조를 숨김으로써 사용자들에게 데이터 프리젠테이션을 간략하게 제공
3. 기본 테이블의 데이터와는 다른 재생으로 데이터를 표현한다.
* 뷰 만들기
create view emp_view as
select empno, f_name, l_name, deptno
from emp
where deptno=12
with check option constraint emp_cnst;
emp_view뷰는 deptno가 12인 행만을 인용하며 with check option은 뷰가 선택될 수 없는 행의 뷰가 만들어지거나 산출되도록 허용되지 않는 상황에서 insert, update문 같은 제한을 사용해서 뷰를 제작하게 된다. 따라서 deptno가 12인 행만이 뷰로 삽입될 수 있다.
또한 뷰를 만들때 여러 테이블을 조인하여 만들 수도 있다.
제약: 1. 행이 조인을 포함하는 쿼리를 사용해서 정의된 뷰로 삽입되거나 갱신되지 못하기 때문에 위의 예에서는 with check option이 상술되지 못한다.
2. for update절이나 order by절을 사용하지 못한다.
create view force는 테이블이 존재하지 않거나 사용자가 테이블에 대한 권한이 없어도 뷰를 만들게 한다.
반대로 create view noforce는 권한이 있거나 테이블이 존재 하여야만 뷰를 만들수 있다.
* 뷰 교체하기
뷰의 정의를 바꾸려면 뷰를 교체 해야 한다.
create or replace view emp_dept_name as
select f_name, l_name, empno, dept.deptno
from emp, dept
where emp.deptno = 15;
효과:
1. 데이터 사전에 있는 뷰 정의가 갱신된다. 모든 기저 오브젝트는 뷰 교체에 의한 영향을 받지 않는다
2. 원래의 뷰 정의에 있다가 교체된것에 정의되어 있지 않은 것은 드롭된다.
3. 교체된 뷰에 종속된 모든 뷰와 PL/SQL프로그램은 무효로 된다.
* 뷰 사용하기
select f_name, l_name, empno from emp_dept_name;
* 뷰가 사용가능한 절
select, insert, update, comment, lock table
* 뷰의 제한
1. 뷰의 쿼리가 join operation이나 set또는 distinct연산자, group by절, 또는 group함수를 포함하고 있을 때 insert, update 또는 delete연산을 수행하는데 뷰를 사용할 수 없다.
2. with check option 절을 이용하여 뷰를 정의할 경우에는 그 뷰를 사용하여 기저 테이블의 행을 삽입하거나 갱신할 수 없다.
3. default value절 없이 not null열이 정의될 때에는 뷰를 사용 하여 베이스 테이블에 행을 삽입할 수 없다.
4. 뷰가 decode표현식을 사용하여 만들어졌을 경우에는 그 뷰를 사용하여 행을 테이블에 삽입할 수 없다.
5. 뷰의 쿼리는 nextval, currval의사열을 참조할 수 없다.
6. 추가 프로세싱 타임으로 서버의 반응시간을 약간 감소시킨다.
* 뷰 재컴파일
alter view emp_dept compile;
스냅샷(Snapshots)
* 스냅샷
마스터 테이블이라고 하는 하나 이상의 테이블 쿼리의 결과를 포함하는 테이블 또는 전형적으로 리모트 노드에 위치하는 뷰. 본질적으로 리모트 데이터베이스의 로컬 카피라고 볼 수 있다. 읽기 전용이며. 갱신이 발생되지 않는다.
일단 스냅샷에 테이터가 캡춰되면 재생 사이클에 의해 재생될때까지 데이터는 변하지 않는다.
또한 내부적으로 스냅샷은 스키마 오브젝트의 집합이다.
* 스냅샷 제작 중에 만들어 지는 오브젝트
1. 스냅샷 쿼리의 결과를 수용하기 위해 리모트 노드에서 베이스 테이블이 만들어짐
2. 베이스 테이블에 대하여 쿼리가 주어질 때 사용될 읽기 전용 뷰가 이 베이스 테이블에서 만들어진다.
3. 주기적인 스냅샷 재생 프로세스를 위하여 로컬 노드에서 마스터 테이블에 뷰가 만들어진다
* 스냅샷 사용 이유
네트웍 통신량을 줄이고 어플리케이션 퍼포먼스를 개선할 수 있다.
* 스냅샷이 많이 사용되는 경우
1. 마스터 테이블이 잘 갱신되지 않지만 많이 액세스될대
2. 많은 리모트 사용자에 의하여 마스터 테이블이 액세스될때
* 스냅샷 설정시 필요한일
스냅샷의 제작, 사용, 재생, 올바른 특권설정
* 스냅샷 종류
1. 단순 스냅샷
단 하나의 테이블을 쿼리
2. 복합 스냅샷
복수의 테이블과 뷰를 쿼리할 수 있다.
* 스냅샷 준비
환경설정 스크립트 실행(catsnap.sql, dbmssnap.sql)
마스터 테이블을 수용하는 데이터베이스와 스냅샷을 수용하는 곳 모두에서 실행해야 함
* 스냅샷 만들기
create snapshot UK_emp
pctfree 15
pctused 55
tablespace user_01
storage(initial 50k
next 50k
pctincrease 10)
refresh fast
start with sysdate
next sysdate +1
as select * from emp@uk
* 스냅샷을 만들기 위해 필요한 특권
create snapshop, create table, create view
* 단순스냅샷은 다음을 포함하면 안된다.
group by, connect by, sub query, join, set 연산자
* 스냅샷의 장단점
단순 스냅샷: 재생이 발생할때 효율적, 쿼리 실행중엔 느려짐
복합 스냅샷: 쿼리 실행중에 효율적, 재생이 발생할때 비효율적
* 스토리지 파라미터 설정
복합 스냅샷이 재생중에 최대의 효과를 내기 위해서 pctfree는 0으로 설정되어야 하고 pctused는 100으로 설정해야 한다.
* 스냅샷 이용하기
select deptno, dept_name from dept
또한 스냅샷에 기초하여 시노님을 만들수도 있다.
create synonym emp for UK_emp;
* 한계
스냅샷은 읽기 전용이므로 update, insert, delete등은 불가능하다.
* 스냅샷 로그
스냅샷에서 재생을 수행하는데 필요한 프로세스의 양과 시간을 줄이는데 사용.
스냅샷 로그로부터 스냅샷을 재생하는 프로세스는 속성재생이라 한다.
스냅샷 로그를 사용하지 않고 스냅샷을 재생하는 것은 완전한 재생이라고 한다.
* 스냅샷 로그 만들기
create snapshot log on UK_emp
tablespace emp_01
storage (initial 20k next 20k pctincrease 25);
* 스냅샷 로그를 만들기 위한 조건
create table권한과 create trigger시스템 특권이 있어야 한다.
* 스냅샷 로그 Truncate하기( 로그가 너무 커지는것 방지)
execute dbms_snapshot.purge_log('master_table',3,'DELETE');
* 스냅샷 인덱스 하기
create index i_uk_emp on snap$UK_emp (deptno);
* 스냅샷 재생하기
오라클이 자동으로 스냅샷을 재생하게 만들려면 다음의 단계를 거치면 된다.
1. create snapshot문에 start with와 next파라미터를 지정한다. start with절은 첫번째 자동 재생 사이클 시간을 설정한다. next절은 자동 재생 사이의 간격을 지정한다.
2. 오라클은 start with와 next파라미터를 평가하여 이 정보를 데이터 사전에 저장한다. 이 파라미터는 장래의 한 시점으로 설정하여야 하며 그 렇지 않으면 에러난다.
create snapshot master_emp
pctfree 15
pctused 25
tablespace user_03
storage(initial 50k next 50k pctincrease 10)
refreshh start with round(sysdate+1) + 9/24
fast next trunc(sysdate, 'MONDAY') + 3/24
as select * from emp
스냅샷이 다음날 오전 9시와 그 후 매주 월요일 오전 3시에 재생될 것이라고 지정한다
* 재생 프로세스의 시간과 모드 변경
alter snapshot part_master mode fast;
* 빠른 스냅샷 재생 조건
1. 스냅샷이 단순 스냅샷이다.
2. 마스터 테이블에 스냅샷 로그가 있다.
3. 스냅샷이 마직막으로 재생되거나 만들어지기 전에 스냅샷 로그가 만들어 졌다.
* 스냅샷과 스냅샷 로그 DROP
drop snapshot UK_emp;
drop snapshot log on master_emp;
스냅샷 드롭위한 권한-> drop any table과 drop any trigger시스템 특권
* 커서란?
커서는 나중에 액세스하기 위하여 특정 문장을 수용할 전용인 메모리 구역을 사용자가 명명할 수 있게 해주는 구조
* implicit cursor
insert, delete, update문등이 사용
* explicit
사용자가 선언하며 복수의 행을 리턴하는 쿼리결과를 처리
커서(Cusors)
* 커서 사용 이유
커서는 복수 행 결과 세트를 한 번에 한 행씩 처리하는데 사용되고 커서는 어떤 행이 현재 액세스되고 있는지 추적하며 이것은 활성세트(쿼리로부터 리턴된 복수행)를 반복해서 처리할 수 있게 해준다
* 커서 사용 단계
1. 커서를 선언
2. 커서를 연다
3. 데이터를 커서에 불러온다
4. 커서를 닫는다
* 명시적(explicit) 커서 선언
선언하기 위해 커서의 이름을 붙이고, 커서를 쿼리와 결합한다.
declare
cursor c_parts is
select * from master_parts;
* 파라미터를 이용하여 선언하기
declare
cursor c_parts (v_part_qty number) is
select * from master_parts where parts_qty > v_part_qty
* 명시적 커서 열기
open c_parts
-> 커서는 그 활성 세트의 첫 행 바로 전으로 초기화 된다.
* 명시적 커서 속성
커서에 대한 유익한 정보를 얻기 위하여 사용
1. %isopen : 커서가 열려 있는지에 대한 불린 값 리턴
begin if c_cursor%isopen then fetch c_cursor into v_order_qty, v_order_price; else open c_cursor; end if; end;
2. %notfound : 가장 최근의 fetch실행에 의해 아무 행도 리턴되지 않으면 true
loop fetch c_cursor into v_ord_qty, v_ord_price; exit when c_cursor%notfound end loop; end;
3. %found : 가장 최근의 fetch가 행을 리턴하지 않을 때까지 True로 평가한다.
%notfound의 논리적 반대이다.
4. %rowcount : fetch에 의하여 리턴된 행의 총수가 되는 숫자 속성
* 명시적 커서 사용하기
커서는 이미 불러온 fetch정보를 다시 볼수 없기 때문에 다시 읽으려면 커서를 닫고 나서 처음부터 fetch를 다시 해야 한다.
* 명시적 커서 닫기
close c_orders;
* 암시적 커서(implicit cursor)
모든 sql문은 암시적 커서를 자동적으로 만든다.
* 패키지 커서
오라클은 커서의 명세가 패키지에 저장될 수 있도록 해준다. 이 명세에서는 러턴절이 사용되어야 한다. 커서에 대한 이 어프로치는 커서 명세를 바꾸지 않고도 커서를 바꿀수 있게 해준다.
create package emp_monthly as
cursor c_emp_sal return emp%rowtype;
emp emp_monthly;
create package body emp_monthly as
cursor c_emp_sal return emp%rowtype;
select emp_id, emp_salary from master_emp where hire_date > '01-JAN-1986';
end emp_monthly;
* 커서 for 루프
커서 for루프는 다음을 수행함으로써 코드화 작업을 단순화 할 수 있다.
1. 루프가 초기화될때 암시적 open이 실행된다.
2. 루프의 각 반복을 위하여 암시적 fetch가 실행된다.
3. 루프가 중지될 때 암시적 close가 실행된다.
begin for order_rec in c_cursor loop v_order_total := v_order_total+ ((order_rec.qty * order_rec.qty)*.95); insert into master_order (part_id, order_total) values (order_rec.part_id, v_order_total); end loop; commit end;
* 커서 앨리어스
쿼리 문이 표현식을 갖고 있을때 참조할때 문제가 생기는 경우 해결 방안
* 커서 퍼포먼스
커서 내부에서 실행 호출의 속도는 파리미터 cursor_space_for_time의 값을 조정하여 개선한다.
데이터 무결성(Data Integrity)
* 데이터 무결성
데이터 무결성은 테이블에 있는 열에 대하여 유효한 값을 제한하는 규칙을 정의한다
* 데이터 무결성 사용 이유
데이터 무결성 제한은 데이터베이스 테이블에 무효한 데이터 입력을 막는데 사용
* 데이터 무결성 이용 방법
데이터베이스의 테이블에서 정의됨
뷰와 테이블 시노님은 기저 베이스 테이블에서 정의된 무결성 제한에 따른다.
* 무결성 사용하는 곳
어플리케이션 보다 데이터 베이스 차원에서 하는 것이 효과적이다.
* 무결성 제한의 종류
1. 널형
2. 고유형
3. 주키 형
4. 참조형
5. 점검형
무결성 제한을 설정하기 위하여 create table 이나 alter table절에서 constraint절을 포함시킬 수 있다. 구문 포맷은 다음과 같다.
constraint constraint_name constraint_type
* 참조형 무결성 제한
서로 다른 테이블의 열 사이의관계를 지배하는 규칙을 정한다
alter table address
add constraint fk_state_abbr
foreign key (state_abbr)
references state_abbr (state_abbr)
* 외부 키의 삭제를 캐스케이드하기
on delete cascade는 자식 테이블에종속 행을 갖고 있는 부모 테이블에서 참조된 키 값을 삭제할 수 있게 해주며, 부모 테이블의 삭제가 발생할때 오라클은 자동적으로 그 자식 테이블에 있는 해당 행들을 삭제한다.
* 점검형 무결성 제한
check 무결성 제한은 참이 되어야 하는 조건을 명시적으로 정의한다.
제약: 서브쿼리를 포함할 수 없다. sysdate, uid, user, userenv함수를 포함불가능 curral, netval, leve, rownum의사열을 사용할 수 없다.
create table office_location
(office id number(5),
city varchar2(50)
constraint check_city
check(city in ("Dallas","Denver","Indianapolis"),
state varchar2(50));
* 무결성 제한 디스플레이하기
테이블:USER_CONSTRAINTS, USER_CONS_COLUMN
select constraint_name, constraint_type
from user_constraints
where table_name='mst_parts';
* 무결성 제한 유효화,무효화하기
alter table mst_parts
disable constraint s_parts_code_fk;
특히 Loader등을 통해 데이터를 로딩하는 동안과 프로세스를 임포트하고 엑스포트하는 동안이다.
* 무결성 제한의 시스템 뷰
1. all_constraints : 액세스 가능한 모든 테이블을 위한 제한 정의
2. all_cons_columns : 제한 정의에 있는 액세스 가능한 열에 대한 정보
3. user_constraints : 사용자의 테이블에 대한 제한 정의
4. user_cons_columns : 사용자가 소유하는 제한 정의에 있는 열에 대한 정보
5. dba_constraints : 데이타베이스의 모든 테이블에 대한 제한 정의
6. dba_cons_columns : 제한 정의에 있는 모든 열에 대한 정보
* 무결성 제한 drop하기
alter table mst_parts
drop constraints s_parts_code_라;
트랜잭션(Transactions)
* 트랜잭션 이란?
하나의 논리적 작업 단위를 구성하는 하나 이상의 sql문
* 트랜잭션의 효과를 데이타베이스에 확립시킴=> commit
* 트랜잭션의 효과를 데이타베이스에서 제거=> rollback
* 트랜잭션 사용 이유
사용자와 오라클 서버, 애플리케이션 개발자, 데이터베이스 개발자에게 데이터 일치성과 데이터 동시발생을 보장
* set transaction
1. 트랜잭션을 읽기 전용 트랜잭션이나 읽기-쓰기 트랜잭션으로 설정한다.
2. 현재 읽기-쓰기 트랜잭션을 지정된 롤백 세그먼트에 대입한다.
* 트랜잭션 커밋(commit)하기
커밋 하기 전까지 트랜잭션은 다음과 같은 특징을 갖는다.
1. DML은 데이터 베이스 버퍼에만 영향을 미친다. 따라서 변경사항이 백아웃 될수있다.
2. 롤백 세그먼트 버퍼가 서버에 만들어 진다.
3. 트랜잭션의 소유자는 select문을 사용하여 트랜잭션의 효과를 볼 수 있다.
4. 데이터베이스의 다른 용법으로는 트랜잭션의 효과를 볼 수 없다.
5. 영향을 받은 행들을 lock되며 다른 사용자들들 영향을 받은 행 안에 있는 데이터를 변경할 수 없다.
커밋이 실행되면 다음의 단계들이 발생한다.
1. 영향받은 행에 수용된 lock들이 풀린다.
2. 트랜잭션이 완료된 것으로 표시된다.
3. 서버의 내부 트랜잭션 테이블이 시스템 변경 번호를 생성하고, 이 번호를 트랜잭션에 대입하고, 번호들을 모두 테이블에 저장한다.
* commit과 함께 comment절을 사용하여 텍스트 스트링을 트랜잭션 ID와 함께 데이터 사전에 넣을수 있다.
* Two-Phase Commits
분산 commit을 수행(분산 데이타베이스 환경에서)
* 트랜잭션 롤백하기
트랜잭션을 롤백한다는 것은 현재 트랜잭션이 행한 모든 변경을 해제한다는 것을 의미 전체 트랜잭션의 롤백을 실행하려면 sqlplus상에서 rollback명령을 실행한다.
다른 방법으로 rollback to savepoint를 사용하여 일부만 rollback할 수 있다.
* 트랜잭션 전체 롤백할때의 단계
1. 현재 트랜잭션의 의하여 이루어진 모든 변경은 해당 롤백 세그먼트를 사용하여 해제할 수 있다.
2. 트랜잭션에 의하여 야기된 행에 있는 모든 lock이 풀린다.
3. 트랜잭션이 끝난다.
* 트랜잭션을 savepoint에 롤백할 때에는 다음의 단계가 발생한다.
1. 마지막 savepoint가 롤백된 후, sql문만 실행된다.
2. 롤백 명령에서 지정된 마지막 저장점(savepoint)이 보존되지만 그 저장점 이후의 다른 모든 저장점은 그 데이타 베이스로부터 제거된다.
3. 지정된 저장점 이후에 설정된 모든 lock은 풀린다.
4. 트랜잭션이 아직 활동 중이며 계속 될 수 있다.
* 저장점(savepoint) 만들기
savepoint master_credit;
* 저장점을 이용해 롤백하기
rollback to savepoint master_credit;
rollback to master_credit;
* 롤백 세그먼트
set transaction
use rollback segment rbs_mst_credit;
* 롤백 세그먼트의 크기는 롤백 세그먼트의 스토리지 파라미터에 의해정의됨
만약 애플리케이션이 매우 짧은 트랜잭션을 실행하고 있다면 롤백세그먼트는 항상 메모리에 캐시될 수 있을 정도로 작아야 할 것이다. 이렇게 되면 퍼포먼스가 향상된다.
* 롤백 세그먼트를 위해서는 높은 maxextents값을 설정해야 한다.
* 데이터 locking
2가지 레벨: 독점, 공유
* 이산 트랜잭션 관리(Discrete Transaction Management)
패키지(Packages)
* 패키지란?
관련된 스키마 오브젝트의 캡슐화된 집합. 이 오브젝트는 프로시저와 함수, 변수 상수, 커서, 그리고 예외(exception)를 포함할 수 있다.
* 패키지 구성 컴포넌트
1. 명세: 타입과 변수, 상수, 예외, 사용할 수 있는 서브프로그램을 선언
2. 본체: 커서와 함수, 그리고 프로시저를 완전히 정의하고 그 명세를 구현한다
* 패키지 사용 잇점
1. 어플리케이션 개발을 효율적으로 모듈에 조직하는 능력.
2. 패키지는 특권(privileage)를 보다 효율적으로 허가할 수 있게 해준다.
3. 패키지의 퍼블릭 변수와 커서는 그 세션동안 지속된다. 그러므로 이 환경을 실행하는 모든 커서와 프로시저가 패키지의 퍼블릭 변수와 커서들을 공유할수 있다.
4. 패키지는 프로시저와 함수에서의 오버로딩을 수행할 수 있게 해준다.
5. 패키지는 한 번에 여러 오브젝트를 로드함으로써 퍼포먼스를 개선한다.
* 패키지 사용법
SQL*DBA나 SQL*PLUS를 사용
* 패키지에 필요한 힌트
1. 기존의 오라클함수와 중복되는 패키지를 쓰는 것을 피한다.
2. 재사용에 대비해 간단하고 범용적으로 만든다.
3. 어플리케이션을 설계한 후 패키지 본체를 설계한다. 모든 사용자가 볼 수 있도록 하고 싶은 오브젝트만 패키지 명세에 넣는다.
4. 너무 많은 아이템을, 특히 컴파일링을 필요로 하는 아이템을 패키지 명세에 넣는 것을 피한다.
* 패키지 명세
패키지 명세에는 패키지 이름의 퍼블릭 선언과 모든 인수의 데이터 타입과 이름이 포함된다.
* 패키지 명세 선언
create package inv_pck_spec as
function inv_count(qty number, part_nbr varchar2(15))
return number;
procedure inv_adjust(qty number);
end inv_pck_spec
* 본체가 없는 패키지 선언
create package inv_constings is
type inv_rec is record
(part_name varchar2(30),
part_price number,
part_cost number);
price number;
qty number;
no_cost exception;
cost_or exception;
END inv_costings;
* 패키지 만들기
1. 명세 만들기
create or replace package inv_pcg_spec as
function inv_count(qty integer, part_nbr varchar2(15))
return integer;
procedure inv_adjust(qty integer);
end inv_pck_spec;
위의 예에서 create or replace를 썼는데 이렇게 하면 기존 패키지와 관련된 허가권한은 그대로 유지된다.
2. 본체 만들기
create or replace package body inv_control is
function inv_count
(qty integer,
part_nbr varchar2(15))
return integer is;
new_qty:= qty*6;
insert into mst_inv values
(new_qty, part_nbr);
return(new_qty);
end inv_count;
procedure inv_adjust(qty integer);
begin
delete from user_01.mst_inv
where inv_qty<10000;
end;
begin -- package initialization begins here
insert into inv_audit values
(sysdate, user);
end inv_control;
* 패키지 서브프로그램 호출
1. 오라클이 사용자 액세스를 확인한다.
2. 프로시저 유효성을 확인한다.
3. 패키지 서브프로그램이 실행된다.
* 패키지 서브프로그램 참조
package_name.type_name
package_name.object_name
package_name.sunprogram_name
* 패키지를 위한 시노님
1. 패키지의 이름과 소유자의 정체를 감출수 있게 해준다.
2. 리모트에 저장된 패키지를 위하여 위치의 투명성을 제공해 준다.
* 패키지 재컴파일
본체
alter package inventory_pkg compile body;
alter package inventory_pkg compile package;
모든 패키지는 오라클 유틸리티 dbms_utility를 사용하여 재컴파일할 수 있다.
execute dbms_utility,compile_all;
* 패키지 drop하기
drop package body inventory;
drop package inventory;
* 전용패키지 오브젝트와 공용 패키지 오브젝트
패키지 본체 안에서 선언된 오브젝트는 그 패키지 안에서만 사용할 수 있다.
* 패키지 상태
유효 아니면 무효상태이다.
* 오버로딩
오라클은 동일한 패키지에 있는 여러 프로시저가 동일한 이름을 갖는 것을 허용한다
* 패키지 정보 리스팅
all_errors
all_source
dba_errors
dba_object_size
dba_source
user_errors
user_source
user_object_size
트리거(Triggers)
* 트리거란?
결합된 테이블에 대하여 insert, update, delete명령이 발생될때 implicit하게 생행되는 프로시저
트리거는 하나의 단위로서 실행되는 sql과 pl/sql문을 포함할 수 있으며 다른 프로시저와 트리거를 호출할 수 있다.
트리거는 insert, update, delete명령 전후에 호출되며, 제작자는 DML문과 관련하여 언제 실행될 것인지를 지정한다
트리거는 테이블의 뷰나 시노님에서가 아니라 테이블에서 정의되지만 뷰의 베이스 테이블에 있는 그 뷰에 대하여 DML문이 발생될 때도 실행된다
* 트리거 사용 이유
1. 파생 열 값을 자동적으로 생성한다.
2. 보안 허가와 제한을 집행한다.
3. 투명 이벤트 로깅을 제공한다.
4. 테이블 액세스에 대한 통계를 수집한다.
5. 오라클 내부 오디팅 시스템을 보충하는데도 사용할 수 있다.
6. 분산 데이타베이스의 서로 다른 노드에 위치한 복제 테이블을 동기적으로 유지하는 데에도 사용 할 수 있다. 스냅샷에 이런 방식으로 트리거를 사용하는 것이 한 예이다.
* 트리거를 위한 지침
1. 미리 정의된 다른 연산이 실행될 때마다 특정 연산을 수행하고 싶을 때에만 트리거를 사용한다.
2. 트리거링 문을 위하여 실행되어야 할 중앙화된 글로벌 연산을 위하여 트리거를 사용한다.
3. 반복적인 트리거를 만들지 않도록 조심하여야 한다.
4. 코드를 되도록 작게 하기 위하여 트리거를 만드는 것을 삼가야 한다.
5. sql문이 실행될때 프로세스되는 행의 순서에 의존하여 트리거를 만들면 안된다
* 트리거 파트(요소)
1. 트리거 문: 어떤 sql문이 오라클로 하여금 트리거를 지시하게 만드는지 지정한다. 이 트리거문은 insert, update, delete문이 될 수 있다.
2. 트리거 제한: 지시할 트리거를 위하여 참이 되어야 할 조건을 지정. 이 조건은 pl/sql 조건이 아니라 sql조건이어야 한다. 그 조건은 when절에 상주할 수 있다.
3. 트리거 활동: 이것은 트리거가 지시될 때 오라클 싱행하는 pl/sql블록을 지정한다
* 트리거 타입
트리거 활동이 실행되는 횟수를 지정한다.
1. 행 트리거: 트리거 문에 의하여 테이블이 영향을 받을 때마다 실행된다.
예를 들어 update문이 실행되고 30행을 갱신할 경우 이 트리거가 30회 지시된다.
2. 문장 트리거: 트리거 문을 위하여 단 한번 지시된다.
예를 들어 update문이 실행되고 30행을 갱신할 경우 이 트리거는 단 1번 실행된다
* 트리거 타이밍
언제 시작할 지를 지정한다.
before트리거는 트리거링 문 앞에서 실행된다. 다음을 위해 실행된다.
1. insert나 update문의 트리거링을 끝내기 전에 열 값을 끌어내기 위하여
2. 트리거 활동을 실행해야 할 것인지 여부를 결정하기 위하여
after트리거는 트리거 문이 실행된 후 트리거 활동을 실행한다. 다음을 위해 시행됨
1. 트리거 활동 이전에 트리거링 문을 끝내고 싶을때
2. before트리거 활동 외에 추가의논리를 시행하기 위하여
* 트리거 만들기
create trigger 'trigger command'
trigger command: before, after, delete, insert, update, of, on, for each row
when, or replace
create trigger parts_delete
after delete on mst_parts
for each row
when(part_price < 100)
declare
.
.
.
end;
* 트리거 유.무효화 하기
alter trigger t_inv_count disable
* 트리거 실행
sql문은 트리거를 4개까지 실행할 수 있다. 이 4개의 트리거는 before row, after row, before statement, after statement트리거 이다.
* 트리거 변경
트리거를 명시적으로 변경할 수는 없다.
create trigger or replace를 사용하여야 한다.
또는 트리거를 drop했다가 다시 만들어야 한다.
* 트리거 재컴파일하기
기존 트리거의 재컴파일을 집행하려면 alter trigger명령을 사용한다. 트리거는 재컴파일될 때 유효화될 수도 있고 무효화될 수도 있다. alter triggfer명령은 기존 트리거의 정의를 변경하지 않는다.
* 스냅샷 로그 트리거
테이블을 위하여 스냅샷 로그가 만들어질때 오라클은 그 테이블에 after row트리거를 명시적으로 만든다. 그러므로 사용자가 정의한 after row 트리거는 이 동일한 테이블에서는 만들어질 수 없다.
내장 프로시저
* 내장 프로시저(stored procedure)
특정 작업을 수행하는 논리적으로 그룹지어진 sql과 pl/sql문의 셋이다.
선언파트와 실행파트로 구성되어 있다.
* 내장 프로시저 사용 이유
1. pl/sql은 특정 요구에 맞도록 프로시저를 맞출수 있게 해준다.
2. 이 프로시저들은 모듈적이다. 하나의 프로그램을 관리할 수 있는 잘 정의된 유니트로 구성되어 있다.
3. 프로시저들은 데이타베이스에 내장되기 때문에 재사용할 수 있다. 일단 유효화되면, 네트워크를 가로질러 재컴파일하거나 분포하지 않고도 반복해서 사용할 수 있다.
4. 데이타의 보완성을 개선한다.
5. 공유메모리 자원을 활용함으로써 메모리를 개선할 수 있다.
* 내장 프로시저 사용 필요조건
데이터베이스 관리자는 catproc.sql스크립트를 실행할 책임이 있다.
* 내장 프로시저 만들기
create procedure명령은 독립형 프로시저를 만든다.
* create문 에서 사용할 수 있는 파라미터의 리스트
1. in : 호출되는 서브 프로그램에 값을 패스해야 한다고 지정한다.
2. out: 호출하는 프로시저에 값을 리턴한다는 것을 지정한다.
3. inout : 위의 둘다
4. or release : 프로시저가 존재할 경우 다시 만든다.
create procedure user_o1.parts (part_id number, qty number)
as begin
update journal
set journal.qty = journal.qty + qty
where journal_id = part_id;
end;
* return문
프로시저에서 return문은 표현식을 포함할 수 없다.
* 내장프로시저 재컴파일하기
alter procedure로 가능하며, 독립형 내장 프로시저에서만 사용해야 하며 패키지의 일부인 프로시저에서 사용해서는 안된다.
* 내장 프로시저 호출하기
parts_sum(qty, wip_nbr);
execute parts_sum(qty, wip_nbr);
임포트와 익스포트 (Import and Export)
* 임포트, 익스포트를 사용하는 이유
1. 데이터 보관하기
2. 오라클의 새로운 릴리즈로업그레이드하기
3. 오라클 데이터베이스 간에 데이터 이동하기
4. 테이블스페이스 drop하기
5. 데이터베이스 defragment하기
* 익스포트
모드: 테이블 모드, 사용자 모드
테이블 모드
1. 테이블 데이터
2. 테이블 정의
3. 소유자의 테이블 허가
4. 테이블 제한
5. 테이블 트리거
사용자모드: 테이블 모드를 포함하여 다음의 것들
1. 뷰
2. 스냅샷
3. 클러스터
4. 데이타베이스 링크
5. 시퀀스
6. 전용 시노님
7. 공용 시노님
* 익스포트 준비
1. 저장공간 확인
2. 오라클 데이타베이스에 대한 create session시스템 특권이 있어야 한다
* 실행
exp를 타이핑 하고 유틸리티를 구동한다.
* 사용방법 3가지
1. 명령라인에서 그 파라미터 파일의 이름과 함께 exp명령을 입력
exp username/password parfile=filename
2. 명령라인에서 exp명령과 함께 그 뒤에 익스포트의 실행을 콘트롤하는 파리미터를 쓴다.
exp username/password tables=(emp,master_dept) grants=y
3. 명령라인에서 사용자명과 패스워드를 입력한다. (대화형으로 익스포트)
exp username/password
* 익스포트 파라미터
1. buffer : 데이터 행들을 불러오는데 사용되는 버퍼의 크기
정확한 버퍼크기 계산 공식: rows_in_arrary*maximin_row_size
2. file : 출력파일의 이름 초기값은 expdat.dmp
3. grants : 허가를 익스포트 할 것인지를 나타낸다. (y/n) 디폴트는 y
4. indexes : 인덱스도 익스포트할 건가?
5. rows : 테이블로부터 데이터 행을 익스포트 할 건인지..
6. constraints : 제한을 익스포트할 건가?
7. compress: 압축할건가?
8. full : 완전한 풀 익스포트인가?
9. owner: 익스포트할 사용자명. 초기값은 없다.
10. tables: 익스포트할 테이블 이름.
11. recordlength: 출력파일의 바이트 길이
12. inctype : 증분의 타입: complete, cumulative, incremental: 초기값 없음
13. parfile : 파라미터 파일의 이름
14. log : 로그파일의 파일명
15. statistics : 데이터베이스 옵티마이저 통계의 타입 - estimate, compute, none 초기값은 none
16. consistent : 이 파라미터는 익스포트 중에 다른 애플리케이션이 데이터베이스를 갱신하고 있을때 편리하다
* 익스포트 시간을 아낄려면
1. 필요한 테이블만 익스포트한다.
2. 일치된 것으로 남아 있을 필요가 있는 테이블들을 함께 익스포트한다.
* 익스포트 시퀀스
export나 import 중에는 시퀀스 번호를 액세스 하지 않는 것이 좋다.
* 익스포트 온라인 헬프
오라클은 온라인 헬프를 제공한다.
exp help=y
* 임포트 할때 수행 되는 순서
1. 테이블 정의 - 우선 테이블이 만들어 진다.
2. 테이블 데이터 - 새로 만들어진 테이블에 데이터가 로드된다.
3. 테이블 인덱스 - 데이터가 로드된 후 인덱스가 만들어 진다.
4. 통합된 제한과 트리거- 마지막으로 트리거가 임포트 되고 제한이 유효화 된다.
* 스냅샷 익스포트/임포트
스냅샷은 마스터 테이블과 옵션 스냅샷 로그, 마스터 테이블 트리거, 스냅샷 자체
다음과 같은 규칙에 따라서 임포트/익스포트 된다.
1. 마스터 테이블이 이미 존재하고 있을 경우 임포트 데이터는 그 스냅샷로그에 기록된다. 만약 존재하지 않으면 새로운 마스터 테이블이 임포트된다.
2. 오라클은 마스터 테이블이 만들어지고 로드된 후 모든 트리거를 임포트한다
3. 임포트 후에 스냅샷 로그는 비게된다. 그러므로 속성 재생을 시도하기전에 완전한 재생을 실행하여야 한다.
* 내장된 프로시저와 함수 그리고 패키지의 익스포트/임포트
내장된 프로시저와 함수 그리고 패키지가 임포트될 때 그것들은 그 본래의 시간 스탬프를 유지한다.
* 임포트 파라미터
buffer, file, grants, indexes, rows, full, tables, recordlength, inctype, parfile
log, destroy, commit, show(임포트파일과 파일내용 리스트 여부)
* 임포트 유틸리티 실행
1. imp username/password parfile=filename
2. imp username/password tables=(emp, master_dept) grants=y
3. imp username/password
* 임포트 온라인 헬프
imp help=y
SQL*Loader
* SQL*Loader란?
외부 파일로부터 오라클 데이타베이스 테이블에 데이터를 로드하는 오라클 툴이다. 다양한 포맷의 파일을 로드할 수 있고, 필터링도 수행할 수 있다.
복수의 테이블에 로드할 수 있으며 자세한 로그를 남긴다.
* SQL*Loader를 사용하는 이유
1. 서로다른 데이터 타입의 여러 데이터 파일로부터 데이터를 여러 오라클 테이블에 자동으로 로드한다
2. 선별해서 특정 레코드를 로드할 수 있도록 데이터를 필터링한다.
3. 특정 열을 위하여 자동적으로 고유 시퀀스 번호를 생성할 수 있다.
4. 에러 교정등을 제공한다.
5. 데이터를 데이타베이스에 넣기 전에 sql함수와 함께 입력 데이타를 조작할 수 있다.
* SQL*Loader 사용 단계
1. 입력 데이터 소스를 결정한다.
2. 콘트롤 파일을 만든다.
3. 로딩 프로세스를 결정한다
4. 결과를 확증한다.
* 입력 데이타
1. varchar
2. date
3. integer external
4. float external
5. decimal external
6. zoned
7. double
8. graphic
9. raw
10. vargraphic
11. smallint
12. byteint
* 콘트롤 파일이 제공하는 정보
1. 데이터가 로드될 위치(외부 파일 이름이나 실제 데이터 자체)
2. 해당 오라클 테이블 열에 입력 데이터의 매핑. 이때 어떤 데이터를 어떤 테이블의 어떤 열에 넣을것인가 결정
3. 데이터를 로드하기 위한 명세. 특정 테이블 열을 위한 데이터를 필터링하고 포맷하고 만들 논리를 포함
예1)
LOAD DATA
INFILE filename
INSERT
INTO TABLE table_name
(field_name1 POSITION(start:end) CHAR,
field_name2 POSITION(start:end) CHAR)
실예1)
LOAD DATA
INFILE 'DISK1:EMP_DEPT.DAT'
INSERT
INTO TABLE EMP
(EMP_ID SEQUENCE (MAX,1),
F_NAME POSITION(01:35) CHAR,
L_NAME POSITION(36:75) CHAR,
EMP_NBR POSITION(76:85) CHAR,
START_DATE SYSDATE)
INTO TABLE DEPT
WHEN DEPT !=' '
(EMP_NBR POSITION(76:85) CHAR,
DEPT POSITION(86:95) INTEGER EXTERNAL)
* SQL*Loader에서 SQL연산자
insert문의 values절에서 다양한 sql연산자가 사용가능하다.
sql문자열 뒤에 날짜 마스크가 평가된다.
field1 DATE 'mm-dd-yyyy' "RTRIM(:field1)"
job_title필드를 대문자로 변환한다.
job_title POSITION (34:55) CHAR "UPPER(:job_title)"
* SQL*Loader실행
sqlload contro=case1.ctl userid=userid/password
* 인수들
log : 로그 파일이 로딩 프로세스에 대한 정보를 저장하도록 지명
bad : sql*loader가 만든 불량 파일이 로딩 중에 야기된 레코드를 저장하도록 지명
discard : sql*loader가 만든 옵션 로그 폐기파일이 테이블에 삽입되었지만 에러를 포함하지 않은 레코드를 저장하도록 지명
discardmax : 로드를 종결하기 전에 허용된 discard레코드의 수를 지정
errors : 로드를 종결하기 전에 허용된 삽입 에러의 수를 지정
skip : 로드되어서는 안될 파일의 처음부터 논리적 레코드의 수를 지정
rows : 바인드 배열에 있는 행의 수를 지정한다.
* SQL*Loader출력파일
1. 로그파일
2. 실패 레코드 파일(bad record file)
3. 폐기 파일(discard file)
SQL*DBA
* SQL*DBA란? 사용 이유는?
오라클 데이타베이스의 운영을 효과적이고 효율적으로 관리할 수 있게 해주는 유틸리티
사용이유
1. 데이터베이스 인스턴스를 기동하고 중지함
2. 데이터베이스를 위한 새로운 사용자를 만듬
3. sql과 pl/sql문을 실행
4. 데이터베이스 퍼포먼스 통계를 모니터링
* 인터페이스
메뉴중심 대화형 모드
sqldba mode=screen
대화형 라인모드
sqldba mode=line
* sql*dba 명령들
1. archive log : 온라인 redo로그파일의 보관을 기동하고 중지함
파라미터: list, start, stop, netx, all, to
archive log parameter
2. connect : 지정된 사용자명을 사용하여 데이타베이스에 접근
connect username/password instance/database
3. describe : 테이블이나 내장프로시저, 또는 함수를 기술
4. disconnect : 사용자의 접속을 끊는다
5. execute : pl/sql문을 실행한다.
excute PL/SQL statement
6. exit : 무조건 현재 sql*dba세션을 떠난다.
7. host : 호스트의 명령을 사용한다.
8. print : 변수값을 프린트 한다.
9. recover : 하나 이상의 테이블스페이스나 데이터베이스파일, 또는 전체 데이터베이스에서 미디어 복구를 수행한다.
파라미터: database:테이터베이스 전체 복구(until time절 사용가능)
tablespace tablespace_name : 복구할 테이블 스페이스를 지정
datafile : 복구할 데이터 파일의 이름을 지정
10. remark : 스크립트 파일에 코멘트를 만드는데 사용
11. set : sql*dba세션의 특징을 설명하거나 변경
12. shutdown : 실행중인 오라클 인스턴스를 셧다운 시킨다.
파라미터:
abort: 가능한 가장 빠른 방법으로 셧다운과 함께 처리된다.이것은 인스턴스를 셧다운하지만 트랜잭션의 완료를 기다리지 않는다. 또한 데이터베이스를 닫거나 디스마운트한다.
immediate: 현재 호출이 완료되기를 기다리지 않고 데이터베이스를 닫고 디스마운트한다.
normal: 모든 호출이 완료되기를 기다리고 정상적인 방법으로 그 인스턴스를 닫느다.
13. spool : 모든 출력이 지정된 파일에 이코되게 만든다.
14. startup : 오라클 인스턴스를 기동한다.
파라미터:
exclusive : 그 데이터베이스가 현재 인스턴스에 의해서만 마운트되고 열릴수 있음을 의미
force : 현재 실행중인 인스턴스가 있을 경우엔 그 인스턴스를 재기동하기 전에 폐기(abort)옵션을 사용하여 현재 인스턴스를 셧다운 시킨다.
mount : 데이터베이스를 마운트하지만 열지는 않는다
15. variable : 현재 세션에서 사용할 바인드 변수를 선언한다.
데이터베이스 사용자 관리하기
* 사용자 만들기
사용자를 만들때 지정해야 할 것들
1. 사용자명
2. 초기값 테이블 스페이스
3. 임시 세그먼트 테이블 스페이스
4. 테이블스페이스 쿼터
5. 프로파일
create user user_01
identified by D82KLW9
default tablespace ts_101
temporary tablespace ts_temp
quota 5m on ts_101
quota 5m on ts_temp
quota 3m system
profile clerk;
이렇게 만들어진 사용자일지라도 connect 권한이 주어지지 않으면 데이타베이스에 연결할 수 없다.
암호 바꾸기
alter user tom_01
identified by 2JAW3HZ;
* 사용자 자원 관리하기
create profile을 통하여 사용자 자원을 관리하게된다.
프로파일을 만들때 다음의 자원 제한을 명시적으로 설정한다.
1. session_per_user : 사용자를 위한 동시발생 수를 제한
2. cpu_per_session : 하나의 세션을 위한 CPU시간 1/100 단위
3. cpu_per_call : 하나의 호출을 위한 cpu시간을 제한
4. connect_time : 한 세션의 총 소요시간을 제한
5. idle_time : 비 활성 최대 지속시간을 정의
6. logical_read_per_session : 한 세션에서 읽어들이는 데이터블록의 수를 제한
7. logical_reads_per_session : sql문을 처리하기 위한 호출에서 읽어들이는 데이터 블록수 제한
8. private_sga : 하나의 세션이 시스템 글로벌 구역에 예비할 수 있는 전용 스페이스의 양을 제한
9. composite_limit : 세션당 총 자원 코스트를 제한 이것은 sessions_per_user, connect_time, logical_reads_per_session, private_sga등을 제한한다. 이들 자원과 결합된 코스트를 정의하려면 sql명령 alter resource cost를 사용한다.
* 프로파일 만들기 예
create profile clerk limit
sessions_per_user 1
connect_time 560
cpu_per_call unlimited
idle_time 15;
alter문을 통하여 변경도 간능하다.
* 사용자 관리를 위한 데이터사전 뷰
포함되는 정보들
1. 데이터벵이스에 있는 사용자들의 리스트
2. 테이블과 크러스터, 그리고 인덱스를 위한 각 사용자의 초기 테이블스페이스
3. 각 현재 세션을 위한 메모리 사용
4. 임시 세그먼트를 위한 각 사용자의 테이블스페이스
5. 각 사용자를 위한 스페이스 쿼터
6. 각 사용자에 대입된 프로파일과 자원 제한
7. 각 애플리케이션 시스템 자원에 할당된 코스트
데이터사전뷰
all_users
user_users
dba_user
user_ts_quotas
dba_ts_quotas
user_resource_limits
dba_profiles
resource_cost
* 라이센싱
license_max_sessions
license_max_warning
license_max_users
데이터사전 뷰
v$license
select sessions_max s_max,
session_warning s_warn,
session_current s_curr,
session_highwater s_high,
users_max u_max
from v$license;
롤(Roles)
* 롤(Roles)이란?
롤은 개별 사용자나 다른 롤에 주어진 관련 권한 지명 그룹이다.
* 롤을 사용하는 이유
1. 단순한 특권관리
2. 개별적 동적 특권관리
롤의 특권이 수정될때 이 변경은 자동적으로 그 롤이 주어진 사용자에게 주어진다.
3. 애플리케이션이 지정하는 보안
* 롤 만들기
create role clerk
identified by Y8DS20J;
* 시스템이 정의하는 롤
오라클은 다섯개의 미리 정의된 롤을 오라클 서버에 제공한다
1. connect: alter session, create cluster, create database link,
create sequence, create session, create synonym, create table,
create view
2. Resource: create cluster, create procedure, create sequence,
create table, create trigger
3. DBA: admin옵션과 함께 모든 시스템 특권
4. Exp_full_database : 테이블 SYS.INCVID와 SYS.INCFIL그리고
SYS.INCEXP에서 select any table, back up_any_table, insert, delete, update
5. Imp_full_database : become user, writedown(Trusted 오라클 서버에서만)
* 롤 변경하기
롤을 유효화하는데 필요한 암호, 롤이 유효화될 때 그 롤을 확인할 것인지 여부.
alter role clerk identified by JL10C3Q
* 사용자의 롤 바꾸기
alter user tom_01
default role all except dba;
* 롤 drop
drop role clerk;
롤 부여하기
grant manager to NT9K3BH with admin option;
-> admin옵션을 가진 사용자 NT9K3BH에게 롤 manager를 부여한다.
* 롤 취소하기
revoke clerk from tom_01;
* 운영체계 허가와 취소
세션이 만들어질때 데이터베이스가 운영체계를 이용하여 사용자의 역할을 관리하려면 초기화변수 os_roles를 True로 설정하고 그 인스턴스를 재기동 하여야 한다.
특권(Privileges)
* 특권(Privileges)이란?
활동을 실행하거나 다른 사용자의 오브젝트에 액세스하는 것을 허가하는 것
특권엔 시스템 특권과 오브젝트 특권의 두가지.
시스템특권은 사용자가 일정한 타입의 오브젝트에서 활동을 수행할 수 있게 해주는반면 오브젝트 특권은 사용자가 특정 오브젝트에서 활동을 수행하도록 허가한다
* 특권 사용 이유
데이터베이스 보안의 가장 기초적인 통제 가운데 하나.
특권은 데이터베이스 관리자로 하여금 적당한 레벨의 보안을 데이터베이스 오브젝트와 사용자에게 할당할 수 있게 해준다.
* 특권을 사용하는 법
1. 시스템 특권
80여가지가 있다.
분석(모든 테이블, 인덱스 또는 클러스터)
. analyze any
오디트(데이터베이스에 있는 모든 스키마)
. audit any
. audit system
클러스터
. create cluster
. create any cluster
. alter any cluster
. drop any cluster
데이터베이스
. alter database
데이터베이스 링크
. create database link
인덱스
. create any index
. alter any index
. drop any index
기타 등등
* 시스템 특권 허가하기
grant create session to kabin, finance;
위 문장은 시스템 특권을 사용자 kabin과 finance롤에게 준다
* 시스템 특권 취소하기
revoke all from robert_c
* 오브젝트 특권
오브젝트 특권은 테이블이나 패키지 또는 뷰와 같은 특정 오브젝트에서 활동을 수행할 수 있는 허가이다.
* Public 사용자 그룹
사용자 그룹 public에 부여된 모든 롤은 모든 데이터베이스 사용자가 액세스할 수 있다.
* 특권정보 리스트
all_col_privs
user_col_privs
dba_col_privs
dba_sys_privs
all_col_privs_made
all_col_privs_recd
all_tab_privs
all_tab_privs_made
all_tab_privs_recd
user_role_privs
user_sys_privs
column_privileges
session_privs
데이터베이스 오디팅하기
* 데이터베이스 오디팅(auditing)이란?
선택된 데이터베이스 사용자의 활동을 감시하는 프로세스
일반적으로 세타입의 데이터베이스활동에서 수행된다.
1. 문장
2. 오브젝트
3. 특권
오디팅은 오디팅된 오퍼레이션, 그 운영을 수행하는 사용자, 그 운영 일시, 그리고 그 운영의 성패 표시와 같은 정보들을 기록한다. 이 정보는 오라클 오디트 트레일 테이블이나 운영체계 오디트 파일에 저장된다.
* 데이터베이스를 오디트 하는 이유는?
1. 데이터베이스 자원과 활동에 대한 데이터와 통계를 수집하기 위하여(IO현황,동시발생 사용자의 수등)
2. 의문스러운 활동이나 사용자를 감시하기 위해.
* 오디트 할때 주의사항
오라클의 오디트 기능과 운영체계의 오디트 기능을 사용한다.
오라클이 오디트 기능을 수행하면 테이블에 오디트 정보들이 저장된다.
오디트 할때는 일반적인 오디트 기능을 일단 설정해 차츰 필요한 부분을 추가한다
* 문장과 오브젝트 그리고 특권의 오디팅
문장 오디팅은 관련된 특정 문장 그룹을 오디팅한다. 문장 오디팅은 일반적으로 범위가 넓으며, 모든 사용자 또는 선택된 사용자 그룹의 활동을 오디트한다. 특권 오디팅은 선택된 시스템 특권과 그와 결합된 문장을 오디트 하는 것이다. 예를 들어 create user시스템 특권을 오디트하는 것은 이 특권의 실행을 요구하는 모든 사용자의 문장을 오디트한다.
* 오디트 구성하기
오디트 내용은 다음을 포함한다.
1. 오디트된 문장을 실행된 사람의 사용자명
2. 사용자에 의하여 실행된 오디트된 문장을 나타내는 활동코드
3. 오디트된 문장에서 참조된 오브젝트(들)
4. 오디트된 문장이 실행된 일시
* 오디트 3가지 타입
1. 문장: sql문의 타입에 기초하여 오디트
2. 특권: 특정 시스템 특권을 오디트
3. 오브젝트: 특정 오브젝트에 있는 특정 문장을 오디트
* 문장 오디트 옵션
alter, cluster, database link, index, not exists, procedure, public database link, public synonym, role, rollback, sequence, sesstion, synonym, system audit, system grant, table, tablespace, trigger, user, view
* 예
사용자 kabin을 위한 모든 접속활동의 오디트를 지정하려면..
audit session
by kabin;
* 오디트 옵션 키워드
1. connect : session
2. resource : alter system, cluster, database link, procedure, rollback segment, sequence, synonym, table, tablespace, view 포함
3. dba : system audit, public database link, public synonym, role, system, grant, user
4. all 1,2,3의 모든 옵션
예) audit dba kabin
* 최종 오디트 옵션
alter sequence, alter table, comment table, delete table, execute procedure, grant procedure, grant sequence, grant table, insert table, lock table, select sequence, select table, update table
* 오브젝트 오디트 옵션
alter, audit, comment, delete, execute, grant, index, insert, lock, rename, select update
* 특권 오디트 옵션
audit alter user
by access;
* 오디트 유효화 하기와 무효화하기
예) audit role whenever successful;
-> 성공적인 role문만 오디트 한다. 그러나 실제로 오디트 레코드를 생성하지는 않는다
데이타베이스 오디팅은 데이터베이스의 파라미터 파일에 있는 audit_trail 초기화
파라미터에 의하여 유효화되고 무효화 된다.
audit_trail파라미터
1. db : 데이타베이스 오디팅을 유효화 하고 모든 오디트 레코드를 데이터베이스 오디트 트레일로 보낸다
2. os : 데이타베이스 오디팅을 유효화 하고 모든 오디트 레코드를 운영체계 오디트 트레일로 보낸다.
3. none : 오디팅을 무효화한다.
파라미터
1. by session : 동일한 세션에서 발행된 동일한 타입의 모든 sql문을 위하여 그 오디트가 하나의 레코드를 쓰도록 만든다
2. by access : 오라클이 오디트된 각 문장을 위하여 하나의 레코드를 쓰게한다.
3. whenever successful : 성공적으로 완료되는 sql문을 위해서만 오디팅을 선택한다
4. whenever not successful : 실패하거나 에러로 결과되는 sql문을 위해서만 오디팅을 선택한다.
* 오디트 트레일 뷰
stmt_audit_option_map, audit_actions, all_def_audit_opts, dba_stmt_audit_opts
dba_priv_audit_opts, dba_obj_audit_opts, user_obj_audit_opts, user_audit_trail
user_audit_session, user_audit_statement, user_audit_object
* 오디트 트레일 관리 지침
1. 절대적으로 필요한 오디트 옵션만 켠다.
2. 필요에 따라서 데이터베이스를 유효화하거나 무효화한다.
3. 오브젝트 오디팅을 제한한다. 왜냐하면 문장 오디팅보다 더 많은 정보를 생성하기 쉽기 때문이다. 그럴려면 audit any시스템 특권을 소유하는 사람을 제한해야 한다.
* 모든 레코드의 오디트 트레일을 없애려면?
1. delete from sys.aud$;
2. delete from sys.aud$
where obj$name='mst_parts';
* 트리거를 이용하여 오디트하기
trigger를 이용한 오디트는 DML문장만을 다룬다. 대신 훨씬 자세한 정보를 제공할 수 있다. 트리거를 사용하여 추가의 오디팅 정보를 생성할 때에는 after트리거를 사용하여야 한다.
after트리거를 사용함으로써 무결성 제한 때문에 실패하는 문장의 불필요한 오디팅을 피할 수 있다.
백업과 복구 (Backup and Recovery)
* 백업과 복구의 구조를 위한 정의
1. 프로세스 실패: 사용자, 서버, 또는 백그라운드 프로세스에 있어서의 실패 이 예로는 비정상적인 접속단절이 있다.
2. 네트워크 실패: 네트워크 컴포넌트에 있어서의 실패
3. 인스턴스 실패: 하드웨어 실패나 운영체계 문제의 결과로서 인스턴스 실패
4. 미디어 실패: 일기/쓰기 시도의 실패로 인한 실패
5. 리두로그(redo log): 이것은 오라클 데이터베이스에서 이루어진 모든 변경을 기록
6. 롤백 세그먼트: 현재 트랜잭션에 의하여 변경된 데이터의 변경된 값이나 이전 값을 저장한다.
* 백업을 위한 지침
1. 적당한 백업 프로시저를 계획하고 구현
2. 백업을 테스트 할 것.
3. 정기적으로 백업을 수행할것
4. restore중에 데이터베이스를 보호할것
5. 테이블스페이스를 백업할 것.
6. 백업을 유지할 것
7. 분산 데이타베이스를 보호할것. 분산데이타베이스는 동일한 백업 계획의 일부가 되어야 한다. 데이터베이스가 noarchivelog모드에서 운영되는 경우에는 동시에 백업이 수행되어야 한다.. 보관 모드가 유효화될 경우에는 동기화할 필요가 없다.
* 백업의 종류
오라클은 두 종류의 백업을 제공한다.
부분 백업과 완전백업
* 백업 모드
아카이브 모드 : 데이터베이스 실패의 마지막 순간까지 완전한 백업이 이루어지도록 보장한다. 이것은 온라인 리두 로그를 다른 테이프나 디스크 드라이브에 보관함으로써 이루어진다.
온라인이나 오프라인 백업을 이용하여 특정 시점에 완전복구를 할 수 있게 해준다. 데이터를 잃어버리면 안되는 중요한 애플리케이션을 실행하고 있는 고객을 위해서는 이 모드를 추천한다.
노아카이브 모드: 온라인 리두 로그를 보관하지 않는다.
이 타입의 백업은 미디어 실패가 아니라 인스턴스 실패로부터 보호해 준다.
* 백업 수행하기
어떤 백업도 수행하기 전에 백업할 파일의 리스트를 만든다.
v$logfile 뷰는 온라인 리두 로그 파일의 리스팅을 포함한다.
데이터 베이스의 현재 콘토롤 파일의 리스트를 얻기
show parameter control_file
* 완전 백업 프로세스
1. 정상적인 우선 순위에 의하여 데이터베이스를 셧다운 시킨다
2. 데이ㅌ터베이스에 의하여 사용된 모든 파일의 백업을 수행한다.
3. 데이터베이스를 재기동한다.
* 콘트롤 파일의 백업
alter database backup controlfile cf_user_01 reuse;
* 복구를 위한 지침
1. 복구 프로시저를 테스트 할것
2. 올바른 복구 방안을 마련한다.
* 버퍼와, 리두 로그, 롤백 세그먼트
리두 로그로 롤하려면 alter database명령을 쓴다. 다음은 arch0021이라는 redo log로 롤한다.
alter database
recover logfile 'tape_3:arch0021.arc';
redo log는 그 변경이 commit 되었는지 여부에 관계없이 인덱스와 데이터 그리고 롤백 세그먼트를 포함하여 그 데이터베이스에 가해진 모든 변경을 기록하는 일련의 운영체계 파일이다.
* 완전 복구 프로세스
1. abort절과 함께 shutdown
2. 데이터베이스의 모든 데이터파일과 온라인 리두 로그파일 그리고 파라미터 파일을 복구한다.
3. 복구된 파라미터 파일을, 만약 가능하다면 새로운 디스크의 위치를 반영하도록 편집한다.
4. 복구되고 편집된 파라미터 파일을 사용하여 그 인스턴스를 재기동한다.
5. 데이터베이스를 마운트한다.
6. 복구된 데이터파일과 온라인 리두로그 파일의 새로운 위치를 기록한다.
7. 데이터베이스를 다시 연다.
* 부분복구
특정 데이터베이스 복구 중에 부분적 파일 복구가 필요할 수도 있다. 복구할 필요가 있는 파일을 디스플레이하려면 v$recover_file 파일을 사용한다.
다음의 문장은 개별 파일을 복구하는데 필요한 정보를 생성한다.
select file#, online, error
from v$recover_file;
* 인스턴스 복구
인스턴스 복구 프로세스는 그 데이터베이스를 인스턴스 실패 바로 전의 트랜잭션 일치 상태로 복구한다. 인스턴스 복구는 다음과 같이 이루어진다.
1.데이터파일에 아직 저장되지 않은 데이터를 복구하기 위하여 리두로그를 롤하기. 이것은 alter database명령을 recover절과 함께 사용하면 된다.
2. 커미트되지 않은 트랜잭션을 롤백 세그먼트가 지정한 대로 롤백하기. sql롤백 명령은 커미트 되지 않은 트랜잭션을 롤백한다.
3. DDL테이블 락과 같은 모든 자원 락을 풀어주기. 트랜잭션이 커미트 되거나 롤백될 때까지 락은 제 위치에 남는다.
4. 유예된 분포 트랜잭션으로부터 양면 커미트를 해결하기. 양면 커미트는 커미트나 롤백이 실행될 때 분산 데이터베이스의 모든 노드에서 트랜잭션이 유효화되도록 보장한다.
SQL문 튜닝하기
* SQL 문을 튜닝하는 이유
1. 오라클 데이타베이스 애플리케이션의 퍼포먼드를 개선한다.
2. 특정 SQL문의 퍼포먼스를 개선한다.
3. 오라클 내부에서 메모리 할당을 개선한다.
4. 사용자 회선과 디스크 I/O를 감소시킨다.
* SQL문 튜닝
인덱스, 클러스터, 해시 클러스터, 힌트 등을 사용한다.
* 인덱스 사용하기
1. where절에서 자주 사용되는 열을 인덱스한다.
2. sql문에서 테이블을 연결하기 위하여 자주 사용되는 열을 인덱스한다.
3. 그 행의 값이 크게 다를 경우 인덱스를 위한 열로 선택한다.
4. 행의 값이 자주 바뀌는 열은 인덱스 하지 말아야 한다. 이런 열을 인덱스하면 갱신과 삽입프로세스의 속도가 떨어질 것이다.
5. where절이 함수를 참조할 경우 그 where절의 열은 인덱스 하면 안된다.
6. 참조 무결성 제한의 외부 키를 구성하는 열에서 인덱스를 사용한다
7. 둘 이상의 열로 구성된 복합 인덱스의 사용을 고려해 본다.
* 복합 인덱스의 사용을 고려할때 참작해야 할 것
1. where절에서 함께 사용된 열에 대하여 복합 인덱스를 사용한다.
2. 여러 쿼리가 하나 이상의 열 값의 특정 값에 기초항여 동일한 열 세트를 선택할 경우 이 열들에 대하여 복합 인덱스를 만든다.
3. create index문에서의 선택도에 따라 열들을 정렬한다. 선택도가 높은 열을 처음, 그리고, 선택도가 낮은 것을 뒤에 나타나게 한다.
* 인덱스 피하기
널 값을 인덱스 문자열에 연결하여 where조건을 건다.
select *
from employee
where emp_dept || '' = 'ABCDEFG';
* 클러스터 사용하기
1. join문에서 자주 액세스되는 클러스터된 테이블을 사용한다. 만약 그 연결이 자주 사용되지 않으면 그 테이블들을 클러스터하면 안된다.
2. 클러스터된 테이블 가운데 한 테이블에서만 완전한 테이블 스캔이 수행되면 테이블들을 클러스터하지 말아야 한다.
3. 클러스터된 테이블에 있는 데이터의 크기가 오라클 데이터 블록 둘 보다 크면 테이블들을 클러스터하지 말아야 한다.
* 해시 클러스터 사용하기
해시 클러스터를 위한 행 검색이 해시 함수에 따른다.
1. 동일한 열이나 열의 조합을 사용하는 상등 조건을 포함하는 where절에 의하여 자주 액세스되는 테이블을 위하여 해시 클러스터를 사용한다.
2. 클러스터 키 값의 모든 행을 수용하는데 필요한 스페이스를 경정할 수 있을 경우 해시 클러스터를 사용한다.
3. 데이터베이스 스토리지를 낮게 실행하고 있다면 해시 클러스터를 사용하지 말아야 한다.
4. 테이블이 계속 커가고 있고 보다 큰 새로운 해시 클러스터를 만드는 것이 실용적이지 못할 경우에는 해시 클러스터링을 이용해서는 안된다.
5. 해시 클러스터 키 값이 자주 수정될 경우에는 해시 클러스터를 사용해서는 안된다.
* 힌트 사용하기
1. sql문을 위한 최적화 어프로치
2. sql문을 위한 코스트 중심 어프로치의 목표
3. 테이블을 위한 액세스 경로
4. join문을 위한 연결 순서
5. join문에서 연결 오퍼레이션
오라클은 코스트 중심 어프로치를 사용할 때에만 힌트를 인식한다.
* 여러가지 힌트들
all_row : 최대 처리량을 위하여 sql을 최적화한다.
end_qual : 지정된 테이블에서 인덱스 머지를 이용한다.
cluster : 지정된 테이블에서 클러스터 스캔을 이용한다.
cost : 코스트 중심 옵티마이저를 이용한다.
first_row : 최선의 응답시간을 위하여 sql을 최적화한다.
이 힌트는 옵티마이저가 다음의 선택을 하도록 만든다.
1. 가능하다면, 완전한 테이블 스캔보다 인덱스 스캔을 이용한다.
2. 인덱스 스캔이 가능하다면 소트-머지 연결 전에 내장 루프가 사용된다
3. order by절에 의하여 인덱스 스캔이 가능하다면, 그 옵티마이저는 언제나 소트 작업을 피하도록 선택한다.
4. 이 힌트는 group by, for update, distinct, set operators중 어떤 것이건 포함하는 delete와 update문을 위해서는 무시된다. 모든 행이 이 문장들을 위하여 검색되어야 하기 때문에 이 문장들은 최적화 할 수 없다.
full : 지정된 테이블에서 완전한 테이블 스캔을 이용한다.
hash : 지정된 테이블에서 해시 탐색을 이용한다.
index : 지정된 테이블에서 지정된 스캔을 이용한다.
index_asc : 지정된 테이블에서 지정된 인덱스 스캔을 오름차순으로 이용한다.
index_desc : 지정된 테이블에서 지정된 인덱스 스캔을 내림차순으로 이용한다.
ordered : from절 join순서를 이용한다. join문에서 ordered절을 생략할 경우 오라클이 그 열들의 순서를 결정한다.
rowid : rowid액세스 방법을 사용한다.
rule : 규칙 중심 최적화를 한다. 이것은 또한 옵티마이저가 이 문장 블록에 나타나는 다른 힌트는 무시하도록 한다.
user_merge : 지정된 테이블에서 소트-머지 테크닉을 사용한다.
use_nl : 지정된 테이블에서 내장 루프 연결 테크닉을 사용한다.
* TKPROF유틸리티
tkprof은 트레이스 파일을 읽을 수 있는 포맷으로 번역하는데 이용된다.
* 트레이스 파일에 들어 있는 정보
1. 파싱과 불러오기, 실행의 횟수
2. cpu와 소요시간
3. 물리적 시간과 논리적 시간
4. 프로세스된 행의 수
5. 라이브러리 캐시에서 누락의 수
tkprof infile outfile
tkprof명령 라인에 sort, print, explain절을 포함시킬 수 있다. sort절은 트레이스된 sql문들을 지정된 소트 옵션에 따라서 내림차수으로 소트한다.
print절은 지정된 수의 sqlㅁ누들만 출력 파일에 리스트한다. 여러분은 이것을 이용하여 가장 퍼포먼스가 좋지 않은 문장들에의 출력의 양을 제한하고 싶을지도 모른다. 때로는 이 파일이 다소 커질 때가 있다.
explain절은 tkprof로 하여금 explain plan명령을 실행하도록 지시하는데 상용된다 explain plan출력은 tkprof통계가 프린트된 직후 디스플렝이된다.
다음의 지침은 tkprof유틸리티로부터 생성된 통계를 이용하는데 도움이 될 수 있을 것이다.
1. 논리적 I/O의 수가 리턴된 행의 크기보다 훨씬 크면 문장이 그 인덱스를 이용할 수 있도록 만드는 것을 고려해 본다.
2. 수행된 불러오기의 수가 검색된 행의 수와 같으면 배열 인터페이스의 사용을 고려해 본다.
3. 문장이 실행되는 만큼 자주 파싱되면 라이브러리 캐시가 퍼포먼스를 개선 할 수도 있다.
4. 물리적 I/O의 수가 논리적 I/O의 수와 가까우면 보다 큰 데이타베이스 버퍼 캐시가 퍼포먼스를 개선할 수도 있다.
* 이산트랜잭션(Discrete Transactions)
begin_discrete_transaction프로시저를 사용하여 여러분의 짧은 비분포 SQL문의 퍼포먼스를 개선할 수 있다. 이 프로시저는 트랜잭션 프로세싱을 간소화해짐으로 짧은 트랜잭션이 보다 빨리 실행될 수 있다.
* 트랜잭션이 사용될 수 있는 조건들.
1. 소수의 데이터베이스 블록만 수정한다.
2. 트랜잭션마다 개별 데이터베이스 블록을 한 번 이상 변경하는 일이 거의 없다
3. 오래 끄는 쿼리에 필요할 것 같은 데이터를 수정하지 않는다
4. 데이터를 수정한 후에 그 데이터의 새로운 값을 볼 필요가 없다.
5. 긴 값을 포함하는 테이블을 수정하지 않는다.
* 이산 트랜잭션의 특징
1. 모든 데이터에 가해진 변경은 트랜잭션이 커미트될 때까지 연기된다.
2. 리두 정보가 생성되지만 메모리에서 별도의 위치에 저장된다.
3. 언두 정보는 생성되지 않는다.
4. 트랜잭션은 그 자체의 변경을 알 수 없다.
5. 행들은 이산 트랜잭션이 지속되는 동안 select/for update문을 사용하여 락을 걸 수 있다.
6. discrete transaction중에 만나는 모든 에러는 discrete_transaction_failed 예외가 제기되게 만든다.
다음의 예는 이산트랜잭션 프로시저의 용례이다.
declare begin begin_discrete_transaction; exit; exception when discrete_transaction_failed then rollback; end; end;
* SQL*DBA로부터의 통계
SQL*DBA에서 모니터 기능을 이용하면 다음의 sql튜닝 통계를 디스플레이할 수 있다
모니터 명령을 위한 구문은 다음과 같다.
monitor keyword
예를 들어 디스크 소트의 수를 모니터 할때
monitor sorts(disk);
파라메터
cluster key scans
cluster key scan block gets
table fetch by rowid
table fetch continued row
table scan rows gotten
table scan blocks gotten
table scans(긴 테이블)
table scans(짧은 테이블)
parse count
parse time CPU
parse time elapsed
sorts(디스크)
sorts(행)
sorts(메모리)
어플리케이션 튜닝하기
* 어플리케이션 튜닝이란?
코드의 각 라인, 오라클 서버와의 인터페이스, 어플리케이션이 실행되는 환경 튜닝
* 어플리케이션 튜닝하는 이유?
오라클 어플리케이션과 sql문, 그리고 pl/sql블록의 퍼포먼스를 개선한다는 최종목표
* PL/SQL 튜닝하기
* 프로시저 코드를 어플리케이션에 넣어야 할때
1. 입력 필드로부터의 값을 유효화 하고자 할때
2. 단 하나의 유일한 어플리케이션에 지정된 활동을 수행하고 있을때
3. 에러처리 루틴을 커스터마이즈해야 할때
* 프로시저 코드를 서버에 넣어야 할때
1. 코드가 트랜잭션에서 여러테이블을 갱신한다.
2. 여러 어플리케이션이 프로시저 코드를 공유한다.
3. 참조 무결성 제한을 보장하는데 그 코드가 사용된다.
4. 그 코드가 테이블의 갱신이나 삽입 또는 삭제시에 발생하도록 활동을 지정한다
* 프리컴파일러 프로그램의 퍼포먼스의 질을 떨어뜨리는 많은 요인
1. 클라이언트 프로그램과 오라클 사이에 광범위한 호출. 이것은 특히 그 호출이 네트웍을 가로질러 이루어질 때 그렇다
2. 비효율적인 sql문은 인덱스와 같은 데이터베이스 자원을 활용하지 않는다.
3. 내장 sql문의 불필요한 재파싱과 재바인딩
* 커서의 관리에 도움을 주는 프리컴파일러 옵션
1. maxopencursors :프리컴파일러가 캐시해 두려고 하는 열린 커서의 최대수를 지정
2. hold_cursor : 프로그램 커서와 커서 캐시 간에 링크를 유지해야 할 것인지 여부지정
3. release_cursor : 캐시 엔트리와 콘텍스트 구역 간에 링크를 유지해야 할 것인지 여부를 지정
PL/SQL코드를 되도록이면 SQL코드가 아니라 애플리케이션에서 사용하려고 해야 한다.
이것은 어플리케이션이 PL/SQL의 블록 성격을 활용하도록 만든다. 내장 블록은 전체가 한꺼번에 네트워크를 통하여 오라클 서버로 보내어진다. 이것은 네트워크를 통하여 개별적으로 보내지는 각 SQL문과는 대조가 된다.
* 배열
가능하면 배열 프로세싱을 실현하라. 배열 프로세싱은 어플리케이션으로부터 오라클의 호출 수를 줄임으로써 퍼포먼스를 개선할 수 있다.
* 배열의 잇점을 활용할 수 있는 어플리케이션의 전형적인 타입
1. 고도의 퍼포먼스가 필수적인, 많은 행을 프로세스하는 모든 배치형 시스템
2. 한 번에 많은 레코드의 삽입과 갱신을 수행하는 모든 어플리케이션
3. 네트워크를 통하여 많은 양의 데이터를 이동시키는 클라이언트/서버 어플리케이션
4. 둘 이상의 레코드를 프로세스해야 하는 모든 SQL문 일반적으로 오라클 툴들은 자동적으로 배열을 사용한다.
다음은 배열의 크기를 조절하는 명령이다.
set arraysize 200
* 메모리 할당 튜닝하기
메모리의 적절한 할당의 잇점
1. 캐시 퍼포먼스가 개선된다.
2. SQL문과 PL/SQL블록의 파싱이 감소한다.
3. 페이징과 스왑핑이 감소
* 메모리 할당 튜닝에 포함되는 단계들
1. 운영체계를 튜닝한다.
2. 전용 SQL과 PL/SQL구역을 튜닝한다. 불필요한 파스 호출을 식별하거나 가능 하다면 그 수를 줄인다. TJPROF 유틸리티는 파스호출의 수를 식별하는데 도움이 될 수 있다.
3. 공유 풀을 튜닝한다. v$librarycache테이블에 리스트된 라이브러리 캐시 미스의 수를 평가 하는 일부터 시작한다. 미스는 실행단계에서 라이브러리 캐시 미스의 수를 나타냄
실행된 단계의 수에 대한 미스의 비율은 1%미만이어야 함.
select * from emp;
select * from Emp;
이렇게 대소문자를 다르게 하면 공유풀을 쓰지 않게 된다.
4. 버퍼캐시를 튜닝한다.
버퍼캐시 히트율을 결정하려면 v$sysstat테이블에서 select를 수행하여 버퍼의 데이터베이스 블록 gets과 일치gets, 그리고 물리적read의 수를 얻는다.
hit ratio=1-(physical reads/(database block gets + consistent gets))
만약 이 비율이 75% 미만이라면 문제가 있는 것이다. 이때 캐시에서 버퍼의 수를 늘린다.
* I/O 튜닝하기
1. 디스크 경쟁을 줄인다
2. 데이터 블록을 위하여 적당한 스페이스를 할당한다.
3. 동적 스페이스 할당을 삼가한다.
v$datefile테이블은 그 특정 데이타베이스 파일을 위한 물리적인 읽기와 쓰기에 대한 정보를 제공한다. 현재 초당 40이상의 액세스로 실행하고 있다면 그 디스크는 과용되고 있는 것이다.
* 디스크 경쟁은 주로 롤백 세그먼트와 MTS서버에서 잘 일어난다.
* 롤백 세그먼트 경쟁
롤백 세그먼트는 액세스 대기의 수가 전체 데이터베이스 액세스 수의 1%를 넘으면 문제를 갖게 된다. 다음은 그 데이터베이스를 위한 대기수를 디스플리이한다.
select class, count from v$waitstat;
* 만약 멀티 쓰레드형 서버 디스패처가 50%이상의 시간 동안 바쁘다면 새로운 디스패처를 추가해야 한다.
select network, busy
from v$dispatcher;
* 공유 서버 프로세스를 얻는데 필요한 평균 대기시간
select (wait/totalq) "Average Wait Time"
from v$queue
where type = 'COMMON';
* 공유 서버의 수 출력
select count(*) 'NBR of shared servers"
from v$shared-servers
where status !='QUIT;
MTS와 LOCK그리고 링크
* lock의 종류
데이터 lock
DML lock이라고도 하며, 테이블 데이터를 보호하고 데이터 무결성을 보장하는데 사용
사전 lock
데이터 정의 lock이라고도 하며 트랜잭션 중에 스키마 오브젝트가 바뀌지 않도록 보호
내부 lock
데이터베이스와 메모리의 내부 컴포넌트를 보호한다.
분포 lock
데이타와 기타 자원들이 여러 인스턴스에 걸쳐 일치 되도록 하기 위하여 만들어 진다.
병렬 cache lock
버퍼 구역에서 하나 이상의 데이터 블록을 보호하는 분포lock이다.
매뉴얼 lock
* SQL*DBA는 현재 설정된 lock을 볼 수 있도록 lock모니터를 제공
* 데이타베이스 LINK 사용법
데이타베이스 link는 데이터베이스간에 경로를 정의한다.
create public database link node_01.corp.dist;
이렇게 링크를 만든 다음에 다음과 같은 쿼리를 할 수 있다.
select * from user_03.parts@node_01.corp.dist;
* 데이타베이스 LINK의 종류
1. 전용링크: 특정 사용자를 위해 만들어 진다.
2. 공용링크: public이라는 특수한 사용자 그룹을 위하여 만들어 진다. 그 데이타베이스의 모든 사용자가 이 링크에 대한 액세스를 갖는다.
3. 네트워크 링크: 이 링크는 네트워크 도메인 서비스에 의하여 만들어지고 관리된다. 그 네트워크에 있는 어떤 데이타베이스의 어떤 사용자라도 SQL문에서 글로벌 오브젝트 이름을 지정하면 네트워크 링크를 사용할 수 있다.
* 데이타베이스 LINK제거
drop database link user_03.parts@node_01.corp.dist
분산 데이터베이스와 프로세스
* 분산 데이타베이스 제한
분산 데이타베이스에서 성능에 도움이 되는 몇가지 제한
1. 노드당 분산 트랜잭션의 수를 제한
2. 각 인스턴스를 위하여 커미트 포인트 스트랭스를 설정
* 양면 commit(Two-Phase Commits)
오라클은 자동적으로 글로벌 데이터베이스를 감시하고 분산 트랜잭션의 글로벌 커밋과 롤백을 콘트롤한다. 양면 commit은 오라클이 분포 커밋과 롤백을 감시 하는 방법이다. 데이터 무결성을 유지하기 위함.
* 분산 어플리케이션 개발시 고려사항
1. 시퀀스 : 다음 두 사항이 참일 경우 리모트 시퀀스는 참조될 수 있다.
. 문장에서 참조된 시퀀스와 갱신된 테이블, 갱신 테이블을 위한 선택, 긴열, 그리고 lock된 테이블은 모두 그 시퀀스와 동일한 노드에 위치한다.
. 최소한 하나의 참조된 테이블이 시퀀스와 동일한 노드에 있다.
예)
select intro mst_part@inventory_01
select sq_1.nextal@inventory_01, part_id, part_name, part_price
from routings@inventory_01;
2. 참조무결성: 오라클은 분산 데이터베이스의 노드들에 참조 무결성이 선언되는것을 허용하지 않는다. 여러분은 리모트 테이블에서 주요 키나 고유키를 참조하는 외부키를 지정하는 하나의 테이블에 대한 참조무결성 제한을 가질 수 없지만 부모자식 관계는 분산 데이터베이스들 간에 허용된다. 이 관계는 트리거를 사용해야 유지될 수 있다.
3. 분산 쿼리: 트리거나 stored procedure를 이용하여 분산 쿼리를 만들수 있다.
4. 스냅샷: 오라클은 무제한의 스냅샷에 의하여 마스터 테이블을 다른 노드에 복제하는 것을 허용한다.스냅샷은 마스터 테이블은 이용할 수 없게 되더라도 그 데이터를 다른 노드에서 계속 이용할 수 있게 해준다.
옵티마이저
* 옵티마이저란?
모든 DML문을 실행하는 가장 효율적인 방법을 결정하는 오라클 서버의 일부분이다. 옵티마이저는 rules base 최적화와 cost base최적화의 두가지 경로를 통해 최적화된 검색 경로를 찾아간다.
* 옵티마이저를 사용하는 이유
오라클 옵티마이저는 실행 계획을 생성하는데 이 실행계획은 문장을 실행하기 위하여 오라클이 취하는 일련의 단계이다. 때로는 사용자가 옵티마이저보다 어플리케이션을 더 잘 알기 때문에 걁길행계획을 사용자가 지정하기도 하는데 이를 힌트라고 한다. 그러나 이렇게 지정 한다고 해서 이것이 directive(지시)를 뜻하지는 않기 때문에 옵티마이저는 다만 사용자가 주는 힌트를 제안으로 참고한다.
힌트에는 sql문을 최적화 하는데 사용되는 정보의 범위를 제한하는 힌트가 있는 반면에 전반적인 방침을 정하는 힌트들도 있다.
* 힌트가 하는 일
1. 참조된 각 테이블을 위한 액세스 경로
2. 접속을 위한 접속 순서
3. 테이블을 접속하는데 사용하는 방법
4. sql문을 위한 cost base approach
5. sql문을 위한 최적화 approach
* 실행계획
실행 계획은 오라클에 의해 만들어지며 오라클이 명령문을 실행하기 위하여 취하는 단계들을 정의한다. explain plan명령을 사용하여 문장의 실행계획을 검사할 수 있다.
출력예)
OPERATION OPTION OBJECT_NAME
--------------------------------------
select statement
table access by rowid dept
index range scan dpt_indx
* explain plan
explain plan사용의 첫 단계는 출력을 담을 테이블을 만드는 것이다. 이것을 위해 utxplan.sql 스크립트를 사용하여 사용자의 스키마에 테이블을 만들거나 수동으로 테이블을 만들 수 있다.
explain plan명령을 사용해 보자. 다음과 같다.
explain plan
set statement_id = 'part_cost'
select part_name, part_nbr, part_id, part_cost
from mst_part.part_nbr = inventory.part_nbr
and not exists
(select * from obs_parts
where part_code > min_cost);
다음과 같은 결과를 얻을 수 있다.
OPERATION OPTIONS OBJ_NAME ID PARENT_ID POS.
--------------------------------------------------
SELECT STMT 0 5
FILLTER 1 0 0
NESTED LOOP 2 1 1
TABEL ACCESS FULL MST_PART 3 2 1
TABLE ACCESS FULL INVENTORY 4 2 2
TABLE ACCESS FULL OBS_PARTS 5 1 3
이 예에서 옵티마이저가 3번의 완전 테이블 스캔을 수행하여 결과세트를 생성한다.
* 두가지 최적화 방법
1. Rule-based
오라클은 활용가능한 액세스에 기초를 둔 실행 계획을 선택하고 이들 경로로 랭크를 할당한다. 오라클은 항상 고 랭크에 대해서 저 랭크를 가진 경로를 선택한다.
2. Cost-based:
오라클은 활용가능한 액세스 경로를 고려하고 어떤 경로가 가장 효율적인지의 문제의 의해서 액세스되는 테이블, 테이블과 관련된 클러스터와 인덱스에 대한 데이터 사전의 상황에 기초를 두고 결정하게 된다. 다음의 과정을 거친다.
가) 여러 대안적인 실행계획이 활용가능한 경로와 조언에 기초를 두고 제시된다.
나) 옵티마이저는 각각의 실행 계획의 비용을 측정한다.
나) 옵티마이저는 가장 적은 비용의 실행 계획을 선택한다.
* SQL 최적화를 위한 표현식과 조건의 평가
1. 표현식과 조건은 옵티마이저가 우선적으로 평가하는 아이템이다. 다음의 첫 번째 문장은 두 번째 문장으로 옵티마이저에 의해 변형된다.
dozen=12000/12
dozen=1000
2. 조건을 디자인 할 때에는 표현식을 가진 조건을 열에 비교하지 말고 가능하면 상수를 열에 비고해야 한다.
price > cost*1.25;
3. 그 밖의 옵티마이저가 변환시키는 것들
month in ('JAN','MAR','MAY')
는 다음과 같이 바뀐다.
month='JAN' or month='MAR' or month = 'MAY'
part_nbr > (:new_part, :old_part);
는 다음과 같이 바뀐다.
part_nbr > any(:new_part, :old_part);
* 문장 변형
옵티마이저는 하나의 문장을 동일한 결과를 낳는 다른 문장으로 변형시킬때가 많다.
1. 조건 가운데 하나가 완전 테이블 스캔을 요구하지 않는 한 OR를 포함하는 문장이 union all을 포함하는 문장으로 변형된다.
2. 복합문이 연결문으로 변형된다. 복합문은 가능하면 등호 연결문으로 변경된다.
예를 들면
select chemical_name
from master_chemical
where chemical_id in
(select chemical_id from chemical_archive)
는 다음과 같이 변형된다.
select chemical_name
from master_chemical
where master_chemical.chemical_id=chemical_archive.chemical_id;
* 뷰 머징(View Merging)
뷰를 포함하는 문장 최적화시에는 다음중 하나가 실행된다.
1. 문장을 등가문(equivalent statement)으로 변형된다.
2. 뷰 쿼리를 만든 다음 그 결과를 마치 테이블인 것처럼 본래의 문장을 이용하여 처리한다.
예)
create view parts
as select part_nbr, part_name
from mst_parts
where mfg_pt='45J';
select part_name
from parts
where part_nbr like '95-%'
는 다음과 같이 바뀐다.
select part_name
from mst_parts
where part_nbr like '95-%'
and mfg_pt = '45J';
* 최적화 어프로치(approach) 결정
1. 고려할 사항
. 초기화 파라미터 optimizer_mode값
. alter session명령에 있는 optimier_mode파라미터
. 데이터 사전에 있는 통계
. 문장에 있는 힌트
2. optimizer_mode파라미터는 다음의 값들 가운데 하나를 가질 수 있다.
. cost: cost-based을 선택하도록 한다.
. rule: rule-based를 선택하도록 한다.
3. optimization_goal파라미터는 다음의 값들 가운데 하나와 같을 수 있다.
. choose : cost-based든 rule-based든 하나를 고르도록 강요한다.
. all_rows : 코스트 중심 어프로치로 현재 목표를 달성하도록 강요한다.
. fist_row : 코스트 중심 어프로치로 최선의 응답시간을 얻도록 강요한다.
. rule : 옵티마이저가 rule-based 어프로치를 선택하도록 강요한다.
* 액세스 경로 선정
1. 데이터와 테이블을 액세스하는 여러 가지 방법
. 완전테이블 스캔
. rowid에 의한 테이블 스캔
. 클러스터 스캔 : 동일한 클러스터 키를 가진 행들이 검색된다.
. 해시 스캔 : 동일한 해시 값을 가진 모든 행이 검색된다.
. 인덱스된 스캔 : 인덱스의 한 행 이상의 값에 기초하여 인덱스로부터 데이터가 검색된다.
2. 액세스 경로의 순위
(1) rowid에 의한 단일 행
(2) 클러스터 연결에 의한 단일 행
(3) 고유한 이름이나 주요 키에 의한 해시클러스터 키에 의한 단일 행
(4) 고유한 이름이나 중 키에 의한 단일 행
(5) 클러스터 연결
(6) 해시 클러스터 키
(7) 인덱스된 클러스터 키
(8) 복합 인덱스
(9) 단일 열 인덱스
(10) 인덱스된 열에서 바운드된 범위 선택
(11) 인덱스된 열에서 바운드되지 않은 범위 선택
(12) 소트-머지 연결
(13) 인덱스된 열의 최대와 최소
(14) 인덱스된 열의 의한 순서
(15) 완전 테이블 스캔
* 연결 순서의 선택
rule-based approach 실행 단계
1. 옵티마이저는 서로다른 테이블에서 첫 테이블을 사용하여 일련의 접속을 만든다. 첫 테이블 뒤에 테이블의 순서를 메꾸기 위해 옵티마이저는 전항에서 제시된 순위에 의해 최상의 액세스 경로를 산출하는 테이블의 결합을 선택한다. 일단 테이블의 순서가 결정되면 그 앞의 테이블을 액세스 하기 위한 각 테이블의 액세스 방법이 결정된다.
2. 실행 가능한 실행 계획들이 평가되고 하나가 선택된다. 이 선택 프로세스에서 옵티마이저의 목표는 인덱스 스캔을 이용하여 그 이너(inner)테이블이 액세스되는 중첩된 연결 연산의 수를 극대화하는 실행 플랜을 찾는 것이다.
cost-based approach 실행 단계
1. 가능한(available) 연결 순서와 연결 연산, 그리고 이용가능한 액세스 경로에 기초하여 일련의 가능한 실행 계획이 생성된다.
2. 그 다음, 옵티마이저는 가능한 각 실행 플랜을 위한 코스트를 계산한다.
이 코스트는 다음에 기초한다.
. 중첩된 루프의 코스트는 아우터 조인의 선택된 까 행과 그와 매치하는 이너테이블의 각 행을 메모리에 읽어 들이는 코스트에 기초한다.
. 소트-머지 연결의 코스트는 각 소스를 메모리에 읽어들이고 그것을 소트하는 코스트에 주로 기초한다.
. 소트 크기와 인덱싱, 복수 블록 리드, 그리고 시퀀스 리드와 같은 요인들이 모두가 코스트 산정에 들어가는 요인이다.
코스트 중심 어프로치에서, 연결 실행의 순서는 정렬된 힌트를 이용하여 사용자가 정의할 수 있다.
* 연결 연산의 선택
두 행 소스를 연결하려면 오라클이 다음의 연산 가운데 하나를 수행하여야 한다.
. 내장 루프
. 소트-머지
. 클러스터
1. 내장 루프 연결 단계
(1) 드라이빙 테이블 또는 주요 테이블로서 하나의 테이블이 선정되고 다른 테이블들은 이너(inner)테이블이라고 부른다.
(2) 주요 테이블에 있는 각 해을 위하여 연결 조건을 만족시키는 모든 행을 이너 테이블에서 찾는다.
(3) 연결 조건을 만족시키는 각 쌍의 행으로부터의 데이터가 결합되어 결과행을 리턴한다.
2. 소트-머지 연결 단계
(1) 연결할 각 행을 그 연결에 사용된 열에서 소트한다.
(2) 한 소스에 있는 각 행이 그 연결 열을 위한 매칭 값을 포함하는 다른 소스의 각 행과 결합 되도록 두 소스가 머지된다.
3. 클러스터 연결 주의사항
오라클은 동일한 클러스터에 내장된 두 테이블의 클러스터 키 열과 동등한 등호 연결을 위해서만 클러스터 연결을 수행할 수 있다. 클러스터 연결은 간단히 말해서 하나의 클러스터에 함께 내장된 두 테이블을 포함하는 중첩된 루프이다.
* SQL문의 종류
오라클은 다음과 같은 종류의 SQL문들을 최적화 한다.
insert나 update와 같은 단순문, 단순 쿼리, 연결(둘 이상의 테이블로부터 데이터 선택), 등호 연결, 비 등호 연결, 아우터 조인, 카르테시안 프로덕트, 복합문, 혼합쿼리, 분산문
* 혼합 쿼리
혼합쿼리는 옵티마이저에 의하여 여러 컴포넌트로 나누어진다. 그 다음, 각 컴포넌트에 실행 계획이 주어지고 각 컴포넌트의 결과는 union, intersection, minus연산을 이용하여 조합된다.
union all 연산자를 위해서는 각 테이블에서 완전 테이블 스캔이 일어난다. 또한 그 결과는 조합되어 결과 선정 세트를 만들게 된다.
union 연산자는 union all과 비슷한데 다만, sort-unique연산이 조합된 결과에서 실행되어 결과 선전 세트가 만들어 진다는 것이다.
intersection연산자는 각 테이블이 완전 스캔이 일어나고 각 개별 완전 테이블 스캔에서 sort-unique연산을 수행한다. 양 sort-unique결과세트에 모두 나타나는 행만 최종 선정 세트에 조합되도록 sort-unique연산의 결과들이 조합된다.
* 분산문(Distributed Statement) 고려사항
만약 sql문을 위한 테이블들이 여러 리모트 노드에 분포되어 있다면 오라클은 그 문장을 단일 데이터베이스를 액세스하는 단편들로 분해한다. 이 단편들은 실행을 위하여 리모트 데이터베이스로 보내진다. 리모트 데이터베이스는 실행계획을 생성하고 결과 선정세트를 그 호출 데이터베이스에 리턴한다. 로컬 호출 데이터베이스는 그 다음 필요하다면 추가의 프로세싱을 수행한다.
| Oracle Shared Server 튜닝 (0) | 2011.12.13 |
|---|---|
| 쿼리문이 제대로 Index를 타는지 확인하는 방법 (0) | 2008.03.27 |
| Oracle ERP에서 사용하는 DB관련 작업 (0) | 2007.10.22 |
| Oracle Database 학습법 (0) | 2007.09.12 |
| TOAD, DB 관리자의 ‘손과 발’ (0) | 2006.11.03 |
|
| rman에서 3일치 놔두고 아카이브로그지우기 (0) | 2008.02.11 |
|---|---|
| exp_imp_test_procedure.txt (0) | 2008.01.28 |
| Oracle 9i RMAN 명령어 (0) | 2008.01.28 |
| Configuration of Load Balancing and Transparent Application Failover (0) | 2007.12.11 |
| 오라클(oracle) 백업(exp), 복구(imp) 하기 (0) | 2006.05.09 |
 [Oracle]오라클 어드민 팁
[Oracle]오라클 어드민 팁
Oracle Administration을 정리하다가 간단히 찾아고 조금이나마 도움이 되시라고 정리해서 올립니다.
너무 단시간에 두서없이 써서 보기도 좋지 않지만 필요하신 분들 심심할때 하나씩
해보세요.(다들 아시는거지만~~)
아래 tips 는 하나의 database에서 작성한 것이 아니므로 각종 정보들(file들의 위치등)이
tip마다 다를 수 있습니다. 각 tip은 개개의 것으로 생각하시고 응용하시기 바랍니다.
혹시 틀린 내용 발견되면 mail주세요. 바로 수정하겠습니다.
편집 이쁘게 못해서 죄송합니다.
나름대로 사연있는 글입니다.
정리하다가 날려먹어서 한 몇일 더 고생해서 작성한겁니다.^^;
님들도 좋은 정보 있으시면 공유하시죠.
================================================================================================
1. DBMS = database(data file & control file & redo log file) +
instance(memory & background processes)
================================================================================================
2. Oracle Architecture Component
================================================================================================
* Oracle Instance 확인 : v$instance
SQL> select instance_name from v$instance;
INSTANCE_NAME
----------------
IBM
================================================================================================
* datafile들의 경로 및 정보 : v$datafile
SQL> select name from v$datafile;
NAME
--------------------------------------------------------------------------------
/oracle/ora_data/system/system01.dbf
/oracle/ora_data/data/tools01.dbf
/oracle/ora_data/data/rbs01.dbf
/oracle/ora_data/data/temp01.dbf
/oracle/ora_data/data/users01.dbf
================================================================================================
* control file의 경로 및 정보 : v$controlfile;
SQL> select name from v$controlfile;
NAME
--------------------------------------------------------------------------------
/oracle/ora_data/contr1/ora_control1
/oracle/ora_data/contr2/ora_control2
================================================================================================
* logfile의 경로 및 정보 : v$logfile
SQL> select member from v$logfile;
MEMBER
--------------------------------------------------------------------------------
/oracle/ora_data/redolog_a/redo1a.log
/oracle/ora_data/redolog_b/redo1b.log
/oracle/ora_data/redolog_a/redo2a.log
/oracle/ora_data/redolog_b/redo2b.log
/oracle/ora_data/redolog_a/redo3a.log
/oracle/ora_data/redolog_b/redo3b.log
================================================================================================
* System Global Area 내용을 조회
SQL> select * from v$sga;
NAME VALUE
-------------------- ----------
Fixed Size 108588
Variable Size 27631616
Database Buffers 2252800
Redo Buffers 77824
SQL> show sga
Total System Global Area 30070828 bytes
Fixed Size 108588 bytes
Variable Size 27631616 bytes
Database Buffers 2252800 bytes
Redo Buffers 77824 bytes
================================================================================================
* 현재 수행중인 background process들을 확인
SQL> select paddr,name,description from v$bgprocess where paddr>'00';
PADDR NAME DESCRIPTION
---------------- ----- ----------------------------------------------------------------
070000000139ABC0 PMON process cleanup
070000000139AFD0 DBW0 db writer process 0
070000000139B3E0 LGWR Redo etc.
070000000139B7F0 CKPT checkpoint
070000000139BC00 SMON System Monitor Process
070000000139C010 RECO distributed recovery
SQL> !ps -ef|grep ora|grep
oracle 25148 1 0 19:25:34 - 0:00 ora_reco_IBM
oracle 60576 1 0 19:25:34 - 0:00 ora_smon_IBM
oracle 60782 1 0 19:25:34 - 0:00 ora_pmon_IBM
oracle 70166 1 0 19:25:34 - 0:00 ora_lgwr_IBM
oracle 72248 1 0 19:25:34 - 0:00 ora_ckpt_IBM
oracle 84918 1 0 19:25:34 - 0:00 ora_dbw0_IBM
================================================================================================
* 초기화 파라미터 파일 : init
================================================================================================
* database log 모드 확인
SQL> connect internal
Connected.
SQL> archive log list
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination /oracle/app/oracle/product/8.1.6/dbs/arch
Oldest online log sequence 20
Current log sequence 22
SQL> select log_mode from v$database;
LOG_MODE
------------
NOARCHIVELOG
================================================================================================
3. Managing an Oracle Instance
================================================================================================
단계별 :
shutdown : oracle이 내려가 있는 상태
nomount : instance started(SGA, B.G process를 시작 init
alert, trace file open
- 이 단계에서 할 수 있는 것은
a. db creation
- 이 상태에서도 볼수있는 view
v$parameter
v$dga
v$option
v$process
v$session
v$version
v$instance
mount : control file opened for this instance
- 이 단계에서 할 수 있는 것은 control file의 내용을 변경하는것
a. archivelog mode로 변환
b. data file/redo log file rename시
c. recovery시
- SQL>alter database open read only;
로 하게되면 data file에 writing을 허용 안함.
open : control file에 기술된 모든 files open
================================================================================================
* parameter 변경 종류
a. init
b. alter session set ~
c. alter system set ~ => shutdown 될때까지 변경된것 유효
alter system deffered set ~ => 현재 session에서만 변경된것 유효
================================================================================================
* 특정 session 죽이기
SQL> select sid, serial#,username,status from v$session; => (특정 user는 where username='SCOTT'로)
SID SERIAL# USERNAME STATUS
---------- ---------- ------------------------------ --------
1 1 ACTIVE
2 1 ACTIVE
3 1 ACTIVE
4 1 ACTIVE
5 1 ACTIVE
6 1 ACTIVE
7 1 SYS ACTIVE
SQL> alter system kill session '7,3' -- 7은 sid, 3은 serial#
================================================================================================
* alert file 과 trace file
- alert file은 꼭 1개, 중요한사건,시간순으로 (startup,shutdown,recovery)
- trace file은 여러개 가능, background process는 background_dump_dest에 생기고 server process는
user_dump_dest에 생성된다.
================================================================================================
4. Creating a Database
================================================================================================
* Create a Database Manually
a. OS Environment setting
.profile에 ORACLE_HOME,ORACLE_SID,ORA_NLS33,PATH,(ORACLE_BASE) 등을 편집한다.
ex)
DISPLAY=swsvrctr:0.0
ORACLE_HOME=/oracle/app/oracle/product/8.1.7
PATH=$ORACLE_PATH/bin:/usr/ccs/bin:$PATH
NLS_LANG=AMERICAN_AMERICA.KO16KSC5601
ORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/data
ORACLE_SID=IBM
b. init.ora file을 copy하고 편집한다.
db_name=KYS
control_files = (/home/oracle/data02/control/control01.ctl,/home/oracle/data02/control/control02.ctl)
db_block_size = 8192
기본적으로 위 두개 parameter외에
rollback_segments=(rbs1,rbs2,..) =>나중에 rollback segment생성후 DB start시 Online되는 rbs지정
background_dump_dest=/home/oracle/data02/bdump
user_dump_dest=/home/oracle/data02/udump
core_dump_dest=/home/oracle/data02/cdump
c. Starting the Instance
SQL> startup nomount
SQL> startup nomount pfile=initKYS.ora
SQL> create database KYS
2 maxlogfiles 5
3 maxlogmembers 5
4 maxdatafiles 100
5 maxloghistory 100
6 logfile
7 group 1 ('/home/oracle/data02/redolog/log1a.rdo','/home/oracle/data02/redolog2/log1b.rdo') size 1m,
8 group 2 ('/home/oracle/data02/redolog/log2a.rdo','/home/oracle/data02/redolog2/log2b.rdo') size 1m
9 datafile
10 '/home/oracle/data02/data/system01.dbf' size 50m autoextend on
11 character set "KO16KSC5601";
일단 여기까지 database는 생성이 되었다.
이후부터는 추가적인 작업이다.
d. 추가 system rollback segment 생성
SQL> create rollback segment r0 tablespace system
2 storage (initial 16k next 16k minextents 2 maxextents 10);
e. rollback sement online
SQL> alter rollback segment r0 online;
f. rollback segment tablespace 생성 & datafile 저장위치, 크기 및 초기값 지정
SQL> create tablespace rbs
2 datafile '/home/oracle/data02/data/rbs01.dbf' size 300m
3 default storage(
4 initial 4M
5 next 4M
6 pctincrease 0
7 minextents 10
8 maxextents unlimited);
g. rollback segment 생성
SQL> create rollback segment r01 tablespace rbs
2 storage (minextents 10 optimal 40M);
SQL> create rollback segment r02 tablespace rbs
2 storage (minextents 10 optimal 40M);
SQL> create rollback segment r03 tablespace rbs
2 storage (minextents 10 optimal 40M);
SQL> create rollback segment r04 tablespace rbs
2 storage (minextents 10 optimal 40M);
h. rollback segment online
SQL> alter rollback segment r01 online;
SQL> alter rollback segment r02 online;
SQL> alter rollback segment r03 online;
SQL> alter rollback segment r04 online;
i. 추가 system rollback segment off-line 및 삭제
SQL> alter rollback segment r0 offline;
SQL> drop rollback segment r0;
j. sorting 작업시 필요한 temporary tablespace 생성 & datafile 저장 위치, 크기 및 초기값 지정
SQL> create tablespace temp
2 datafile '/home/oracle/data02/data/temp01.dbf' size 300 temporary
3 default storage(
4 initial 4M
5 next 4M
6 maxextents unlimited
7 pctincrease 0);
k. 추가 tablespace 생성 & data file 저장 위치 및 크기 지정
SQL> create tablespace tools
2 datafile '/home/oracle/data02/data/tools.dbf' size 50m
3 default storage(
4 maxextents 505
5 pctincrease 0);
SQL> create tablespace users
2 datafile '/home/oracle/data02/data/user01.dbf' size 30M
3 default storage(
4 maxextents 505
5 pctincrease 0);
l. 작업 환경에서 추가적으로 필요한 tablespace는 위의 방법으로 생성한다.
================================================================================================
5. Data Dictionary and Standard Package
================================================================================================
* database 생성후 돌려줘야 할 script
$ORACLE_HOME/rdbms/admin/catalog.sql ==> dictionary views, export utility views 생성
$ORACLE_HOME/rdbms/admin/catproc.sql ==> procedures, functions 생성
$ORACLE_HOME/rdbms/admin/catdbsyn.sql ==> synonyms 생성
================================================================================================
* Dictionary list 확인
SQL> col table_name format a30
SQL> col comments format a45
SQL> set pages 800
SQL> spool dictionary.lst
SQL> select * from dictionary order by 1 ==> 전체 dictionary의 list를 볼 수 있다.
SQL> spool off
SQL> ed sictionary.lst
SQL> select * from dictionary where table_name like '%TABLE%'; ==> table 관련 dictionary
SQL> select * from dictionary where table_name like '%INDEX%'; ==> index 관련 dictionary
================================================================================================
* 유용한 dictionary
TABLE_NAME COMMENTS
------------------------------ ---------------------------------------------
DBA_USERS Information about all users of the database
DBA_TABLESPACES Description of all tablespaces
DBA_DATA_FILES Information about database data files
DBA_FREE_SPACE Free extents in all tablespaces
DBA_OBJECTS All objects in the database
DBA_SEGMENTS Storage allocated for all database segments
DBA_ROLLBACK_SEGS Description of rollback segments
DBA_EXTENTS Extents comprising all segments in the database
DBA_TABLES Description of all relational tables in the d
atabase
DBA_INDEXES Description for all indexes in the database
DBA_VIEWS Description of all views in the database
DBA_TRIGGERS All triggers in the database
DBA_SOURCE Source of all stored objects in the database
================================================================================================
* sample Query
SQL> select username,default_tablespace,temporary_tablespace from dba_users;
SQL> select tablespace_name,bytes,file_name from dba_data_files;
SQL> select tablespace_name,count(*),sum(bytes) from dba_free_space
2 group by tablespace_name;
================================================================================================
6. Maintiaining the Contorol File
================================================================================================
* Control File 리스트 조회
SQL> select name from v$controlfile;
NAME
--------------------------------------------------------------------------------
/home/oracle/data01/oradata/IBM/control01.ctl
/home/oracle/data01/oradata/IBM/control02.ctl
/home/oracle/data01/oradata/IBM/control03.ctl
================================================================================================
* Control File 을 하나 추가해보자
a. database shutdown
SQL> shutdown immediate
b. control file 복사(os상 물리적인 복사)
/home/oracle/data01/oradata/IBM> cp control03.ctl control04.ctl ==> 실제는 다른 disk로 복사해야함
문제발생을 대비해 분리하는것임.
c. Parameter File 편집
control_files = ("/home/oracle/data01/oradata/IBM/control01.ctl",
"/home/oracle/data01/oradata/IBM/control02.ctl",
"/home/oracle/data01/oradata/IBM/control03.ctl",
"/home/oracle/data01/oradata/IBM/control04,ctl")
d. database startup & 확인
SQL> startup
SQL> select name from v$controlfile;
NAME
--------------------------------------------------------------------------------
/home/oracle/data01/oradata/IBM/control01.ctl
/home/oracle/data01/oradata/IBM/control02.ctl
/home/oracle/data01/oradata/IBM/control03.ctl
/home/oracle/data01/oradata/IBM/control04.ctl ==> 하나 더 추가되었지요...(실제는 다른disk로)
================================================================================================
7. Multiplexing Redo Log Files
================================================================================================
* Redo Log File 리스트 조회
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 862 512000 1 CURRENT
2 860 512000 1 INACTIVE
3 861 512000 1 INACTIVE
SQL> select * from v$logfile;
GROUP# STATUS MEMBER
---------- -------------- --------------------------------------------------
1 /home/oracle/data01/oradata/IBM/redo03.log
2 /home/oracle/data01/oradata/IBM/redo02.log
3 /home/oracle/data01/oradata/IBM/redo01.log
================================================================================================
* Log Group 추가(기존 로그 파일과 동일한 사이즈로)
SQL> alter database add logfile
2 '/home/oracle/data01/oradata/IBM/redo04.log' size 200k;
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 862 512000 1 CURRENT
2 860 512000 1 INACTIVE
3 861 512000 1 INACTIVE
4 0 204800 1 UNUSED
SQL> select * from v$logfile;
GROUP# STATUS MEMBER
---------- -------------- --------------------------------------------------
1 /home/oracle/data01/oradata/IBM/redo03.log
2 /home/oracle/data01/oradata/IBM/redo02.log
3 /home/oracle/data01/oradata/IBM/redo01.log
4 /home/oracle/data01/oradata/IBM/redo04.log
================================================================================================
* Log Group 별 멤버 파일 추가 ==> backup 시 risk줄이기 위해 실제는 다른 disk에 해야함.
SQL> alter database add logfile member
2 '/home/oracle/data01/oradata/IBM/redo01b.log' to group 1,
3 '/home/oracle/data01/oradata/IBM/redo02b.log' to group 2,
4 '/home/oracle/data01/oradata/IBM/redo03b.log' to group 3,
5 '/home/oracle/data01/oradata/IBM/redo04b.log' to group 4;
================================================================================================
* 확인
SQL> !ls /home/oracle/data01/oradata/IBM/*.log
/home/oracle/data01/oradata/IBM/redo01.log /home/oracle/data01/oradata/IBM/redo03.log
/home/oracle/data01/oradata/IBM/redo01b.log /home/oracle/data01/oradata/IBM/redo03b.log
/home/oracle/data01/oradata/IBM/redo02.log /home/oracle/data01/oradata/IBM/redo04.log
/home/oracle/data01/oradata/IBM/redo02b.log /home/oracle/data01/oradata/IBM/redo04b.log
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 862 512000 2 CURRENT
2 860 512000 2 INACTIVE
3 861 512000 2 INACTIVE
4 0 204800 2 UNUSED ==> 아직 한번도 사용되지 않음
SQL> select * from v$logfile;
GROUP# STATUS MEMBER
---------- -------------- --------------------------------------------------
1 /home/oracle/data01/oradata/IBM/redo03.log
2 /home/oracle/data01/oradata/IBM/redo02.log
3 /home/oracle/data01/oradata/IBM/redo01.log
4 /home/oracle/data01/oradata/IBM/redo04.log
1 INVALID /home/oracle/data01/oradata/IBM/redo01b.log
2 INVALID /home/oracle/data01/oradata/IBM/redo02b.log
3 INVALID /home/oracle/data01/oradata/IBM/redo03b.log
4 INVALID /home/oracle/data01/oradata/IBM/redo04b.log
==> 현재 사용되고 있는 log group 은 group 1이고 나중에 추가한 member들은 invalid 한 상태이다.
강제로 log switch를 일으켜서 valid하게 바꾸자.
SQL> alter system switch logfile;
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 862 512000 2 ACTIVE
2 860 512000 2 INACTIVE
3 861 512000 2 INACTIVE
4 863 204800 2 CURRENT ==> unused에서 바뀜.
SQL> select * from v$logfile;
GROUP# STATUS MEMBER
---------- -------------- --------------------------------------------------
1 /home/oracle/data01/oradata/IBM/redo03.log
2 /home/oracle/data01/oradata/IBM/redo02.log
3 /home/oracle/data01/oradata/IBM/redo01.log
4 /home/oracle/data01/oradata/IBM/redo04.log
1 INVALID /home/oracle/data01/oradata/IBM/redo01b.log
2 INVALID /home/oracle/data01/oradata/IBM/redo02b.log
3 INVALID /home/oracle/data01/oradata/IBM/redo03b.log
4 /home/oracle/data01/oradata/IBM/redo04b.log ==> valid하게 바뀜
================================================================================================
Log Miner
================================================================================================
* Parameter File 의 utl_file_dir 편집
a. 확인
SQL> select name,value from v$parameter
2 where name='utl_file_dir';
NAME VALUE
-------------------- ------------------------------
utl_file_dir
SQL> !mkdir $ORACLE_HOME/LOG
b. LogMiner사용을 위해 init
utl_file_dir=/oracle/app/oracle/product/8.1.7/LOG
c. restart
SQL> shutdown immediate
SQL> startup
확인
SQL> select name,value from v$parameter
2 where name='utl_file_dir';
NAME VALUE
-------------------- ------------------------------
utl_file_dir /oracle/app/oracle/product/8.1.7/LOG ==> LogMiner 준비를 위한 parameter set
d. LogMiner setting - 반드시 트랜잭션의 첫번째 명령이어야 함
SQL> commit;
SQL> exec dbms_logmnr_d.build('v817dict.ora','/oracle/app/oracle/product/8.1.7/LOG');
BEGIN dbms_logmnr_d.build('v817dict.ora','/oracle/app/oracle/product/8.1.7/LOG'); END;
*
ERROR at line 1:
ORA-06532: Subscript outside of limit
ORA-06512: at "SYS.DBMS_LOGMNR_D", line 793
ORA-06512: at line 1
SQL> !ls $ORACLE_HOME/LOG
SQL> exec dbms_logmnr.add_logfile('/home/oracle/data01/oradata/IBM/redo01.log',DBMS_LOGMNR.NEW);
SQL> exec dbms_logmnr.add_logfile('/home/oracle/data01/oradata/IBM/redo02.log',DBMS_LOGMNR.ADDFILE);
SQL> exec dbms_logmnr.add_logfile('/home/oracle/data01/oradata/IBM/redo03.log',DBMS_LOGMNR.ADDFILE);
SQL> exec dbms_logmnr.add_logfile('/home/oracle/data01/oradata/IBM/redo04.log',DBMS_LOGMNR.ADDFILE);
SQL> exec dbms_logmnr.start_logmnr('/oracle/app/oracle/product/8.1.7/LOG/v817dict.ora');
e. 트랜잭션 수행
SQL> descc scott.dept
SQL> select * from scott.dept;
SQL> insert into scott.dept values(99,'test','test');
SQL> update scott.dept set loc='TEST' where deptno=99;
SQL> commit;
f. log miner 정보 분석
SQL> select timestamp,username,sql_redo from v$logmnr_contents
2 where seg_name='DEPT';
g. 로그마이닝 종료
SQL> exec dbms_logmnr.end_logmnr;
================================================================================================
8. Managing TableSpace and Data Files
================================================================================================
* tablespace와 datafile 조회
SQL> col tablespace_name format a15
SQL> col file_name format a45
SQL> select tablespace_name,status,contents from dba_tablespaces;
TABLESPACE_NAME STATUS CONTENTS
--------------- ------------------ ------------------
SYSTEM ONLINE PERMANENT
TOOLS ONLINE PERMANENT
RBS ONLINE PERMANENT
TEMP ONLINE TEMPORARY
USERS ONLINE PERMANENT
INDX ONLINE PERMANENT
DRSYS ONLINE PERMANENT
SQL> select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
TOOLS 10485760 /home/oracle/data01/oradata/IBM/tools01.dbf
DRSYS 20971520 /home/oracle/data01/oradata/IBM/drsys01.dbf
USERS 20971520 /home/oracle/data01/oradata/IBM/users01.dbf
INDX 20971520 /home/oracle/data01/oradata/IBM/indx01.dbf
RBS 52428800 /home/oracle/data01/oradata/IBM/rbs01.dbf
TEMP 20971520 /home/oracle/data01/oradata/IBM/temp01.dbf
SYSTEM 283115520 /home/oracle/data01/oradata/IBM/system01.dbf
================================================================================================
* tablespace 생성 및 사이즈 변경
SQL> create tablespace data05
2 datafile '/home/oracle/data01/oradata/IBM/data05_01.dbf' size 1m;
Tablespace created.
1m 짜리 datafile 하나를 가진 tablespace data05를 추가하였다. 확인.
SQL> select tablespace_name,bytes,file_name from dba_data_files
2 where tablespace_name='DATA05';
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_01.dbf
tablespace가 부족할때 늘리는 방법은 두가지가 있다.
하나는 datafile을 추가하는 방법이고 다른하나는 datafile의 size를 늘리는 방법이다.
a. datafile을 하나 추가해보자.
SQL> alter tablespace data05
2 add datafile '/home/oracle/data01/oradata/IBM/data05_02.dbf' size 1m;
SQL> select tablespace_name,bytes,file_name from dba_data_files
2 where tablespace_name='DATA05';
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_01.dbf
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_02.dbf
제대로 추가되었다.
b. 그렇다면 하나의 사이즈를 변경해보자.
SQL> alter database datafile
2 '/home/oracle/data01/oradata/IBM/data05_02.dbf' resize 2m;
SQL> select tablespace_name,bytes,file_name from dba_data_files
2 where tablespace_name='DATA05';
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_01.dbf
DATA05 2097152 /home/oracle/data01/oradata/IBM/data05_02.dbf
2m로 제대로 변경이 되었다.
다시 원상복구
SQL> alter database datafile
2 '/home/oracle/data01/oradata/IBM/data05_02.dbf' resize 1m;
전체를 다시 확인해보자
SQL> select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
TOOLS 10485760 /home/oracle/data01/oradata/IBM/tools01.dbf
DRSYS 20971520 /home/oracle/data01/oradata/IBM/drsys01.dbf
USERS 20971520 /home/oracle/data01/oradata/IBM/users01.dbf
INDX 20971520 /home/oracle/data01/oradata/IBM/indx01.dbf
RBS 52428800 /home/oracle/data01/oradata/IBM/rbs01.dbf
TEMP 20971520 /home/oracle/data01/oradata/IBM/temp01.dbf
SYSTEM 283115520 /home/oracle/data01/oradata/IBM/system01.dbf
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_01.dbf
DATA05 1048576 /home/oracle/data01/oradata/IBM/data05_02.dbf
================================================================================================
* tablespace 삭제 : Dictionary에서만 삭제되는것으로 실제 물리적으로 파일은 os command로 삭제해야한다.
SQL> select tablespace_name from dba_tablespaces
2 where tablespace_name like 'DATA%'
3 minus
4 select distinct tablespace_name from dba_segments;
TABLESPACE_NAME
---------------
DATA05
SQL> drop tablespace data05;
SQL> select tablespace_name,bytes,file_name from dba_data_files;
TABLESPACE_NAME BYTES FILE_NAME
--------------- ---------- ---------------------------------------------
TOOLS 10485760 /home/oracle/data01/oradata/IBM/tools01.dbf
DRSYS 20971520 /home/oracle/data01/oradata/IBM/drsys01.dbf
USERS 20971520 /home/oracle/data01/oradata/IBM/users01.dbf
INDX 20971520 /home/oracle/data01/oradata/IBM/indx01.dbf
RBS 52428800 /home/oracle/data01/oradata/IBM/rbs01.dbf
TEMP 20971520 /home/oracle/data01/oradata/IBM/temp01.dbf
SYSTEM 283115520 /home/oracle/data01/oradata/IBM/system01.dbf
SQL> !ls //home/oracle/data01/oradata/IBM/*.dbf
//home/oracle/data01/oradata/IBM/data05_01.dbf //home/oracle/data01/oradata/IBM/system01.dbf
//home/oracle/data01/oradata/IBM/data05_02.dbf //home/oracle/data01/oradata/IBM/temp01.dbf
//home/oracle/data01/oradata/IBM/drsys01.dbf //home/oracle/data01/oradata/IBM/tools01.dbf
//home/oracle/data01/oradata/IBM/indx01.dbf //home/oracle/data01/oradata/IBM/users01.dbf
//home/oracle/data01/oradata/IBM/rbs01.dbf
dictionary에서는 삭제되었으나 여전히 물리적인 file은 존재한다. 삭제하면 된다.
(tablespace생성시에는 file이 그냥 생성되나 삭제시는 dictionary삭제후 강제로 삭제해줘야 한다.)
SQL> !rm /home/oracle/data01/oradata/IBM/data05*
================================================================================================
* tablespace 의 online/offline, read only/read write
SQL> select tablespace_name, status from dba_tablespaces;
TABLESPACE_NAME STATUS
------------------------------------------------------------ ------------------
SYSTEM ONLINE
TOOLS ONLINE
RBS ONLINE
TEMP ONLINE
USERS ONLINE
INDX ONLINE
DRSYS ONLINE
7 rows selected.
SQL> select tablespace_name from dba_tables
2 where table_name ='DEPT' and owner='SCOTT';
TABLESPACE_NAME
------------------------------------------------------------
SYSTEM
default로 생성시 scott user의 data가 system tablespace에 생성되었으나 이렇게 쓰면 안된다.
하나 생성해볼까?
SQL> create tablespace data01
2 datafile '/home/oracle/data01/oradata/IBM/data01.dbf' size 1m;
Tablespace created.
SQL> connect scott/tiger
Connected.
SQL> create table dept_tmp tablespace data01
2 as select * from dept;
SQL> connect internal
Connected.
SQL> select tablespace_name from dba_tables
2 where table_name ='DEPT_TMP' and owner='SCOTT';
TABLESPACE_NAME
------------------------------------------------------------
DATA01
SQL> select * from scott.dept_tmp;
DEPTNO DNAME LOC
---------- ---------------------------- --------------------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
제대로 된다. 그렇다면 tablespace를 offline으로...
SQL> alter tablespace data01 offline;
SQL> select tablespace_name, status from dba_tablespaces
2 where tablespace_name='DATA01';
TABLESPACE_NAME STATUS
------------------------------------------------------------ ------------------
DATA01 OFFLINE
SQL> select * from scott.dept_tmp;
select * from scott.dept_tmp
*
ERROR at line 1:
ORA-00376: file 8 cannot be read at this time
ORA-01110: data file 8: '/home/oracle/data01/oradata/IBM/data01.dbf'
위와 같이 error가 발생한다.
다시 online으로 해두자.
SQL> alter tablespace data01 online;
이번엔 read only로 변경
SQL> alter tablespace data01 read only;
SQL> select tablespace_name, status from dba_tablespaces
2 where tablespace_name='DATA01';
TABLESPACE_NAME STATUS
------------------------------------------------------------ ------------------
DATA01 READ ONLY
변경되었다.
SQL> insert into scott.dept_tmp values(80,'new_dept','new_loc');
insert into scott.dept_tmp values(80,'new_dept','new_loc')
*
ERROR at line 1:
ORA-00372: file 8 cannot be modified at this time
ORA-01110: data file 8: '/home/oracle/data01/oradata/IBM/data01.dbf'
insert같은 DML(write성) 수행시 위와 같은 error 발생
원상복구
SQL> alter tablespace data01 read write;
SQL> insert into scott.dept_tmp values(80,'test','test');
제대로 된다.
================================================================================================
9. Storage Structure and Relationships
================================================================================================
* Extent 정보 조회 : 다음과 같이 각종 extent,segment 등의 정보를 조회해 볼 수 있다.
SQL> col owner format a10
SQL> col segment_type format a12
SQL> col segment_name format a12
SQL> col tablespace_name format a10
SQL> select owner,segment_name,segment_type, tablespace_name,max_extents,extents,pct_increase
2 from dba_segments
3 where max_extents - extents <= 10 and owner !='SYS';
no rows selected
SQL> select owner,segment_name,segment_type, tablespace_name,max_extents,extents,pct_increase
2 from dba_segments
3 where owner='SCOTT';
OWNER SEGMENT_NAME SEGMENT_TYPE TABLESPACE MAX_EXTENTS EXTENTS PCT_INCREASE
---------- ------------ ------------ ---------- ----------- ---------- ------------
SCOTT DEPT_TMP TABLE DATA01 505 1 50
SCOTT DEPT TABLE SYSTEM 2147483645 1 50
SCOTT EMP TABLE SYSTEM 2147483645 1 50
SCOTT BONUS TABLE SYSTEM 2147483645 1 50
SCOTT SALGRADE TABLE SYSTEM 2147483645 1 50
SCOTT PK_DEPT INDEX SYSTEM 2147483645 1 50
SCOTT PK_EMP INDEX SYSTEM 2147483645 1 50
SQL> select segment_name,extents, initial_extent, next_extent,pct_increase
2 from dba_segments
3 where owner='SCOTT' and segment_name='EMP';
SEGMENT_NAME EXTENTS INITIAL_EXTENT NEXT_EXTENT PCT_INCREASE
------------ ---------- -------------- ----------- ------------
EMP 1 65536 65536 50
SQL> select segment_name,extent_id,block_id,bytes,blocks
2 from dba_extents
3 where owner='SCOTT' and segment_name='EMP';
4 order by 2,3;
SEGMENT_NAME EXTENT_ID BLOCK_ID BYTES BLOCKS
------------ ---------- ---------- ---------- ----------
EMP 0 33945 65536 8
================================================================================================
* Free space 관리
tablespace내에 free space를 먼저 확인해본다.
SQL> select * from dba_free_space
2 where tablespace_name ='DATA01' order by 1,2,3;
TABLESPACE FILE_ID BLOCK_ID BYTES BLOCKS RELATIVE_FNO
---------- ---------- ---------- ---------- ---------- ------------
DATA01 8 7 999424 122 8
테이블을 여러개 생성해보자.
SQL> create table scott.dept2 tablespace data01 as select * from scott.dept;
SQL> create table scott.dept3 tablespace data01 as select * from scott.dept;
SQL> create table scott.dept4 tablespace data01 as select * from scott.dept;
SQL> create table scott.dept5 tablespace data01 as select * from scott.dept;
SQL> create table scott.dept6 tablespace data01 as select * from scott.dept;
SQL> select * from dba_free_space
2 where tablespace_name ='DATA01' order by 1,2,3;
TABLESPACE FILE_ID BLOCK_ID BYTES BLOCKS RELATIVE_FNO
---------- ---------- ---------- ---------- ---------- ------------
DATA01 8 32 794624 97 8
사용함에 따라 tablespace내 free space 가 줄어듦을 알 수 있다.
SQL> drop table scott.dept2;
drop table dept2
*
ERROR at line 1:
ORA-04098: trigger 'SYS.JIS$ROLE_TRIGGER$' is invalid and failed re-validation
이건 또 뭐야 ? trigger가 걸려있네요...
table drop 을 위해
SQL> alter trigger SYS.JIS$ROLE_TRIGGER$ disable;
drop table scott.dept3; ==> dept4 만 빼고 전부 drop
drop table scott.dept5;
drop table scott.dept6;
SQL> select * from dba_free_space
2 where tablespace_name ='DATA01' order by 1,2,3;
TABLESPACE FILE_ID BLOCK_ID BYTES BLOCKS RELATIVE_FNO
---------- ---------- ---------- ---------- ---------- ------------
DATA01 8 7 40960 5 8
DATA01 8 32 794624 97 8
tablespace의 free space가 늘긴 했는데 쪼개졌네요..
빈공간을 병합하자
SQL> alter tablespace data01 coalesce;
SQL> select * from dba_free_space
2 where tablespace_name ='DATA01' order by 1,2,3;
TABLESPACE FILE_ID BLOCK_ID BYTES BLOCKS RELATIVE_FNO
---------- ---------- ---------- ---------- ---------- ------------
DATA01 8 7 40960 5 8
DATA01 8 32 794624 97 8
그래도 두개로 쪼개져 있는 이유는? 중간에 dept4 가 사용하는 space가 coalesce 되지 않았기 때문
SQL> drop table scott.dept4;
SQL> alter tablespace data01 coalesce;
완전히 병합되었다.
================================================================================================
10. Managing Rollback Segments
================================================================================================
* rollback segment의 정보 조회
SQL> col owner format a10
SQL> col segment_name format a12
SQL> col segment_type format a12
SQL> col tablespace_name format a10
SQL> col status format a7
SQL> select segment_name,tablespace_name,status,initial_extent,next_extent,min_extents
2 from dba_rollback_segs;
SEGMENT_NAME TABLESPACE STATUS INITIAL_EXTENT NEXT_EXTENT MIN_EXTENTS
------------ ---------- ------- -------------- ----------- -----------
SYSTEM SYSTEM ONLINE 57344 57344 2
RBS0 RBS ONLINE 524288 524288 8
RBS1 RBS ONLINE 524288 524288 8
RBS2 RBS ONLINE 524288 524288 8
RBS3 RBS ONLINE 524288 524288 8
RBS4 RBS ONLINE 524288 524288 8
RBS5 RBS ONLINE 524288 524288 8
RBS6 RBS ONLINE 524288 524288 8
================================================================================================
* rollback segment 생성
SQL> create rollback segment rbs99
2 tablespace rbs
3 storage(initial 20k next 20k minextents 2 optimal 80k);
Rollback segment created.
SQL> select segment_name,tablespace_name,status,initial_extent,next_extent,min_extents
2 from dba_rollback_segs;
SEGMENT_NAME TABLESPACE STATUS INITIAL_EXTENT NEXT_EXTENT MIN_EXTENTS
------------ ---------- ------- -------------- ----------- -----------
SYSTEM SYSTEM ONLINE 57344 57344 2
RBS0 RBS ONLINE 524288 524288 8
RBS1 RBS ONLINE 524288 524288 8
RBS2 RBS ONLINE 524288 524288 8
RBS3 RBS ONLINE 524288 524288 8
RBS4 RBS ONLINE 524288 524288 8
RBS5 RBS ONLINE 524288 524288 8
RBS6 RBS ONLINE 524288 524288 8
RBS99 RBS OFFLINE 24576 32768 2
추가되었다. online으로 전환하자.
SQL> alter rollback segment rbs99 online;
SQL> create table emp2 as select * from emp;
SQL> select name,extents,xacts,shrinks,optsize
2 from v$rollname n, v$rollstat s
3 where n.usn = s.usn;
NAME EXTENTS XACTS SHRINKS OPTSIZE
--------------------- ----------- ---------- ---------- ----------
SYSTEM 9 0 0
RBS0 8 0 0 4194304
RBS1 8 0 0 4194304
RBS2 8 0 0 4194304
RBS3 8 0 0 4194304
RBS4 8 0 0 4194304
RBS5 8 0 0 4194304
RBS6 8 0 0 4194304
RBS99 2 0 0 81920 ==> extents,xacts의 변화 관찰
SQL> set transaction use rollback segment rbs99;
SQL> update emp2 set hiredate=sysdate;
SQL> select name,extents,xacts,shrinks,optsize
2 from v$rollname n, v$rollstat s
3 where n.usn = s.usn;
NAME EXTENTS XACTS SHRINKS OPTSIZE
--------------- ---------- ---------- ---------- ----------
SYSTEM 9 0 0
RBS0 8 0 0 4194304
RBS1 8 0 0 4194304
RBS2 8 0 0 4194304
RBS3 8 0 0 4194304
RBS4 8 0 0 4194304
RBS5 8 0 0 4194304
RBS6 8 0 0 4194304
RBS99 2 1 0 81920 ==> transaction이 시작됨
SQL> update emp2 set hiredate=sysdate-1;
sql> insert into emp2 select * from emp2; ==> 엄청 많이 수행 하자.
SQL> select name,extents,xacts,shrinks,optsize
2 from v$rollname n, v$rollstat s
3 where n.usn = s.usn;
NAME EXTENTS XACTS SHRINKS OPTSIZE
--------------- ---------- ---------- ---------- ----------
SYSTEM 9 0 0
RBS0 8 0 0 4194304
RBS1 8 0 0 4194304
RBS2 8 0 0 4194304
RBS3 8 0 0 4194304
RBS4 8 0 0 4194304
RBS5 8 0 0 4194304
RBS6 8 0 0 4194304
RBS99 3 1 0 81920 ==> extents 증가
SQL> rollback;
SQL> set transaction use rollback segment rbs99;
SQL> update emp2 set sal=1000;
SQL> select name,extents,xacts,shrinks,optsize
2 from v$rollname n, v$rollstat s
3 where n.usn = s.usn;
NAME EXTENTS XACTS SHRINKS OPTSIZE
--------------- ---------- ---------- ---------- ----------
SYSTEM 9 0 0
RBS0 8 0 0 4194304
RBS1 8 0 0 4194304
RBS2 8 0 0 4194304
RBS3 8 0 0 4194304
RBS4 8 0 0 4194304
RBS5 8 0 0 4194304
RBS6 8 0 0 4194304
RBS99 3 1 0 81920 ==> automatic 하게 shrink되었는지 확인
이전 tranx은 종료되었고 새로운 tranx가 시작됨
================================================================================================
* rollback segment 삭제
SQL> rollback;
SQL> select name,extents,xacts,shrinks,optsize
2 from v$rollname n, v$rollstat s
3 where n.usn = s.usn; ==> xacts 가 '0' 인지 먼저 확인
SQL> alter rollback segment rbs99 offline;
SQL> drop rollback segment rbs99;
SQL> select segment_name,tablespace_name,status,initial_extent,next_extent,min_extents
2 from dba_rollback_segs;
SEGMENT_NAME TABLESPACE STATUS INITIAL_EXTENT NEXT_EXTENT MIN_EXTENTS
------------ ---------- ------- -------------- ----------- -----------
SYSTEM SYSTEM ONLINE 57344 57344 2
RBS0 RBS ONLINE 524288 524288 8
RBS1 RBS ONLINE 524288 524288 8
RBS2 RBS ONLINE 524288 524288 8
RBS3 RBS ONLINE 524288 524288 8
RBS4 RBS ONLINE 524288 524288 8
RBS5 RBS ONLINE 524288 524288 8
RBS6 RBS ONLINE 524288 524288 8
확인해보니 삭제되었다.
================================================================================================
11.Managing Tables
================================================================================================
* Temporary Table
a. on commit perserve rows : session내에서 생성한 temp table에 대해서 지속적.
새로운 session 연결 되면 data 지워짐
Example : Creating a Session-Specific Temporary Table
CREATE GLOBAL TEMPORARY TABLE ...
[ON COMMIT PRESERVE ROWS ]
b. on commit delete rows : tansaction이 끝나면 temp table 내의 data가 지워짐(commit,rollback등)
Example : Creating a Transaction-Specific Temporary Table
CREATE GLOBAL TEMPORARY TABLE ...
[ON COMMIT DELETE ROWS ]
================================================================================================
* Using Temporary Tables to Improve Performance
You can use temporary tables to improve performance when you run complex queries.
Running multiple such queries is relatively slow because the tables are accessed multiple times
for each returned row. It is faster to cache the values from a complex query in a temporary table,
then run the queries against the temporary table.
For example, even with a view like this defined to simplify further queries,
the queries against the view may be slow because the contents of the view are recalculated each time:
CREATE OR REPLACE VIEW Profile_values_view AS
SELECT d.Profile_option_name, d.Profile_option_id, Profile_option_value,
u.User_name, Level_id, Level_code
FROM Profile_definitions d, Profile_values v, Profile_users u
WHERE d.Profile_option_id = v.Profile_option_id
AND ((Level_code = 'USER' AND Level_id = U.User_id) OR
(Level_code = 'DEPARTMENT' AND Level_id = U.Department_id) OR
(Level_code = 'SITE'))
AND NOT EXISTS (SELECT 1 FROM PROFILE_VALUES P
WHERE P.PROFILE_OPTION_ID = V.PROFILE_OPTION_ID
AND ((Level_code = 'USER' AND
level_id = u.User_id) OR
(Level_code = 'DEPARTMENT' AND
level_id = u.Department_id) OR
(Level_code = 'SITE'))
AND INSTR('USERDEPARTMENTSITE', v.Level_code) >
INSTR('USERDEPARTMENTSITE', p.Level_code));
A temporary table allows us to run the computation once,
and cache the result in later SQL queries and joins:
CREATE GLOBAL TEMPORARY TABLE Profile_values_temp
(
Profile_option_name VARCHAR(60) NOT NULL,
Profile_option_id NUMBER(4) NOT NULL,
Profile_option_value VARCHAR2(20) NOT NULL,
Level_code VARCHAR2(10) ,
Level_id NUMBER(4) ,
CONSTRAINT Profile_values_temp_pk
PRIMARY KEY (Profile_option_id)
) ON COMMIT PRESERVE ROWS ORGANIZATION INDEX;
INSERT INTO Profile_values_temp
(Profile_option_name, Profile_option_id, Profile_option_value,
Level_code, Level_id)
SELECT Profile_option_name, Profile_option_id, Profile_option_value,
Level_code, Level_id
FROM Profile_values_view;
COMMIT;
Now the temporary table can be used to speed up queries,
and the results cached in the temporary table are freed automatically by the database
when the session ends.
================================================================================================
* Row Migration Test
scott/tiger로 접속해서
SQL> create table chain_test(col1 varchar2(100));
Table created.
SQL> insert into chain_test values('a');
1 row created.
SQL> insert into chain_test select * from chain_test; <====== 1 row created.
SQL> / <====== 2 rows created.
SQL> / <====== 4 rows created.
SQL> / <====== 8 rows created.
SQL> / <====== 16 rows created.
SQL> / <====== 32 rows created.
SQL> / <====== 64 rows created.
SQL> / <====== 128 rows created.
SQL> / <====== 256 rows created.
SQL> / <====== 512 rows created.
SQL> commit;
SQL> @$ORACLE_HOME/rdbms/admin/utlchain <====== chanined_rows table생성
Table created.
SQL> desc chained_rows
Name Null? Type
----------------------------------------- -------- ----------------------------
OWNER_NAME VARCHAR2(30)
TABLE_NAME VARCHAR2(30)
CLUSTER_NAME VARCHAR2(30)
PARTITION_NAME VARCHAR2(30)
SUBPARTITION_NAME VARCHAR2(30)
HEAD_ROWID ROWID
ANALYZE_TIMESTAMP DATE
SQL> analyze table chain_test list chained rows;
Table analyzed.
SQL> select count(*) from chained_rows;
COUNT(*)
----------
0 ======> 아직까지는 chaining이 하나도 없지...
SQL> update chain_test
2 set col1 = 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa';
1024 rows updated.
SQL> analyze table chain_test list chained rows;
Table analyzed.
SQL> select count(*) from chained_rows;
COUNT(*)
----------
995 ==============> row migration이 다량 발생
row migration이 일어나면 여러 block에서 읽어야 하므로 그만큼 performance가 떨어진다.
이를 해결하기 위해 주기적으로 analyze하여 확인해보고 insert를 다시 해주면 된다.
chaining이 일어난 row들의 rowid로 찾아서 임시table을 생성하고 원래 table에서 chaining이 일어난
data를 삭제하고 다시 insert하면 된다.
SQL> create table chain_tmp as select * from chain_test
2 where rowid in (select head_rowid from chained_rows where table_name='CHAIN_TEST');
SQL> delete from chain_test
2 where rowid in(select head_rowid from chained_rows where table_name='CHAIN_TEST');
SQL> insert into chain_test select * from chain_tmp;
SQL> commit;
다시 cahined_rows table 을 삭제하고 analyze해보자.
SQL> truncate table chained_rows;
Table truncated.
SQL> analyze table chain_test list chained rows;
Table analyzed.
SQL> select * from chained_rows; <====== no rows selected
chaining이 없어졌다.
================================================================================================
12. Managing Indexes
================================================================================================
1. B*Tree Index 생성, 확인
SQL> col table_name format a10
SQL> col index_name format a20
SQL> col index_type format a10
SQL> col column_name format a12
SQL> create index scott.dept_dname_ind on scott.dept(dname);
Index created.
SQL> create unique index scott.dept_deptno_uind on scott.dept(deptno);
create unique index scott.dept_deptno_uind on scott.dept(deptno)
*
ERROR at line 1:
ORA-01408: such column list already indexed
error가 난 이유는 column이 pk로 지정될때는 unique index가 자동으로 생성되기 때문.
user_constraints, user_cons_columns 등에서 확인해보면 알수있다.
SQL> select table_name,index_name,index_type,uniqueness
2 from dba_indexes
3 where owner='SCOTT';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENESS
---------- -------------------- ---------- ------------------
DEPT DEPT_DNAME_IND NORMAL NONUNIQUE ====> 생성한 index
AUDIT_ACTI I_AUDIT_ACTIONS NORMAL UNIQUE
ONS
DEPT PK_DEPT NORMAL UNIQUE
EMP PK_EMP NORMAL UNIQUE
DBMS_LOCK_ SYS_C001456 NORMAL UNIQUE
ALLOCATED
DBMS_ALERT SYS_C001457 NORMAL UNIQUE
_INFO
SQL> select table_name,index_name,column_position,column_name
2 from dba_ind_columns
3 where index_owner='SCOTT';
TABLE_NAME INDEX_NAME COLUMN_POSITION COLUMN_NAME
---------- -------------------- --------------- ------------
DEPT DEPT_DNAME_IND 1 DNAME ====> index가 걸린 column
AUDIT_ACTI I_AUDIT_ACTIONS 1 ACTION
ONS
AUDIT_ACTI I_AUDIT_ACTIONS 2 NAME
ONS
DEPT PK_DEPT 1 DEPTNO
EMP PK_EMP 1 EMPNO
DBMS_LOCK_ SYS_C001456 1 NAME
ALLOCATED
DBMS_ALERT SYS_C001457 1 NAME
_INFO
DBMS_ALERT SYS_C001457 2 SID
_INFO
================================================================================================
* Bitmap Index 생성, 확인
SQL> select count(*) from scott.emp;
SQL> select distinct job from scott.emp;
JOB
------------------
ANALYST
CLERK
MANAGER
PRESIDENT
SALESMAN
SQL> create bitmap index scott.emp_job_bind on scott.emp(job);
SQL> select table_name,index_name,index_type,uniqueness
2 from dba_indexes
3 where owner='SCOTT';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENESS
---------- -------------------- ---------- ------------------
DEPT DEPT_DNAME_IND NORMAL NONUNIQUE
EMP EMP_JOB_BIND BITMAP NONUNIQUE =====>
AUDIT_ACTI I_AUDIT_ACTIONS NORMAL UNIQUE
...
SQL> select table_name,index_name,column_position,column_name
2 from dba_ind_columns
3 where index_owner='SCOTT';
TABLE_NAME INDEX_NAME COLUMN_POSITION COLUMN_NAME
---------- -------------------- --------------- ------------
DEPT DEPT_DNAME_IND 1 DNAME
EMP EMP_JOB_BIND 1 JOB =====>
AUDIT_ACTI I_AUDIT_ACTIONS 1 ACTION
ONS
================================================================================================
* Reverse Key Index 생성, 확인
SQL> create index scott.emp_hiredate_rind on scott.emp(hiredate) reverse;
SQL> select table_name,index_name,index_type,uniqueness
2 from dba_indexes
3 where owner='SCOTT';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENESS
---------- -------------------- ---------- ------------------
DEPT DEPT_DNAME_IND NORMAL NONUNIQUE
EMP EMP_HIREDATE_RIND NORMAL/REV NONUNIQUE ==>
EMP EMP_JOB_BIND BITMAP NONUNIQUE
....
SQL> select table_name,index_name,column_position,column_name
2 from dba_ind_columns
3 where index_owner='SCOTT';
TABLE_NAME INDEX_NAME COLUMN_POSITION COLUMN_NAME
---------- -------------------- --------------- ------------
DEPT DEPT_DNAME_IND 1 DNAME
EMP EMP_HIREDATE_RIND 1 HIREDATE ==>
EMP EMP_JOB_BIND 1 JOB
....
================================================================================================
* Funtion-Based Index 생성, 확인 <===== Query Rewrite권한 필요
SQL> create index scott.emp_sal_find on scott.emp(sal * 1.1);
SQL> select table_name,index_name,index_type,uniqueness
2 from dba_indexes
3 where owner='SCOTT';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENESS
---------- -------------------- ---------- ------------------
DEPT DEPT_DNAME_IND NORMAL NONUNIQUE
EMP EMP_HIREDATE_RIND NORMAL/REV NONUNIQUE
EMP EMP_JOB_BIND BITMAP NONUNIQUE
EMP EMP_SAL_FIND FUNCTION-B NONUNIQUE ==>
ASED NORMA
L
....
SQL> select table_name,index_name,column_position,column_name
2 from dba_ind_columns
3 where index_owner='SCOTT';
TABLE_NAME INDEX_NAME COLUMN_POSITION COLUMN_NAME
---------- -------------------- --------------- ------------
DEPT DEPT_DNAME_IND 1 DNAME
EMP EMP_HIREDATE_RIND 1 HIREDATE
EMP EMP_JOB_BIND 1 JOB
EMP EMP_SAL_FIND 1 SYS_NC00009$ ====> column name이 내부적으로 바뀐다.
....
================================================================================================
* Index drop
SQL> drop index scott.dept_dname_ind;
SQL> drop index scott.emp_hiredate_rind;
SQL> drop index scott.emp_job_bind;
SQL> drop index scott.emp_sal_find;
================================================================================================
13.Maintaining Data Integrity
================================================================================================
* PK/UK 와 Unique Index
SQL> desc scott.dept
Name Null? Type
----------------------------------------- -------- ----------------------------
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
PK생성은 다음과 같이 할 수 있다.
SQL> alter table scott.dept
2 add constraint dept_deptno_pk primary key(deptno);
add constraint dept_deptno_pk primary key(deptno)
*
ERROR at line 2:
ORA-02260: table can have only one primary key
이미 pk가 설정이 되어있어서 한테이블에 두개의 pk를 설정할 수 없다는 error.
SQL> alter table scott.dept
2 add constraint dept_dname_uk unique (dname);
Table altered.
SQL> select table_name,constraint_name,constraint_type, status
2 from dba_constraints
3 where owner='SCOTT';
TABLE_NAME CONSTRAINT_NAME CO STATUS
-------------------- --------------- -- ----------------
DEPT DEPT_DNAME_UK U ENABLED <=== 새로 생성한 UK
EMP FK_DEPTNO R ENABLED
DEPT PK_DEPT P ENABLED
EMP PK_EMP P ENABLED
AUDIT_ACTIONS SYS_C001454 C ENABLED
AUDIT_ACTIONS SYS_C001455 C ENABLED
DBMS_LOCK_ALLOCATED SYS_C001456 P ENABLED
DBMS_ALERT_INFO SYS_C001457 P ENABLED
SQL> select table_name,index_name,index_type,uniqueness
2 from dba_indexes
3 where owner='SCOTT';
TABLE_NAME INDEX_NAME INDEX_TYPE UNIQUENESS
---------- -------------------- ---------- ------------------
DEPT DEPT_DNAME_UK NORMAL UNIQUE <==
AUDIT_ACTI I_AUDIT_ACTIONS NORMAL UNIQUE
ONS
SQL> select table_name,index_name,column_position,column_name
2 from dba_ind_columns
3 where index_owner='SCOTT';
TABLE_NAME INDEX_NAME COLUMN_POSITION COLUMN_NAME
---------- -------------------- --------------- ------------
DEPT DEPT_DNAME_UK 1 DNAME <==
AUDIT_ACTI I_AUDIT_ACTIONS 1 ACTION
ONS
================================================================================================
* Constraint Check
SQL> insert into scott.dept values(50,'HR','SEOUL');
1 row created.
SQL> commit;
Commit complete.
SQL> insert into scott.dept values(50,'HR Dept','SEOUL');
insert into scott.dept values(50,'HR Dept','SEOUL')
*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.PK_DEPT) violated
UK 값에 같은 값 insert하려다가 error가 난다.
================================================================================================
* Constriaint 비활성화/활성화
SQL> alter table scott.dept
2 disable constraint dept_dname_uk;
SQL> alter table scott.dept
2 enable constraint dept_dname_uk;
================================================================================================
* Deferred Constraint(?) ==> 자료좀 찾아보자..
================================================================================================
* Constraint 삭제
alter table <테이블명> drop constraint
================================================================================================
14. Loading Data
================================================================================================
* 사용법
Usage: SQLLOAD keyword=value [,keyword=value,...]
Valid Keywords:
userid -- ORACLE username/password
control -- Control file name
log -- Log file name
bad -- Bad file name
data -- Data file name
discard -- Discard file name
discardmax -- Number of discards to allow (Default all)
skip -- Number of logical records to skip (Default 0)
load -- Number of logical records to load (Default all)
errors -- Number of errors to allow (Default 50)
rows -- Number of rows in conventional path bind array or between direct path data saves
(Default: Conventional path 64, Direct path all)
bindsize -- Size of conventional path bind array in bytes (Default 65536)
silent -- Suppress messages during run (header,feedback,errors,discards,partitions)
direct -- use direct path (Default FALSE)
parfile -- parameter file: name of file that contains parameter specifications
parallel -- do parallel load (Default FALSE)
file -- File to allocate extents from
skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE)
skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE)
commit_discontinued -- commit loaded rows when load is discontinued (Default FALSE)
readsize -- Size of Read buffer (Default 1048576)
PLEASE NOTE: Command-line parameters may be specified either by
position or by keywords. An example of the former case is 'sqlload
scott/tiger foo'; an example of the latter is 'sqlload control=foo
userid=scott/tiger'. One may specify parameters by position before
but not after parameters specified by keywords. For example,
'sqlload scott/tiger control=foo logfile=log' is allowed, but
'sqlload scott/tiger control=foo log' is not, even though the
position of the parameter 'log' is correct.
================================================================================================
* case 별로 sqlldr을 사용하는법은
http://technet.oracle.com/doc/server.815/a67792/ch04.htm#1364
에 자세히 나와있다. 그중 두가지 정도의 case만 기본적으로 다루어보자.
================================================================================================
* case1 : data를 control file에 직접 입력하여 load하기
a. data 입력될 table 있어야함 (dept_tmp 라는 table을 생성하여 입력해보자)
SQL> create table dept_tmp as select * from dept;
Table created.
SQL> truncate table dept_tmp;
Table truncated.
b. control file을 구성한다.
load data
infile * ==> data 가 ctl file 끝에 있다는 의미
replace ==> 이게 없으면 빈테이블일때만 load된다.
into table dept_tmp
fileds terminated by ',' optionally enclosed by '"' ==> field 구분자와 "가 들어가면 빼고 입력된다.
(deptno,dname,loc)
begindata
12,research,"saratoga"
10,"accounting",cleveland
11,"art","salem"
13,finance,boston
c. 다음과 같이 sqlldr을 실행
oracle@swsvrctr:/home/oracle> sqlldr scott/tiger control=test.ctl log=test.log bad=test.bad
error가 생기면 log가 남고 loading 되지 않은 data만 bad file에 남는다.
================================================================================================
* case 2 : Fixed-format records의 Loading
a. data 입력될 table 있어야함 (dept_tmp 라는 table을 생성하여 입력해보자)
SQL> create table emp_tmp as select * from emp;
Table created.
b. data file의 내용을 보고 그에 맞게 control file을 구성한다.
data file은 다음과 같다고 하자.
1111 joo Manager 1111 19191.00 10
2222 hwang salesman 2222 294974.50 20
3333 test test 3333 4984.00 40
4444 kwon engineer 4444 49.90 50
control file을 만들어보자.
load data
infile '/home/oracle/test.dat'
replace
into table emp_tmp
(empno position(01:04) integer external, ==> position을 일일이 맞추어 준다.
ename position(09:14) char,
job position(17:24) char,
mgr position(33:36) integer external,
sal position(41:49) decimal external,
comm position(51:54) decimal external,
deptno position(57:58) integer external)
주의 : data file의 data가 공백이 아닌 tab 으로 되어있으면 position에서 한칸으로 인식되니까 주의
c. 다음과 같이 sqlldr을 실행
home/oracle> sqlldr scott/tiger control=test.ctl data=test.dat log=test.log bad=test.bad
================================================================================================
15. Reorganizing Data
================================================================================================
* 오래 사용한 table 주로 DML성 문장이 자주 일어나 performance에 영향을 미치므로 주기적으로
Reorganize 를 해주는것이 좋다.
Export => table drop => import 순으로 한다.
export 는 user 별로 table별로 받을 수 있다.
a. Export
oracle@swsvrctr:/home/oracle> exp scott/tiger tables='dept,emp' file=test.dmp
Export: Release 8.1.6.0.0 - Production on Wed Jul 4 14:32:21 2001
(c) Copyright 1999 Oracle Corporation. All rights reserved.
Connected to: Oracle8i Enterprise Edition Release 8.1.6.0.0, 64 bit - Production
With the Partitioning option
JServer Release 8.1.6.0.0 - Production
Export done in KO16KSC5601 character set and WE8ISO8859P1 NCHAR character set
server uses WE8ISO8859P1 character set (possible charset conversion)
About to export specified tables via Conventional Path ...
. . exporting table DEPT 7 rows exported
. . exporting table EMP 14 rows exported
Export terminated successfully without warnings.
b. drop table
oracle@swsvrctr:/home/oracle> sqlplus scott/tiger
SQL> drop table emp;
SQL> drop table dept;
c. Import
oracle@swsvrctr:/home/oracle> imp scott/tiger tables='dept,emp' file=test.dmp
Import: Release 8.1.6.0.0 - Production on Wed Jul 4 14:34:25 2001
(c) Copyright 1999 Oracle Corporation. All rights reserved.
Connected to: Oracle8i Enterprise Edition Release 8.1.6.0.0, 64 bit - Production
With the Partitioning option
JServer Release 8.1.6.0.0 - Production
Export file created by EXPORT:V08.01.06 via conventional path
import done in KO16KSC5601 character set and WE8ISO8859P1 NCHAR character set
import server uses WE8ISO8859P1 character set (possible charset conversion)
. importing SCOTT's objects into SCOTT
. . importing table "DEPT" 7 rows imported
. . importing table "EMP" 14 rows imported
About to enable constraints...
Import terminated successfully without warnings.
d. 제대로 되었나 조회
SQL> select * from dept;
SQL> select * from emp;
================================================================================================
16. Managing Password Security and Resources
================================================================================================
* verify_function 생성을 위해 돌려줘야 할 script : $ORACLE_HOME/rdbms/admin/utlpwdmg.sql
NAME
utlpwdmg.sql - script for Default Password Resource Limits
DESCRIPTION
This is a script for enabling the password management features
by setting the default password resource limits.
NOTES
This file contains a function for minimum checking of password
complexity. This is more of a sample function that the customer
can use to develop the function for actual complexity checks that the
customer wants to make on the new password.
MODIFIED (MM/DD/YY)
asurpur 04/17/97 - Fix for bug479763
asurpur 12/12/96 - Changing the name of password_verify_function
asurpur 05/30/96 - New script for default password management
asurpur 05/30/96 - Created
================================================================================================
* verify_function 생성 및 패스워드 관리기능 활성화
SQL> @$ORACLE_HOME/rdbms/admin/utlpwdmg
Function created.
Profile altered.
================================================================================================
* 사용자 생성
utlpwdmg.sql script를 돌려 verify_function을 생성후 user를 생성할때는 몇가지를 check하여 좀더
password 관리를 할 수 있도록 해준다.
다음과 같이 user/passwd를 같게 하면 error가 나서 생성되지 않는다.
SQL> create user myuser identified by myuser
2 default tablespace TS_USER1
3 temporary tablespace TEMP;
create user myuser identified by myuser
*
ERROR at line 1:
ORA-28003: password verification for the specified password failed
ORA-20001: Password same as user
다시 시도
SQL> create user myuser identified by mypasswd9$
2 default tablespace ts_user1
3 temporary tablespace temp;
User created.
SQL> grant connect,resource to myuser;
확인
SQL> connect myuser/mypasswd9$
================================================================================================
* 패스워드 관리/ expire 시키기
SQL> alter user myuser password expire;
User altered.
admin이 강제로 expire시켰기 때문에 다음과 같이 password변경을 뭍는다.
SQL> connect myuser/mypassword9$
Changing password for test
New password:
Retype new password:
Password changed
Connected.
password를 또 규칙에 맞지 않게 넣으면 다음과 같은 error가 발생한다.
ERROR:
ORA-00988: missing or invalid password(s)
================================================================================================
* dictionary 조회
SQL> select resource_name,limit from dba_profiles
2 where profile='DEFAULT' and resource_type='PASSWORD';
RESOURCE_NAME LIMIT
-------------------- ---------------
FAILED_LOGIN_ATTEMPT 3
S
PASSWORD_LIFE_TIME 60
PASSWORD_REUSE_TIME 1800
PASSWORD_REUSE_MAX UNLIMITED
PASSWORD_VERIFY_FUNC VERIFY_FUNCTION
TION
PASSWORD_LOCK_TIME .0006
PASSWORD_GRACE_TIME 10
RESOURCE_NAME LIMIT
-------------------- ---------------
FAILED_LOGIN_ATTEMPT 3
S
PASSWORD_LIFE_TIME 60
PASSWORD_REUSE_TIME 1800
PASSWORD_REUSE_MAX UNLIMITED
PASSWORD_VERIFY_FUNC VERIFY_FUNCTION
TION
PASSWORD_LOCK_TIME .0006
PASSWORD_GRACE_TIME 10
================================================================================================
17. Managing Users
================================================================================================
* OS 인증 : os에 login 한 id/passwd로 oracle의 id/passwd로 함께 사용하기 위한방법
a. user를 생성하는데 identified externally로 생성한다.
oracle@swsvrctr:/home/oracle> sqlplus internal
SQL> create user oracle identified externally
2 default tablespace ts_user1
3 temporary tablespace temp;
User created.
SQL> grant connect,resource to oracle;
SQL> revoke unlimited tablespace from oracle;
SQL> shutdown immediate
b. init
os_authent_prefix=""
c. startup하고 확인해본다.
SQL> startup
SQL> exit
oracle@swsvrctr:/home/oracle> sqlplus / ==> id/passwd를 넣을 필요없이 접속
SQL> select user from dual;
USER
------------------------------------------------------------
ORACLE
제대로 접속이 된다.
================================================================================================
* tablespace 사용량 통제
SQL> connect internal
Connected.
SQL> col tablespacename format a10
SQL> col username format a10
SQL> alter user oracle quota 20k on ts_user1; ==> oracle user는 ts_user1에 20k 만 사용 가능하다.
User altered.
SQL> select * from dba_ts_quotas;
TABLESPACE_NAME USERNAME
------------------------------------------------------------ ----------
BYTES MAX_BYTES BLOCKS MAX_BLOCKS
---------- ---------- ---------- ----------
TS_USER1 ORACLE
0 20480 0 5
SQL> connect /
Connected.
SQL> select user from dual;
USER
------------------------------------------------------------
ORACLE
SQL> create table test
2 (id number(10))
3 (tablespace ts_user1
4 storage(initial 20k)
까지는 생성이 되나 다음과 같이 늘리려고 하면 error가 난다.
SQL> alter table test allocate extent(size 4k); ==> error
================================================================================================
18. Managing Privileges
================================================================================================
* with grant option과 with admin option
(둘다 실행 권한을 받은 user가 다시 실행 권한을 다른 user에게 줄 수 있게 해주는 option이다.)
-- 차이는 with admin option으로 권한을 받은 user1이 다른 user2에게 권한을 부여한 후 user1으로부터
권한을 revoke하면 user1의 권한만 revoke되나
with grant option으로 부여하면 user1에게 revoke 될 시 user2의 권한도 cascade로 revoke된다.
oracle@swsvrctr:/home/oracle> sqlplus internal
SQL> col grantor format a10
SQL> col grantee format a10
SQL> col table_name format a10
SQL> col table_schema format a10
SQL> col privilege format a25
SQL> grant create user to scott with admin option; ==> with admin option으로 권한 부여후
SQL> connect scott/tiger
SQL> grant create user to oracle; ==> 다시 oracle 에게 같은 권한 부여후
SQL> connect internal
SQL> select * from dba_sys_privs
2 where grantee in ('SCOTT','ORACLE');
GRANTEE PRIVILEGE ADMIN_
---------- ------------------------- ------
ORACLE CREATE USER NO
SCOTT CREATE USER YES
SCOTT UNLIMITED TABLESPACE NO
SQL> revoke create user from scott; ==> scott의 권한을 revoke
SQL> select * from dba_sys_privs
2 where grantee in ('SCOTT','ORACLE');
GRANTEE PRIVILEGE ADMIN_
---------- ------------------------- ------
ORACLE CREATE USER NO ==> scott의 create user 권한만 revoke되었다.
SCOTT UNLIMITED TABLESPACE NO oracle권한은 그대로
SQL> grant select on dept to oracle with grant option; ==> with grant option 으로 권한 부여후
SQL> connect /
SQL> create user myuser identified by myuser1$
2 default tablespace ts_user1
3 temporary tablespace temp;
SQL> grant select on scott.dept to myuser; ==> 다시 같은 권한을 다른 myuser에게 부여
Grant succeeded.
SQL> select * from all_tab_privs
2 where table_name='DEPT';
GRANTOR GRANTEE TABLE_SCHE TABLE_NAME PRIVILEGE GRANTA
---------- ---------- ---------- ---------- ------------------------- ------
SCOTT ORACLE SCOTT DEPT SELECT YES
ORACLE MYUSER SCOTT DEPT SELECT NO
SQL> revoke select on dept from oracle; ==> oracle의 권한을 revoke
Revoke succeeded.
SQL> select * from all_tab_privs ==> with grant option으로 생성된 이하 myuser의 권한도
2 where table_name='DEPT'; revoke 되었다.
no rows selected
================================================================================================
* Database Auditing : user 사용 시간정보 확인, 동시사용자측정 등 여러가지에 필요
SQL> connect internal
SQL> shutdown immediate
init
audit_trail = true # if you want auditing ==> 주석기호(#) 삭제
SQL> startup
SQL> show parameter audit_trail
NAME TYPE VALUE
------------------------------------ -------------- ------------------------------
audit_trail string TRUE
SQL> audit connect;
SQL> select * from dba_stmt_audit_opts;
USER_NAME PROXY_NAME AUDIT_OPTION SUCCESS FAILURE
-------------------- -------------------- --------------- ---------- ----------
CREATE SESSION BY ACCESS BY ACCESS
SQL> connect scott/tiger
SQL> connect scott/fail
SQL> connect internal
SQL> select username,timestamp,action_name,logoff_time,returncode
2 from dba_audit_session;
USERNAME TIMESTAMP ACTION_NAME LOGOFF_TI RETURNCODE
---------- --------- --------------- --------- ----------
SCOTT 05-JUL-01 LOGOFF 05-JUL-01 0 ==> login 성공하면 0 return
SCOTT 05-JUL-01 LOGON 1017 ==> login 실패한 returncode
SQL> shutdown
파라미터 이전대로 돌려두자(#audit_trail=true : 주석처리)
SQL> startup 하고
SQL> show parameter audit_trail
NAME TYPE VALUE
------------------------------------ -------------- ------------------------------
audit_trail string NONE
================================================================================================
19. Managing Roles
================================================================================================
* Role
resource role에 포함된 권한을 살펴보자
SQL> select * from dba_sys_privs
2 where grantee='RESOURCE';
GRANTEE PRIVILEGE ADMIN_
---------- -------------------- ------
RESOURCE CREATE CLUSTER NO
RESOURCE CREATE INDEXTYPE NO
RESOURCE CREATE OPERATOR NO
RESOURCE CREATE PROCEDURE NO
RESOURCE CREATE SEQUENCE NO
RESOURCE CREATE TABLE NO
RESOURCE CREATE TRIGGER NO
RESOURCE CREATE TYPE NO
8 rows selected.
다음은 dev라는 role을 만들어서
SQL> create role dev;
SQL> grant create table,create view to dev;
SQL> grant select on emp to dev;
SQL> connect internal
oracle이라는 user에게 dev,resource role, create session권한 부여
SQL> connect internal
SQL> grant dev to oracle;
SQL> grant resource to oracle;
SQL> grant create session to oracle;
SQL> alter user oracle default role resource; ==> session의 연결 끊김에 상관없이 지속적으로
SQL> grant select_catalog_role to oracle; logon 후 resource role이 enable되게 함
(set 할 필요 없이)
SQL> select segment_name,status from dba_rollback_segs; ==> 현재 session에서 select_catalog_role이
select segment_name,status from dba_rollback_segs disabled됨
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> set role select_catalog_role; ==> set은 현재session에서 role을 사용가능하게 해줌.
이를 위해 이 role은 이미 user에게 grant 되어있어야함.
SQL> select segment_name,status from dba_rollback_segs;
--------------- --------------------------------
SEGMENT_NAME STATUS
SYSTEM ONLINE
RBS1 ONLINE
RBS2 ONLINE
================================================================================================
20. Using National Language Support
================================================================================================
* sysdate format 변경
SQL> connect internal
SQL> select sysdate from dual;
SYSDATE
---------
05-JUL-01
SQL> alter session set nls_date_format='YY/MM/DD:HH24:MI:SS';
SQL> select sysdate from dual;
SYSDATE
-----------------
01/07/05:12:25:37
================================================================================================
* Character set 변경하고 한글명 table 만들기
-- 가급적 한글명 table은 만들지 않는것이 좋으나 만들수 없는것은 아니다.
SQL> create table scott.부서 as select scott.dept;
create table scott.부서 as select scott.dept
*
ERROR at line 1:
ORA-00911: invalid character ==> 테이블명이 한글이어서 error난다.
* Database Characterset을 변경해 보자. ==> 매우 조심스러운 작업
(DATA 보존 못할 위험성 있다.backup 필요)
SQL> select * from nls_database_parameters ==> nls_database_parameters 에서 현재 DB의
2 where parameter like '%CHARACTERSET%'; characterset관련을 parameter를 확인
PARAMETER VALUE
------------------------- --------------------
NLS_CHARACTERSET WE8ISO8859P1
NLS_NCHAR_CHARACTERSET WE8ISO8859P1
SQL> select value from v$nls_valid_values ==> 234건의 data가 있다.
2 where parameter like '%CHARACTERSET';
-- warning : character set을 변경 할수는 있지만 기존에 들어가있는 데이타에 대해서는 책임 못짐.
a.
SQL> shutdown immediate
SQL> connect internal
SQL> startup mount exclusive;
SQL> alter system enable restricted session;
SQL> alter database open;
b.
SQL> alter database character set ko16ksc5601;
SQL> alter database national chartacter charcter set ko16ksc5601;
-- 확인
SQL> select * from nls_database_parameters ==> nls_database_parameters 에서 현재 DB의
2 where parameter like '%CHARACTERSET%'; characterset관련을 parameter를 확인
shutdown immediate;
c. .profile edit
NLS_LANG=Amerian_America.us7ascii; export NLS_LANG을
NLS_LANG=korean_korea.ko16ksc5601; export NLS_LANG로 변경
d. Database startup
출처 : http://www.xguru.pe.kr/techbrd/read.cgi?board=ksko&y_number=6
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
|---|---|
| ORA-04031 에러 : 메모리 단편화 (0) | 2006.05.09 |
| Oracle 장애의 유형과 문제해결 (0) | 2006.03.15 |
| 오라클 SID변경 작업 (0) | 2006.03.09 |
| [펌] isqlplusdba / 브라우저에서 dba 로 접속하기!!! (0) | 2005.05.25 |
장애의 유형과 문제해결
※ SCENARIO 0 : Tablespace의 조작
※ SCENARIO 1 : Online Redo Log의 Mirroring
※ SCENARIO 2 : Full Offline Backup 수행
※ SCENARIO 3 : Recovery - Temporary Tablespace의 유실
※ SCENARIO 4 : Noarchive Log Mode Recovery - Disk의 유실
※ SCENARIO 5 : Read Only Tablespace의 Backup & Recovery
※ SCENARIO 6 : DATABASE의 BACKUP - Control File Mirroring & Archive log mode
※ SCENARIO 7 : Complete Recovery(Archive) - User의 DATA FILE 유실
※ SCENARIO 8 : Complete Recovery(ARchive) - Tablespace Recovery
※ SCENARIO 9 : Complete Recovery(ARchive) - Datafile Recovery
※ SCENARIO 10 : Parallel Recovery(Archive)
※ SCENARIO 11 : Complete Recovery - Shutdown 하지 않고 Data File만 Recovery
※ SCENARIO 12 : Online Backup (Hot Backup)
※ SCENARIO 13 : Online Backup 실패 후 Recovery - Online Backup 도중에 정전
※ SCENARIO 14 : Incomplete Recovery(Noarchive) - 실수로 Drop한 Table의 복구
※ SCENARIO 15 : Inactive Online Redo Log Group의 유실
※ SCENARIO 16 : Current Online Redo Log Group의 유실
※ SCENARIO 17 : 모든 Online Redo Log Group의 유실
※ SCENARIO 18 : 모든 Redo Log & Data File 유실
※ SCENARIO 19 : Control File Recreate
※ SCENARIO 20 : 모든 Control File 유실
※ SCENARIO 21 : Control File과 Data File 동시에 유실
※ SCENARIO 22 : Read Only Tablespace의 상태변경에 따른 Recovery -1
※ SCENARIO 23 : Read Only Tablespace의 상태변경에 따른 Recovery -2
※ SCENARIO 24 : Read Only Tablespace의 상태변경에 따른 Recovery -3
※ SCENARIO 25 : Recovery from Online Backup - Data File, Control File 유실
※ SCENARIO 26 : Recovery from Online Backup - File들 모두가 사라졌다.
게다가, Archived Redo Log File의 일부가 없고,
Data File Backup도 일부 없다.
※ SCENARIO 27 : Recover with No Backup
※ SCENARIO 28 : Incremental export 와 direct path
※ SCENARIO 29 : standby database 생성
※ SCENARIO 30 : Catalog DB를 이용한 복구 Oracle8
<SCENARIO 0 : Tablespace의 조작>
① 새로운 Tablespace Create
[/DBA3/DBA/dba숫자]svrmgrl
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> create tablespace test
2> datafile '/DBA3/DBA/dba숫자/u01/test_01.dbf'
3> size 10k;
SVRMGR> select tablespace_name, bytes, file_name from dba_data_files;
② Table Create
SVRMGR> create table test(name char(30))
2> tablespace test
3> storage(initial 4k);
③ Table에 Row들을 Insert
SVRMGR> @?/labs/test100
Statement processed.
SVRMGR> @?/labs/test100
ORA-01653: unable to extend table SYS.TEST by 5 in tablespace TEST
ORA-06512: at line 6
④ Tablespace를 늘인다
SVRMGR> alter tablespace test
2> add datafile '/DBA3/DBA/dba숫자/u01/test_02.dbf' size 30k;
Statement processed.
SVRMGR> @?/labs/test100
Statement processed.
SVRMGR> select tablespace_name, bytes, file_name from dba_data_files;
SVRMGR> !ls -la $ORACLE_HOME/u01 --> "test_02.dbf" file 크기 확인
total 22563
drwxrwxr-x 2 dbamgr dba 512 Feb 24 13:08 .
drwxrwxr-x 43 dba숫자 dba 1024 Feb 20 23:21 ..
-rw-rw---- 1 dba숫자 dba 514048 Feb 24 13:05 index_01.dbf
-rw-rw---- 1 dba숫자 dba 155648 Feb 24 13:05 log1a.rdo
-rw-rw---- 1 dba숫자 dba 155648 Feb 24 13:09 log2a.rdo
-rw-rw---- 1 dba숫자 dba 155648 Feb 24 12:55 log3a.rdo
-rw-rw---- 1 dba숫자 dba 10487808 Feb 24 13:09 system.dbf
-rw-rw---- 1 dba숫자 dba 12288 Feb 24 13:09 test_01.dbf
-rw-rw---- 1 dba숫자 dba 32768 Feb 24 13:09 test_02.dbf
⑤ Datafile의 크기를 늘인다
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u01/test_02.dbf' resize 50k;
Statement processed.
SVRMGR> select tablespace_name, bytes, file_name from dba_data_files;
SVRMGR> !ls -la $ORACLE_HOME/u01
⑥ Test가 끝나면 Drop
SVRMGR> drop tablespace test;
drop tablespace test
*
ORA-01549: tablespace not empty, use INCLUDING CONTENTS option
SVRMGR> drop tablespace test including contents;
Statement processed.
SVRMGR> select tablespace_name, bytes, file_name from dba_data_files;
SVRMGR> !ls -la $ORACLE_HOME/u01
total 22611
drwxrwxr-x 2 dbamgr dba 512 Feb 24 13:08 .
drwxrwxr-x 43 dba35 dba 1024 Feb 20 23:21 ..
-rw-rw---- 1 dba35 dba 514048 Feb 24 13:05 index_01.dbf
-rw-rw---- 1 dba35 dba 155648 Feb 24 13:05 log1a.rdo
-rw-rw---- 1 dba35 dba 155648 Feb 24 13:18 log2a.rdo
-rw-rw---- 1 dba35 dba 155648 Feb 24 12:55 log3a.rdo
-rw-rw---- 1 dba35 dba 10487808 Feb 24 13:18 system.dbf
-rw-rw---- 1 dba35 dba 12288 Feb 24 13:18 test_01.dbf
-rw-rw---- 1 dba35 dba 53248 Feb 24 13:18 test_02.dbf
⑦ Datafile도 삭제
SVRMGR> !rm $ORACLE_HOME/u01/test_0*
SVRMGR> !ls -la $ORACLE_HOME/u01
SVRMGR> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> exit
Server Manager complete.
<SCENARIO 1 : Online Redo Log의 Mirroring>
SVRMGR> select * from v$log;
SVRMGR> select * from v$logfile;
SVRMGR> alter database add logfile member
'/DBA3/DBA/dba숫자/u02//log그룹번호b.rdo’to 그룹번호;
-> 각 그룹마다 멤버의 수를 갖게 미러링한다.
SVRMGR> select * from v$logfile;
<SCENARIO 2 : Full Offline Backup 수행>
① database를 shutdown한 상태에서 init/control/data file을 backup 폴더에 copy
① Database를 Startup
[/DBA3/DBA/dba숫자]svrmgrl
SVRMGR> connect internal
SVRMGR> startup
② Tablespace 정보를 확인(DBA_DATA_FILES, V$DATAFILE)
SVRMGR> select TABLESPACE_NAME, FILE_NAME
2> from dba_data_files; --> memo
③ Log File 정보를 확인(V$LOGFILE)
SVRMGR> select GROUP#, MEMBER
2> from v$logfile; --> memo
④ Control File의 정보를 확인
(V$CONTROLFILE, V$PARAMETER, init<SID>.ora, SHOW PARAMETER command)
⑤ Control File의 이름은 $ORACLE_HOME/dbs에서 Parameter File로 확인
SVRMGR> host more $ORACLE_HOME/dbs/initDBA숫자.ora --> memo
⑥ System이 정상인지 확인 (Row들을 Insert)
SVRMGR> ! more $ORACLE_HOME/labs/more_emp.sql
SVRMGR> @?/labs/more_emp
* Full Offline Backup 수행
⑦ Database Shutdown
SVRMGR> shutdown immediate
SVRMGR> exit
⑧ File들을 Backup
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp dbs/initDBA*.ora backup
[/DBA3/DBA/dba숫자] cp dbs/cntrlDBA*.ctl backup
⑨ backup에 가서 확인
[/DBA3/DBA/dba숫자] cd backup
[/DBA3/DBA/dba숫자] ls -la
<SCENARIO 3 : Recovery - Temporary Tablespace의 유실>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> select tablespace_name, file_name from dba_data_files;
--> Temporary Tablespace의 Data File 경로명을 확인
SVRMGR> !ls -la /DBA3/DBA/dba숫자/u04/temp_01.dbf --> 크기 확인
2) Failure를 만든다.
SVRMGR> shutdown abort --> Failure를 상상
SVRMGR> exit
[/DBA3/DBA/dba숫자]cd $ORACLE_HOME/u04
[/DBA3/DBA/dba숫자/u04]mv temp_01.dbf temp_01.org --> Temporary Tablespace의 유실
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> alter database open;
alter database open
*
ORA-01157: cannot identify data file 4 - file not found
ORA-01110: data file 4: '/DBA3/DBA/dba숫자/u04/temp_01.dbf'
3) Recovery 수행
- Temporary Tablespace라면 Drop하고 새로 만들면 될껄?
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u04/temp_01.dbf' offline drop;
Statement processed. --> Temporary Tablespace를 포기하고 Startup
SVRMGR> alter database open;
Stateent processed.
SVRMGR> select * from dba_tablespaces;
--> "Temp" Tablespace는 그래도 존재
--> 왜냐면 Temp Tablespace의 구성 File 중 하나를 Drop한 것 뿐이니까.
(여기선 우연히 하나였다)
SVRMGR> drop tablespace temp including contents; --> 이젠 새로 만들면 끝
SVRMGR> create tablespace temp
2> datafile '/DBA3/DBA/dba숫자/u04/temp_01.dbf' size 1M;
SVRMGR> shutdown immediate --> Shutdown과 Startup을 해봐서 잘 되는지 확인
SVRMGR> startup
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자/u04]rm temp_01.org --> 필요 없는 File을 삭제
[/DBA3/DBA/dba숫자/u04]cd
<SCENARIO 4 : Noarchive Log Mode Recovery - Disk의 유실>
1) Failure를 가정하고 Recovery 수행
- 모든 File들을 Restore하려는 데, "users_01.dbf"를 원래 위치에 Restore 할 수가 없다.
따라서, 할 수 없이 $ORACLE_HOME에 Restore 한다.
[/DBA3/DBA/dba숫자] cd backup
[/DBA3/DBA/dba숫자/backup] ls
cntrlDBA숫자.ctl u01 u03
initDBA숫자.ora u02 u04
[/DBA3/DBA/dba숫자/backup] cp -rp u0* $ORACLE_HOME
[/DBA3/DBA/dba숫자/backup] cp initDBA숫자.ora $ORACLE_HOME/dbs
[/DBA3/DBA/dba숫자/backup] cp cntrlDBA숫자.ctl $ORACLE_HOME/dbs
[/DBA3/DBA/dba숫자/backup] cd $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/u03]ls
query_01.dbf rbs_01.dbf users_01.dbf
[/DBA3/DBA/dba숫자/u03] mv users_01.dbf $ORACLE_HOME
--> users_01.dbf 이 다른 곳으로 이사 갔다.
[/DBA3/DBA/dba숫자/u03] cd
[/DBA3/DBA/dba숫자] ls -la users*
2) Startup 시도
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> alter database open;
alter database open
*
ORA-01157: cannot identify data file 3 - file not found
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
SVRMGR> select name from v$datafile;
NAME
----------------------------------------------------------
/DBA3/DBA/dba숫자/u01/system.dbf
/DBA3/DBA/dba숫자/u03/rbs_01.dbf
/DBA3/DBA/dba숫자/u03/users_01.dbf
/DBA3/DBA/dba숫자/u04/temp_01.dbf
/DBA3/DBA/dba숫자/u03/query_01.dbf
/DBA3/DBA/dba숫자/u01/index_01.dbf
6 rows selected.
--> Oracle Server는 File이 다른 곳($ORACLE_HOME)에 있다는 것을 모르네.
3) 그럼 내가 가르쳐 주지.
SVRMGR> alter database rename file '/DBA3/DBA/dba숫자/u03/users_01.dbf'
2> to '/DBA3/DBA/dba숫자/users_01.dbf';
4) 다시 Open 시도
SVRMGR> alter database open; --> 성공!!!
SVRMGR> shutdown immediate
SVRMGR> startup --> 한번 더 확인
5) 원래 상태로 만들자.
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자]rm users_01.dbf
[/DBA3/DBA/dba숫자]cd backup
[/DBA3/DBA/dba숫자/backup]cp -rp u0* $ORACLE_HOME
[/DBA3/DBA/dba숫자/backup]cp initDBA숫자.ora $ORACLE_HOME/dbs
[/DBA3/DBA/dba숫자/backup]cp cntrlDBA숫자.ctl $ORACLE_HOME/dbs
[/DBA3/DBA/dba숫자/backup]cd
[/DBA3/DBA/dba숫자]svrmgrl
SVRMGR> connect internal
SVRMGR> startup --> 괜히 확인
SVRMGR> shutdown
SVRMGR> exit
<SCENARIO 5 : Read Only Tablespace의 Backup & Recovery>
1) 정상적인 업무를 수행
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
2) Read Only Tablespace의 Backup
- Online/Offline 상태, 즉 DB가 사용중이던지 사용중이 아니던지 관계없이 Copy
SVRMGR> !cp u03/query_01.dbf $ORACLE_HOME
3) Failure를 만든다
- 업무 수행 중에 query_01.dbf File이 삭제되었다
SVRMGR> @?/labs/more_emp
SVRMGR> !rm u03/query_01.dbf
SVRMGR> select * from scott.new_dept;
ORA-01116: error in opening database file 5
ORA-01110: data file 5: '/DBA3/DBA/dba숫자/u03/query_01.dbf'
ORA-07368: sfofi: open error, unable to open database file.
SVR4 Error: 2: No such file or directory
4) Recovery 시작
- Online/Offline 상태, 즉 DB가 사용중이던지 사용중이 아니던지 관계없이 Copy
SVRMGR> !cp $ORACLE_HOME/query_01.dbf u03
SVRMGR> select * from scott.new_dept; --> 이게 Recovery 전부...
SVRMGR> shutdown
SVRMGR> exit
< SCENARIO 6 :DATABASE의 BACKUP - Control File Mirroring & Archive log mode >
1) Control File을 Mirroring하여 Database를 StartUp
- parameter File을 보고 현재의 "control_files=?????"를 확인
[/DBA3/DBA/dba숫자] more dbs/initDBA숫자.ora
- Control File을 복사
[/DBA3/DBA/dba숫자] cp dbs/cntrlDBA숫자.ctl u01
[/DBA3/DBA/dba숫자] cp dbs/cntrlDBA숫자.ctl u02
- 추가된 Control File들을 init<SID>.ora File에 등록
[/DBA3/DBA/dba숫자] vi dbs/initDBA숫자.ora
(수정) control_files=($ORACLE_HOME/dbs/cntrlDBA숫자.ctl,
$ORACLE_HOME/u01/cntrlDBA숫자.ctl,
$ORACLE_HOME/u02/cntrlDBA숫자.ctl)
:wq
- Database를 Startup
SVRMGR> connect internal
SVRMGR> startup
2) Database를 Archive Log Mode로 운영
- 현재 Archive Log Mode를 확인
SVRMGR> select * from v$logfile; --> On-Line Redo Log File들 확인
SVRMGR> archive log list --> No Archive Mode 확인
- Archive Log Mode로 전환 & Parameter 수정
SVRMGR>shutdown immediate
SVRMGR>host
[/DBA3/DBA/dba숫자]vi dbs/initDBA숫자.ora
(수정) log_archive_start = true
log_archive_dest = $ORACLE_HOME/arch
log_archive_format = _%s.arc
:wq
[/DBA3/DBA/dba숫자]exit
SVRMGR>startup mount --> 반드시 Mount로 StartUp 해야 함
SVRMGR>alter database archivelog; --> Mode 변경
SVRMGR>archive log list --> Archive Mode 확인,
--> Current Log 번호 기억
SVRMGR>alter database open; --> 현재 Mount이므로
3) Documentation을 위한 정보 탐색
- Tablespace 정보
SVRMGR> select TABLESPACE_NAME, FILE_NAME, v$datafile.STATUS, ENABLED
2> from dba_data_files, v$datafile
3> where FILE_ID = FILE#;
- Log File 정보
SVRMGR> select v$logfile.MEMBER, v$logfile.GROUP#, v$log.STATUS, BYTES
2> from v$logfile, v$log
3> where v$logfile.GROUP# = v$log.GROUP#;
- Control File 정보
SVRMGR> select * from v$controlfile;
- 각종 Parameter 정보
SVRMGR> show parameter log
SVRMGR> show parameter db_block
SVRMGR> show parameter dump
4) System이 정상인지 확인
- Row들을 Insert
SVRMGR> host more $ORACLE_HOME/labs/more_emp.sql
SVRMGR> @?/labs/more_emp
- Archived Log File이 만들어 지는 지 확인
SVRMGR> host ls -la $ORACLE_HOME/*.arc --> Log File 존재 확인
SVRMGR> archive log list --> Current Log 번호 증가 확인
5) Full Offline Backup 수행
- Database Shutdown
SVRMGR> shutdown immediate
SVRMGR> exit
- File들을 Backup (만일을 위해서 두 번 Backup)
[/DBA3/DBA/dba숫자] cp -rp u0* dontouch
[/DBA3/DBA/dba숫자] cp dbs/init*.ora dontouch
[/DBA3/DBA/dba숫자] cp dbs/cntrl*.ctl dontouch
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp dbs/init*.ora backup
[/DBA3/DBA/dba숫자] cp dbs/cntrl*.ctl backup
- 확인
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 7 : Complete Recovery - User의 DATA FILE 유실>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGR> !more labs/more_emp.sql --> "scott" user의 "s_emp" table에 Row를 Insert/Update 하는 Script
SVRMGR> @?/labs/more_emp
SVRMGR> exit
[/DBA3/DBA/dba숫자] ls -la *.arc --> Archived Log File 생성 확인
2) Failure를 만든다.
[/DBA3/DBA/dba숫자] ls u03 --> "USERS" Tablespace를 구성하는 File 확인
[/DBA3/DBA/dba숫자] rm u03/users_01.dbf --> FIle 삭제
[/DBA3/DBA/dba숫자] ls u03
SVRMGR> connect internal
SVRMGR> shutdown immediate --> Error 발생 & 실패
SVRMGR> shutdown abort
SVRMGR> exit
3) Recovery 시작
① 예전에 받은 Full Backup으로부터 손상된 Data File을 Restore
[/DBA3/DBA/dba숫자] cd backup/u03
[/DBA3/DBA/dba숫자/backup/u03] ls -la
[/DBA3/DBA/dba숫자/backup/u03] cp users_01.dbf $ORACLE_HOME/u03
- Recovery를 수행
② SVRMGR> startup
--> Error와 함께 Mount까지만 수행
--> Recovery를 위해선 " Startup Mount " 하는게 정상
Database mounted.
ORA-01113: file 3 needs media recovery
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
③ SVRMGR> recover database
ORA-00279: Change 7474 generated at 04/24/97 22:52:31 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba27/arch_256.arc
ORA-00280: Change 7474 for thread 1 is in sequence #256
Specify log: {<RET>=suggested | filename | AUTO | CANCEL} --> 여러번 "Enter"를 눌러야 함
Media recovery complete.
④ SVRMGR> alter database open;
--> 현재가 "Mount" 상태이므로
4) System이 정상적으로 복구 되었는지 확인
SVRMGR> select count(*) from scott.s_emp; --> 정상적으로 수행 됨
SVRMGR> shutdown immediate --> 정상적으로 수행 됨
SVRMGR> exit
<SCENARIO 8 : Complete Recovery - Tablespace Recovery>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGL> @?/labs/more_emp
SVRMGR> exit
[/DBA3/DBA/dba숫자]ls -la *.arc --> Archived Log File 생성 확인
2) Failure를 만든다.
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03 --> "USERS" Tablespace를 구성하는 File 확인
[/DBA3/DBA/dba숫자] rm $ORACLE_HOME/u03/users_01.dbf --> FIle 삭제
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03
SVRMGR> connect internal
SVRMGR> shutdown immediate --> Error 발생 & 실패
SVRMGR> shutdown abort
SVRMGR> exit
3) Recovery 시작
- 예전에 받은 Full Backup으로부터 손상된 Data File을 Restore
[/DBA3/DBA/dba숫자] cd backup/u03
[/DBA3/DBA/dba숫자/backup/u03] ls -la
[/DBA3/DBA/dba숫자/backup/u03] cp users_01.dbf $ORACLE_HOME/u03
- Recovery를 수행
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> alter database open; --> Error
ORA-01113: file 3 needs media recovery
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
SVRMGR> select FILE#, STATUS, NAME from v$datafile;
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' offline;
SVRMGR> select FILE#, STATUS, NAME from v$datafile;
SVRMGR> alter database open;
SVRMGR> select TABLESPACE_NAME, STATUS from dba_tablespaces;
SVRMGR> alter tablespace user_data offline immediate;
SVRMGR> select TABLESPACE_NAME, STATUS from dba_tablespaces;
SVRMGR> recover tablespace user_data
ORA-00279: Change 7220 generated at 02/24/97 23:51:30 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_219.arc
ORA-00280: Change 7220 for thread 1 is in sequence #219
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
auto - --> 입력하자
SVRMGR> alter tablespace user_data online;
SVRMGR> select count(*) from scott.s_emp; --> 정상적으로 수행 됨
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 9 : Complete Recovery - Datafile Recovery>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGR> @?/labs/more_emp
SVRMGR> exit
[/DBA3/DBA/dba숫자]ls -la *.arc --> Archived Log File 생성 확인
2) Failure를 만든다.
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03 --> "USERS" Tablespace를 구성하는 File 확인
[/DBA3/DBA/dba숫자] rm $ORACLE_HOME/u03/users_01.dbf --> FIle 삭제
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03
SVRMGR> connect internal
SVRMGR> shutdown immediate --> Error 발생 & 실패
SVRMGR> shutdown abort
SVRMGR> exit
3) Recovery 시작
① 예전에 받은 Full Backup으로부터 손상된 Data File을 Restore
[/DBA3/DBA/dba숫자] cd backup/u03
[/DBA3/DBA/dba숫자/backup/u03] ls -la
[/DBA3/DBA/dba숫자/backup/u03] cp users_01.dbf $ORACLE_HOME/u03
- Recovery를 수행
SVRMGR> connect internal
② startup mount
③ SVRMGR> alter database open;
ORA-01113: file 3 needs media recovery
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
④ SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' offline;
⑤ SVRMGR> alter database open;
⑥ SVRMGR> recover datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf'
ORA-00279: Change 7220 generated at 02/24/97 23:51:30 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_219.arc
ORA-00280: Change 7220 for thread 1 is in sequence #219
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
"Return key"를 여러번 누르거나, "auto"를 입력하자
⑦ SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' online;
SVRMGR> select count(*) from scott.s_emp; --> 정상적으로 수행 됨
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 10 : Parallel Recovery>
1) Parallel 환경 setup
- parameter file을 수정하여 parallel 환경을 만든다.
Parallel_min_servers = 2
Parallel_max_servers = 4
Recovery_parallelism = 4
- DB를 다시 기동한 후 background process들 (p000, p001) 을 확인한다.
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> host ps -ef | grep <SID>
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> shutdown immediate
2) user_data tablespace를 backup받고 DB 기동후, 정상적인 업무를 수행
[/DBA3/DBA/dba숫자]cp u03/users_01.dbf u03/users_01.bak
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp -----> row들을 insert
3) Failure를 만든다.
SVRMGR> shutdown immediate
SVRMGR> host rm $ORACLE_HOME/u03/users_01.dbf
4) DB 복구 작업
- backup 받은 file을 restore 시킨 후, Database를 mount 시킨다.
SVRMGR> !mv u03/users_01.bak u03/users_01.dbf
SVRMGR> startup mount
SVRMGR> alter database open
ORA-01113: file 3 needs media recovery
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
- DB parallel recovery 후 DB open
SVRMGR> set autorecovery on
SVRMGR> recover database parallel (degree 4)
......
Media recovery complete.
SVRMGR> alter database open
5) System이 정상인지 확인
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> !ps -ef | grep <SID> ----> p002, p003 확인 (<- degree 4)
- 5분 이상 경과 후, p002, p003이 존재하는지 확인한다.
SVRMGR> !ps -ef | grep <SID>
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 11 : Complete Recovery - Shutdown 하지 않고 Data File만 Recovery>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGR> @?/labs/more_emp
SVRMGR> exit
[/DBA3/DBA/dba숫자] ls -la *.arc --> Archived Log File 생성 확인
2) Failure를 만든다.
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03 --> "USERS" Tablespace를 구성하는 File 확인
[/DBA3/DBA/dba숫자] rm $ORACLE_HOME/u03/users_01.dbf --> FIle 삭제
[/DBA3/DBA/dba숫자] ls $ORACLE_HOME/u03
SVRMGR> connect internal
SVRMGR> select * from scott.s_dept;
ID NAME REGION_ID
---------- ------------------------- ----------
ORA-01116: error in opening database file 3
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
ORA-07368: sfofi: open error, unable to open database file.
SVR4 Error: 2: No such file or directory
3) Recovery 시작
① 예전에 받은 Full Backup으로부터 손상된 Data File을 Restore
[/DBA3/DBA/dba숫자] cd backup/u03
[/DBA3/DBA/dba숫자/backup/u03] ls -la
[/DBA3/DBA/dba숫자/backup/u03] cp users_01.dbf $ORACLE_HOME/u03
- Recovery를 수행
SVRMGR> connect internal
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' offline;
SVRMGR> recover datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf'
ORA-00279: Change 7220 generated at 02/24/97 23:51:30 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_219.arc
ORA-00280: Change 7220 for thread 1 is in sequence #219
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
"Return key"를 여러번 누르거나, "auto"를 입력하자
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' online;
SVRMGR> select count(*) from scott.s_emp; --> 정상적으로 수행 됨
SVRMGR> select * from scott.s_dept; --> 정상적으로 수행 됨
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 12 : Online Backup (Hot Backup)>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGR> @?/labs/more_emp
SVRMGR> !ls -la *.arc --> Archived Log File 생성 확인
2) Online Backup
① Data File들의 Online Backup : datafile별로 backup받는다.
SVRMGR> select tablespace_name, file_name from dba_data_files;
SVRMGR> select status, enabled, name from v$datafile;
--> enabled가 "READ ONLY" Tablespace는 Online Backup시에 제외
SVRMGR> !mkdir $ORACLE_HOME/online_backup
SVRMGR> alter tablespace system begin backup;
SVRMGR> !cp u01/system.dbf online_backup
SVRMGR> alter tablespace system end backup;
SVRMGR> alter tablespace rbs begin backup;
SVRMGR> !cp u03/rbs_01.dbf online_backup
SVRMGR> alter tablespace rbs end backup;
SVRMGR> alter tablespace user_data begin backup;
SVRMGR> !cp u03/users_01.dbf online_backup
SVRMGR> alter tablespace user_data end backup;
SVRMGR> alter tablespace temp begin backup;
SVRMGR> !cp u04/temp_01.dbf online_backup
SVRMGR> alter tablespace temp end backup;
SVRMGR> alter tablespace user_index begin backup;
SVRMGR> !cp u01/index_01.dbf online_backup
SVRMGR> alter tablespace user_index end backup;
SVRMGR> alter system switch logfile;
② Read-only Tablespace Backup
Read-only Tablespace는 예전 Backup에 이미 Copy되어 있으므로 다시 수행할 필요가 없다.
그래도 꼭 하겠다면 "alter tablespace ...begin/end backup" 없이 수행
에이, 말 나온 김에 한번 해보자......
SVRMGR> !cp u03/query_01.dbf online_backup
③ Control File의 Online Backup
SVRMGR> alter database backup controlfile to
'$ORACLE_HOME/online_backup/backup_control.ctl' reuse;
SVRMGR> alter database backup controlfile to trace;
④ Parameter File의 Backup
SVRMGR> !cp dbs/initDBA숫자.ora online_backup
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 13 : Online Backup 실패후 Recovery - Online Backup 도중에 정전>
1) 정상적인 업무를 수행
- Database를 기동 & 업무 수행
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
2) Online Backup
- Data File들의 Online Backup
SVRMGR> alter tablespace user_data begin backup;
SVRMGR> !cp u03/users_01.dbf online_backup
SVRMGR> shutdown abort --> 정전 사태 발생
SVRMGR> exit
[/DBA3/DBA/dba숫자] svrmgrl --> 다시 전원이 들어와서 DB를 살리려고 시도
SVRMGR> connect internal
SVRMGR> startup
ORA-01113: file 3 needs media recovery
ORA-01110: data file 3: '/DBA3/DBA/dba숫자/u03/users_01.dbf'
--> 어? 이상하다....아하! 이것쯤이야..
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/users_01.dbf' end backup;
SVRMGR> alter database open;
SVRMGR> --> Online Backup을 다시 받으면 된다
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 14 : Incomplete Recovery - 실수로 Drop한 Table의 복구>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
2) Failure를 만든다.
SVRMGR> !date --> 현재의 시간을 기억해야 함
SVRMGR> drop table scott.s_emp cascade constraints; --> 실수로 Drop 하였다고 가정
SVRMGR> select * from scott.s_emp;
select * from scott.s_emp
*
ERROR at line 1:
ORA-00942: table or view does not exist --> 이제와서 후회
3) Recovery 수행
- 예전에 받은 Full Backup으로부터 Data File들을 Restore
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자] cd backup
[/DBA3/DBA/dba숫자/backup] ls
[/DBA3/DBA/dba숫자/backup] cp u01/*.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/backup] cp u03/*.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/backup] cp u04/*.dbf $ORACLE_HOME/u04
- Incomplete Recovery 수행
SVRMGR> connect internal
SVRMGR> startup mount
① SVRMGR> set autorecovery on
② SVRMGR> recover database until time '1997-01-23:16:44:47'
--> 앞에서 기억한 시간이어야 함
③ SVRMGR> alter database open resetlogs; --> Incomplete Recovery 이니까 "resetlogs"로 Open
④ SVRMGR> archive log list --> Log Sequence 번호가 Reset되었음
SVRMGR> select * from scott.s_emp; --> Drop 되었던 "s_emp" Table이 다시 살아났다.
SVRMGR> shutdown immediate
SVRMGR> exit
⑤ Log Sequence 번호가 Reset 되었으니까 Off-Line Full Backup 수행
[/DBA3/DBA/dba숫자/backup] cd $ORACLE_HOME
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp dbs/cntrl*.ctl backup
[/DBA3/DBA/dba숫자] cp dbs/init*.ora backup
- 더 이상 필요 없는 File들을 삭제
[/DBA3/DBA/dba숫자] rm *.arc
[/DBA3/DBA/dba숫자] ls
<SCENARIO 15 : Inactive Online Redo Log Group의 유실>
1) 정상적인 업무를 수행
SVRMGR> connect / as sysdba --> connect internal과 같음
SVRMGR> startup
SVRMGR> @?/labs/more_emp
2) Failure를 만든다.
- Inactive Online Redo Log Group을 유실
SVRMGR> select v$logfile.member from v$logfile where group# =
( select min(v$log.group#) from v$log where status = 'INACTIVE');
MEMBER
------------------------------------------------------------
/DBA3/DBA/dba숫자/u01/log2a.rdo --> 예를 들어서...라면
/DBA3/DBA/dba숫자/u02/log2b.rdo
2 rows selected.
SVRMGR> !ls u01 u02
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/log2a.rdo
SVRMGR> !rm /DBA3/DBA/dba숫자/u02/log2b.rdo
SVRMGR> !ls u01 u02
- Database가 비정상적으로 수행됨을 확인
SVRMGR> connect / as sysdba
SVRMGR> @more_emp --> Online Redo Log FIle의 유실로 인해 Error 발생
SVRMGR> shutdown immediate --> shutdown 실패 (Server Process가 죽었다)
SVRMGR> exit --> exit 했다가 다시 들어가자.
3) Recovery 시작
SVRMGR> connect / as sysdba
SVRMGR> shutdown abort
SVRMGR> startup --> Mount까지만 수행됨
SVRMGR> select * from v$logfile; --> Log FIle의 유실이 반영되지 않았음을 확인
SVRMGR> alter database backup controlfile to trace; --> 그냥 습관적으로
SVRMGR> alter database drop logfile group 그룹번호; --> Log FIle의 유실을 반영
SVRMGR> select * from v$logfile; --> Log FIle의 유실이 반영되었음을 확인
SVRMGR> alter database add logfile group 그룹번호
2> '/DBA3/DBA/dba숫자/u01/log그룹번호a.rdo' size 150k;
--> 유실된 Online Redo Log Group의 첫번째 Member를 생성
SVRMGR> alter database add logfile member '/DBA3/DBA/dba숫자/u02/log그룹번호b.rdo' to group 그룹번호;
--> 복구된 Online Redo Log Group의 두번째 Member를 생성
SVRMGR> select * from v$logfile; --> Log File들이 생성되었는지 확인
--> Invalid는 나중에 없어지니까 놀라지 마세요.
SVRMGR> alter database open; --> Database를 Open
4) System이 정상적으로 복구 되었는지 확인
SVRMGR> @more_emp
SVRMGR> select * from v$logfile; --> 음, Invalid가 없어졌구나.
SVRMGR> shutdown immediate
SVRMGR> startup --> startup도 제대로 되는구나.
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba26/labs] cd
<SCENARIO 16 : Current Online Redo Log Group의 유실>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls -la *.arc
2) Failure를 만든다.
- Current Online Redo Log Group을 유실
SVRMGR> select v$logfile.member from v$logfile where group# =
( select min(v$log.group#) from v$log where status = 'CURRENT');
MEMBER
----------------------------------------------------------------
/DBA3/DBA/dba숫자/u01/log1a.rdo --> 예를 들어 ...라면
/DBA3/DBA/dba숫자/u02/log1b.rdo
2 rows selected.
SVRMGR> !ls u01 u02
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/log1a.rdo
SVRMGR> !rm /DBA3/DBA/dba숫자/u02/log1b.rdo
SVRMGR> !ls u01 u02
- Database가 비정상적으로 수행됨을 확인
SVRMGR> @?/labs/more_emp --> Online Redo Log FIle의 유실로 인해 Error 발생
--> 무한정 대기하게 된다. Why?
--> "Ctrl-C"를 두번 눌러서 강제 종료
SVRMGR> shutdown immediate
3) Recovery 시작
- 유실된 Redo Log Group을 제거하고 재생성함으로써 해결할려고 시도
SVRMGR> startup --> Redo Log Group이 유실 되었음을 알리며 Error 발생
--> Log Group 번호 확인할 것
--> Mount까지만 수행된다
SVRMGR> alter database drop logfile group 그룹번호;
--> 유실된 Redo Log Group을 제거 시도
--> Archive되지 않은 Current Log이므로 Error와 함께 실패
--> (참고) ORA-00350: log 그룹번호 of thread 1 needs to be archived
SVRMGR> shutdown immediate
SVRMGR> exit
- Alert File, Trace File 확인
[/DBA3/DBA/dba숫자/labs] cd $ORACLE_HOME/trace
[/DBA3/DBA/dba숫자/trace] ls
[/DBA3/DBA/dba숫자/trace] vi alert_DBA숫자.log
--> Archiving을 실패한 기록과 Sequence 번호 확인
[/DBA3/DBA/dba숫자/trace] more arch_번호.trc
--> 기록되지 않은 Log File의 Sequence 번호 확인
--> (예)ORA-00255: error archiving log 1 of thread 1, sequence # 15
--> Incomplete Recovery 방법으로 복구
--> 예를 들어 sequence # 15번이라면 Incomplete Recovery시
15번 에서 "Cancel" 을 입력할거다.
- 예전에 받은 Full Backup으로부터 Data File들을 Restore
[/DBA3/DBA/dba숫자/trace]cd $ORACLE_HOME/backup
[/DBA3/DBA/dba숫자/backup]cp u01/*.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/backup]cp u03/*.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/backup]cp u04/*.dbf $ORACLE_HOME/u04
- Incomplete Recovery 수행
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> recover database until cancel
"cancel" 입력
--> 계속 "Enter"를 누르다가 15번 에서 "Cancel" 을 입력
SVRMGR> alter database open resetlogs;
--> Incomplete Recovery 이니까 "resetlogs"로 Open
--> 이때 유실된 Log File이 자동으로 만들어 진다
SVRMGR> archive log list --> Log Sequence 번호가 Reset되었음
SVRMGR> shutdown immediate
SVRMGR> exit
- Log Sequence 번호가 Reset 되었으니까 Off-Line Full Backup 수행
[/DBA3/DBA/dba숫자/backup]cd $ORACLE_HOME
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp dbs/cntrl*.ctl backup
[/DBA3/DBA/dba숫자] cp dbs/init*.ora backup
- 더 이상 필요 없는 File들을 삭제
[/DBA3/DBA/dba숫자] cd trace
[/DBA3/DBA/dba숫자/trace] rm *.trc --> Trace File들 삭제
[/DBA3/DBA/dba숫자/trace]rm alert*.log --> Alert Log File 삭제
[/DBA3/DBA/dba숫자/trace]cd $ORACLE_HOME
[/DBA3/DBA/dba숫자]rm *.arc --> Archived Redo Log File들 삭제
[/DBA3/DBA/dba숫자]ls -la *.arc --> File들 삭제 확인
4) System이 정상적으로 복구 되었는지 확인
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp --> 음, 잘 되는 군
SVRMGR> !ls -la *.arc --> 새로운 Archived Redo Log File들이 만들어 지는 지 확인
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 17 : 모든 Online Redo Log Group의 유실>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls -la *.arc
2) Failure를 만든다.
- 모든 Online Redo Log Group을 유실
SVRMGR> !ls u01 u02
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/log*.rdo
SVRMGR> !rm /DBA3/DBA/dba숫자/u02/log*.rdo
- Database가 비정상적으로 수행됨을 확인
SVRMGR> @?/labs/more_emp --> Online Redo Log FIle의 유실로 인해 Error 발생
SVRMGR> !ps -ef|grep dba숫자|sort|more --> Background Precess들과 Server Process들이 죽었다
3) Recovery 시작
- 앞에서 배운 꽁수로 해결해 보자
SVRMGR> shutdown immediate --> shutdown 실패 (Process들이 죽었으니까)
SVRMGR> shutdown abort --> shutdown 실패 (Process들이 죽었으니까)
SVRMGR> exit --> exit 했다가 다시 들어가자.
SVRMGR> connect internal
SVRMGR> shutdown immediate
ORA-01012: not logged on
SVRMGR> shutdown abort
ORACLE instance shut down.
SVRMGR> startup
ORA-00313: open failed for members of log group 3 of thread 1
ORA-00312: online log 3 thread 1: '/DBA3/DBA/dba숫자/u02/log3a.rdo'
ORA-07360: sfifi: stat error, unable to obtain information about file.
.............
SVRMGR> recover database until cancel;
ORA-00279: Change 8064 generated at 01/20/98 13:02:09 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_9.arc
ORA-00280: Change 8064 for thread 1 is in sequence #9
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
"cancel" 입력
Media recovery cancelled.
SVRMGR> alter database open resetlogs;
alter database open resetlogs
*
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/DBA3/DBA/dba숫자/u01/system.dbf'
--> 앗! 어더레케 된거야? .....꽁수가 안 통하잖아?
??? 할 수 없다. 정식으로 한번 해 보자.
SVRMGR> exit
- 정상적인 Incomplete Recovery 수행
[/DBA3/DBA/dba숫자] cd $ORACLE_HOME/backup
[/DBA3/DBA/dba숫자/backup] cp u01/*.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/backup] cp u03/*.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/backup] cp u04/*.dbf $ORACLE_HOME/u04
SVRMGR> connect internal
SVRMGR> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /DBA3/DBA/dba숫자/arch
Oldest online log sequence 4
Next log sequence to archive 5
Current log sequence 5
--> 예를 들어 "Next log sequence to archive 5" 번이라면
Incomplete Recovery 시 5번 에서 "Cancel" 을 입력할거다.
SVRMGR> recover database until cancel
"cancel" 입력 --> 계속 "Enter"를 누르다가 5번 에서 "Cancel" 을 입력
SVRMGR> alter database open resetlogs;
SVRMGR> archive log list
- Log Sequence 번호가 Reset 되었으니까 Offline Full Backup 수행
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자/backup] cd $ORACLE_HOME
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp -p dbs/cntrl*.ctl backup
[/DBA3/DBA/dba숫자] cp -p dbs/init*.ora backup
- 더 이상 필요 없는 File들을 삭제
[/DBA3/DBA/dba숫자] rm *.arc --> Archived Redo Log File들 삭제
4) System이 정상적으로 복구 되었는지 확인
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp --> 음, 잘 되는 군
SVRMGR> !ls -la *.arc --> 새로운 Archived Redo Log File들이 만들어 지는 지 확인
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 18 : 모든 Redo Log & Data File 유실>
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls -la *.arc
2) Failure를 만든다.
- 모든 Online Redo Log Group을 유실
SVRMGR> !ls u01 u02
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/log*.rdo
SVRMGR> !rm /DBA3/DBA/dba숫자/u02/log*.rdo
- datafile을 유실
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/system.dbf
SVRMGR> !rm /DBA3/DBA/dba숫자/u01/index_01.dbf
- 정전까지 되었다고 가정
SVRMGR> shutdown abort
3) Recovery 시작
- Incomplete Recovery 수행
SVRMGR> exit
[/DBA3/DBA/dba숫자] cd $ORACLE_HOME/backup
[/DBA3/DBA/dba숫자/backup] cp u01/*.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/backup] cp u03/*.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/backup] cp u04/*.dbf $ORACLE_HOME/u04
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /DBA3/DBA/dba숫자/arch
Oldest online log sequence 3
Next log sequence to archive 5
Current log sequence 5
--> 예를 들어 "Next log sequence to archive 5" 번이라면
Incomplete Recovery 시 5번 에서 "Cancel" 을 입력할거다.
SVRMGR> recover database until cancel
"cancel" 입력 --> 계속 "Enter"를 누르다가 5번 에서 "Cancel" 을 입력
SVRMGR> alter database open resetlogs;
- Log Sequence 번호가 Reset 되었으니까 Offline Full Backup 수행
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자/backup] cd $ORACLE_HOME
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp -p dbs/cntrl*.ctl backup
[/DBA3/DBA/dba숫자] cp -p dbs/init*.ora backup
- 더 이상 필요 없는 File들을 삭제
[/DBA3/DBA/dba숫자] rm *.arc --> Archived Redo Log File들 삭제
4) System이 정상적으로 복구 되었는지 확인
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp --> 음, 잘 되는 군
SVRMGR> !ls -la *.arc --> 새로운 Archived Redo Log File들이 만들어 지는 지 확인
SVRMGR> shutdown immediate
SVRMGR> exit
<SCENARIO 19 : Control File Recreate>
1) 정상적인 업무 중 Control File Creation Script를 생성
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> !ps -ef|grep dba숫자|sort --> 현재 Server Process의 번호 확인
SVRMGR> alter database backup controlfile to trace;
SVRMGR> !
$ cd $ORACLE_HOME/trace
$ ls
$ cp ora_프로세서번호.trc control.sql
2) Control File들을 모두 삭제
$ rm $ORACLE_HOME/dbs/cntrlDBA숫자.ctl
$ rm $ORACLE_HOME/u01/cntrlDBA숫자.ctl
$ rm $ORACLE_HOME/u02/cntrlDBA숫자.ctl
$ exit
SVRMGR> shutdown immediate
SVRMGR> startup
ORA-00205: error identifying controlfile '$ORACLE_HOME/dbs/cntrlDBA숫자.ctl'
ORA-07360: sfifi: stat error, unable to obtain information about file.
SVR4 Error: 2: No such file or directory
SVRMGR> shutdown
SVRMGR> exit
3) Control File을 새로 생성
[/DBA3/DBA/dba숫자]cd trace
[/DBA3/DBA/dba숫자/trace]ls
[/DBA3/DBA/dba숫자/trace]vi control.sql --> "STARTUP NOMOUNT" 앞까지 모두 삭제
--> "RECOVER DATABASE" 삭제
SVRMGR> connect internal
SVRMGR> @control.sql
SVRMGR> !ls $ORACLE_HOME/dbs
SVRMGR> !ls $ORACLE_HOME/u01
SVRMGR> !ls $ORACLE_HOME/u02
4) 정상인지 확인
SVRMGR> @?/labs/more_emp
SVRMGR> !ls $ORACLE_HOME
SVRMGR> shutdown immediate
SVRMGR> exit
[/DBA3/DBA/dba숫자/trace] cd
[/DBA3/DBA/dba숫자]
<SCENARIO 20 : 모든 Control File 유실>
* 이번의 시나리오는 Database의 Mode(Archive/Noarchive)에 관계 없이 모두 가능
1) 정상적인 업무를 수행
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls *.arc
2) Failure를 만든다.
- Control File을 모두 삭제
SVRMGR> !rm dbs/*.ctl u01/*.ctl u02/*.ctl
SVRMGR> shutdown abort --> 꽥! (사망하시는 소리)
SVRMGR> exit
3) Recovery 시작
[/DBA3/DBA/dba숫자]cp backup/cntrlDBA숫자.ctl dbs
[/DBA3/DBA/dba숫자]cp backup/cntrlDBA숫자.ctl u01
[/DBA3/DBA/dba숫자]cp backup/cntrlDBA숫자.ctl u02
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> recover database using backup controlfile
ORA-00283: Recovery session canceled due to errors
ORA-01233: file 5 is read only - cannot recover using backup controlfile
ORA-01110: data file 5: '/DBA3/DBA/dba숫자/u03/query_01.dbf'
--> read only File이 있으면 반드시 offline시켜야 한다
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/query_01.dbf' offline;
SVRMGR> recover database using backup controlfile
ORA-00279: Change 8050 generated at 01/20/98 15:22:26 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_5.arc
ORA-00280: Change 8050 for thread 1 is in sequence #5
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Online Redo Log File 명을 Full Path로 입력
(예) /DBA3/DBA/dba숫자/u01/log1a.rdo --> 입력
그런데, 특별히 운이 좋지 않다면, 다음의 에러가 난다
(에러 메시지)
ORA-00310: archived log contains sequence 4; sequence 5 required
ORA-00334: archived log: '/DBA3/DBA/dba숫자/u01/log1a.rdo'
그렇다면, recover와 File명 입력을 다시 시도
(예)
SVRMGR> recover database using backup controlfile --> 다시 수행
/DBA3/DBA/dba숫자/u01/log2a.rdo --> 다른 Redo Log File 명 입력
다음의 메시지를 볼 때까지 다른 Redo Log File에도 수행
(보여야 하는 메시지)
Log applied.
Media recovery complete. --> 이 메시지가 보이면 성공한 것임
SVRMGR> alter database open resetlogs;
SVRMGR> select count(*) from scott.s_emp; --> 성공이다
SVRMGR> select * from scott.new_emp;
ORA-00376: file 5 cannot be read at this time
ORA-01110: data file 5: '/DBA3/DBA/dba숫자/u03/query_01.dbf'
--> 얼라리오? 이상하다? 아하! query_01.dbf이 Offline이지!
SVRMGR> select * from v$datafile;
--> 역시 "/DBA3/DBA/dba숫자/u03/query_01.dbf"이 Offline이다.
SVRMGR> alter tablespace query_data online;
SVRMGR> select * from v$datafile;
SVRMGR> select * from scott.new_emp;
SVRMGR> shutdown
SVRMGR> exit
3) 반드시 Full Backup 수행
[/DBA3/DBA/dba숫자]cp -rp u0* backup
[/DBA3/DBA/dba숫자]cp -p dbs/cntrlDBA숫자.ctl backup
[/DBA3/DBA/dba숫자]cp -p dbs/initDBA숫자.ora backup
[/DBA3/DBA/dba숫자]rm *.arc
<SCENARIO 21 : Control File과 Data File 동시에 유실>
1) 정상적인 업무를 수행
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls *.arc --> 마지막 File의 번호를 기억
SVRMGR> exit
2) Failure를 만든다.
- Control File을 모두 삭제
[/DBA3/DBA/dba숫자] rm dbs/*.ctl u01/*.ctl u02/*.ctl
- Data File을 삭제
[/DBA3/DBA/dba숫자] rm u03/users_01.dbf
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> shutdown immediate
ORA-00210: cannot open control file '/DBA3/DBA/dba숫자/dbs/cntrlDBA숫자.ctl'
SVRMGR> shutdown abort
SVRMGR> exit
3) Recovery 시작
[/DBA3/DBA/dba숫자] cp backup/cntrlDBA숫자.ctl dbs
[/DBA3/DBA/dba숫자] cp backup/cntrlDBA숫자.ctl u01
[/DBA3/DBA/dba숫자] cp backup/cntrlDBA숫자.ctl u02
[/DBA3/DBA/dba숫자] cp backup/u03/users_01.dbf u03
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> recover database using backup controlfile
ORA-00283: Recovery session canceled due to errors
ORA-01233: file 5 is read only - cannot recover using backup controlfile
ORA-01110: data file 5: '/DBA3/DBA/dba숫자/u03/query_01.dbf'
--> read only File이 있으면 반드시 offline시켜야 한다.
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/query_01.dbf' offline;
SVRMGR> recover database using backup controlfile
ORA-00279: Change 8050 generated at 01/20/98 15:22:26 needed for thread 1
ORA-00289: Suggestion : /DBA3/DBA/dba숫자/arch_5.arc
ORA-00280: Change 8050 for thread 1 is in sequence #5
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
앞에서 기억한 마지막 번호까지 "Return" Key를 누르고,
Online Redo Log File 명을 Full Path로 입력
(예) /DBA3/DBA/dba숫자/u01/log1a.rdo --> 입력
그런데, 특별히 운이 좋지 않다면, 다음의 에러가 난다
(에러 메세지)
ORA-00310: archived log contains sequence 4; sequence 5 required
ORA-00334: archived log: '/DBA3/DBA/dba숫자/u01/log1a.rdo'
그렇다면, recover와 File명 입력을 다시 시도
(예)
SVRMGR> recover database using backup controlfile --> 다시 수행
/DBA3/DBA/dba숫자/u01/log2a.rdo --> 다른 offline File 명 입력
다음의 메시지를 볼 때까지 다른 offline File에도 수행
(보여야 하는 메시지)
Log applied.
Media recovery complete. --> 이 메시지가 보이면 성공한 것임
SVRMGR> alter database open resetlogs;
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> select * from v$datafile; --> /DBA3/DBA/dba숫자/u03/query_01.dbf이 Offline이다.
SVRMGR> alter tablespace query_data online;
SVRMGR> select * from v$datafile;
SVRMGR> shutdown
SVRMGR> startup
SVRMGR> shutdown
SVRMGR> exit
3) 반드시 Full Backup 수행
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp -p dbs/cntrlDBA숫자.ctl backup
[/DBA3/DBA/dba숫자] cp -p dbs/initDBA숫자.ora backup
[/DBA3/DBA/dba숫자] rm *.arc
>
<SCENARIO 22 : Read Only Tablespace의 상태 변경에 따른 recovery - 1>
control file은 그대로 있고 R/O 가 R/W로 변경되고 그 때 데이터의 변동은 archiving되었다.
1) 정상적인 업무를 수행
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
2) Read Only tablespace query_data를 Read Write로 바꾸고 scott가 data를 입력함.
SVRMGR> alter tablespace query_data read write;
SVRMGR> select tablespace_name, status from dba_tablespaces;
SVRMGR> alter user scott quota 1 m on query_data;
SVRMGR> connect scott/tiger;
SVRMGR> create table query (id number) tablespace query_data;
SVRMGR> insert into query select id from s_emp;
SVRMGR> commit;
SVRMGR> connect internal;
SVRMGR> shutdown immediate
3) Failure를 만든다
- 업무 수행 중에 query_01.dbf File이 삭제되었다.
[/DBA3/DBA/dba숫자] rm /DBA3/DBA/dba숫자/u03/query_01.dbf
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> select * from scott.new_dept;
select * from scott.query
*
ORA-01116: error in opening database file 6
ORA-01110: data file 6: '/ DBA3/DBA/dba숫자 /u03/query_01.dbf'
ORA-07368: sfofi: open error, unable to open database file.
SVR4 Error: 2: No such file or directory
SVRMGR> shutdown abort;
SVRMGR> exit
4) Recovery 시작
[/DBA3/DBA/dba숫자] cp backup/u03/query_01.dbf u03 --> restore backup file
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
ORA-01113: file 6 needs media recovery
ORA-01110: data file 6: '/ DBA3/DBA/dba숫자 /u03/query_01.dbf'
SVRMGR> set autorecovery on
SVRMGR> recover database;
--> control file에 query_data tablespace가 read write로 되어 있어서
예전에 read only였던 사실은 중요하지 않다.
SVRMGR> alter database open;
SVRMGR> select tablespace_name, status from dba_tablespaces; --> read only 가 아니고 online
SVRMGR> select * from scott.query;
SVRMGR> shutdown
SVRMGR> exit
<SCENARIO 23 : Read Only Tablespace의 상태 변경에 따른 recovery - 2>
control file은 그대로 있고 R/O 가 R/W로 변경되고 그 때 데이터의 변동은 archiving되었다.
또한 그 중간에 test라는 tablespace를 추가하였다.
Control file이 깨졌는데 R/W로 변화를 가한 후 backup을 받지 않아서 옛날 R/O시절의 control
file을 restore한다면?
1) 정상적인 업무를 수행
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
2) 새로운 tablespace를 생성하고 data를 입력한다.
SVRMGR> create tablespace test datafile '/tmp/t숫자.dbf' size 3 m; --> test tablespace 생성
SVRMGR> alter user scott quota 1 m on test;
SVRMGR> connect scott/tiger;
SVRMGR> create table test (id number) tablespace test;
SVRMGR> insert into test select id from s_emp;
SVRMGR> insert into s_emp select * from s_emp; --> 기존에 있었던 tablespace에 작업을 한다.
SVRMGR> commit;
SVRMGR> connect internal;
SVRMGR> select tablespace_name, status from dba_tablespaces;
3) Read Only tablespace query_data를 Read Write로 바꾸고 scott가 data를 입력함.
SVRMGR> alter tablespace query_data read write;
SVRMGR> select tablespace_name, status from dba_tablespaces;
SVRMGR> alter user scott quota 1 m on query_data;
SVRMGR> connect scott/tiger;
SVRMGR> create table query (id number) tablespace query_data;
SVRMGR> insert into query select id from s_emp;
SVRMGR> commit;
SVRMGR> connect internal;
SVRMGR> shutdown immediate
3) Failure를 만든다
- 업무 수행 중에 query_01.dbf File이 삭제되었다.
[/DBA3/DBA/dba숫자] rm /DBA3/DBA/dba숫자/u03/query_01.dbf
SVRMGR> connect internal
SVRMGR> startup
ORA-00205: error in identifying control file '$ORACLE_HOME/dbs/cntrlNDBA15.ctl'
ORA-07360: sfifi: stat error, unable to obtain information about file.
SVR4 Error: 2: No such file or directory
SVRMGR> shutdown abort;
SVRMGR> exit
4) Recovery 시작
[/DBA3/DBA/dba숫자]cp backup/dbs/cntrlNDBA숫자.ctl dbs
[/DBA3/DBA/dba숫자]cp backup /dbs/cntrlNDBA숫자.ctl u01
[/DBA3/DBA/dba숫자]cp backup /dbs/cntrlNDBA숫자.ctl u02
[/DBA3/DBA/dba숫자]cp backup /u03/query_01.dbf u03
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> startup mount
SVRMGR> recover database using backup controlfile;
ORA-00283: Recovery session canceled due to errors
ORA-01233: file 6 is read only - cannot recover using backup controlfile
ORA-01110: data file 6: '/DBA3/DBA/dba숫자 /u03/query_01.dbf'
SVRMGR> alter database datafile ‘/DBA3/DBA/dba숫자 /u03/query_01.dbf' offline;
SVRMGR> recover database using backup controlfile
ORA-00279: Change 7479 generated at 06/03/98 16:52:00 needed for thread 1
ORA-00289: Suggestion : /base6/NDBA/ndba15/arch_252.arc
ORA-00280: Change 7479 for thread 1 is in sequence #252
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
/base6/NDBA/ndba15/u01/log3a.rdo
Log applied. --> 이 message가 보일 때까지 계속 recovery 수행.
Media recovery complete
SVRMGR> alter database open resetlogs;
SVRMGR> select * from v$datafile; --> MISSING000x 라는 file이 있다. (t.dbf) --> 왜 이름을 모를까?
SVRMGR> alter database rename file 'MISSING0008' to '/tmp/t.dbf';
SVRMGR> alter tablespace test online;
alter tablespace test online
*
ORA-01190: control file or data file 8 is from before the last RESETLOGS
ORA-01110: data file 8: '/tmp/t.dbf'
SVRMGR> alter tablespace query_data online; --> 안되는 이유는?
alter tablespace query_data online
*
ORA-01190: control file or data file 6 is from before the last RESETLOGS
ORA-01110: data file 6: '/base6/NDBA/ndba15/u03/query_01.dbf'
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> shutdown
SVRMGR> exit
<SCENARIO 24 : Read Only Tablespace의 상태 변경에 따른 recovery - 3>
control file은 그대로 있고 R/O 가 R/W로 변경되고 그 때 데이터의 변동은 archiving되었다.
또한 그 중간에 test라는 tablespace를 추가하였다. Control file이 깨졌는데 R/W로 변화를
가한 후 backup을 이용하면 복구가 가능하다. 항상 control file을 backup.
1) 정상적인 업무를 수행
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
2) 새로운 tablespace를 생성하고 data를 입력한다.
SVRMGR> create tablespace test datafile '/tmp/t숫자.dbf' size 3 m; --> test tablespace 생성
SVRMGR> alter user scott quota 1 m on test;
SVRMGR> connect scott/tiger;
SVRMGR> create table test (id number) tablespace test;
SVRMGR> insert into test select id from s_emp;
SVRMGR> insert into s_emp select * from s_emp; --> 기존에 있었던 tablespace에 작업을 한다.
SVRMGR> commit;
SVRMGR> connect internal;
SVRMGR> select tablespace_name, status from dba_tablespaces;
3) Read Only tablespace query_data를 Read Write로 바꾸고 scott가 data를 입력함.
SVRMGR> alter tablespace query_data read write;
SVRMGR> select tablespace_name, status from dba_tablespaces;
SVRMGR> alter user scott quota 1 m on query_data;
SVRMGR> connect scott/tiger;
SVRMGR> create table query (id number) tablespace query_data;
SVRMGR> insert into query select id from s_emp;
SVRMGR> commit;
SVRMGR> connect internal;
SVRMGR> shutdown immediate
SVRMGR> !ps -ef | grep NDBA15
ndba15 25748 25747 0 11:38:49 ? 0:03 oracleNDBA15
(DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))
ndba15 25766 25765 2 11:39:26 pts/40 0:00 grep NDBA15
ndba15 25102 1 6 11:20:43 ? 5:37 oracleNDBA15
(DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))
SVRMGR> !ls $ORACLE_HOME/trace
alert_NDBA15.log ora_25748.trc
SVRMGR> !mv $ORACLE_HOME/trace/ ora_25748.trc /tmp/c.sql
SVRMGR> !vi /tmp/c.sql
SVRMGR
3) Failure를 만든다
- 업무 수행 중에 control File이 삭제되었다.
[/DBA3/DBA/dba숫자] rm */cntrl*.ctl
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
ORA-00205: error in identifying control file '$ORACLE_HOME/dbs/cntrlNDBA15.ctl'
ORA-07360: sfifi: stat error, unable to obtain information about file.
SVR4 Error: 2: No such file or directory
SVRMGR> shutdown abort;
SVRMGR> shutdown abort;
4) Recovery 시작
SVRMGR> @/tmp/c.sql
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> shutdown
SVRMGR> exit
<SCENARIO 25 : Recovery from Online Backup - Data File, Control File 유실>
1) 정상적인 업무를 수행
- Database를 기동
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> @?/labs/more_emp
SVRMGR> !ls -la *.arc --> 마지막 번호 기억
2) Failure를 만든다.
- Data file, Control file 삭제
SVRMGR> shutdown abort
SVRMGR> exit
[/DBA3/DBA/dba숫자] rm u01/system.dbf u03/rbs_01.dbf
[/DBA3/DBA/dba숫자] rm dbs/*.ctl u01/*.ctl u02/*.ctl
3) Recovery 시작
- Data file, Control file Restore
[/DBA3/DBA/dba숫자] cd online_backup
[/DBA3/DBA/dba숫자/online_backup] ls
[/DBA3/DBA/dba숫자/online_backup] cp system.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/online_backup] cp rbs_01.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/dbs/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/u01/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/u02/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cd
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/query_01.dbf' offline;
SVRMGR> recover database using backup controlfile
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
앞에서 기억한 마지막 번호까지 "Return" Key를 누르고,
Online Redo Log File 명을 Full Path로 입력
(예) /DBA3/DBA/dba숫자/u01/log1a.rdo --> 입력
Error가 나면, recover와 다른 Online Redo Log File명을 다시 입력
Media recovery complete. --> 이 메세지가 보이면 성공한 것임
SVRMGR> alter database open resetlogs;
SVRMGR> alter tablespace query_data online;
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> shutdown
SVRMGR> exit
4) 반드시 Full Backup 해야 함.
[/DBA3/DBA/dba숫자] cp -rp u0* backup
[/DBA3/DBA/dba숫자] cp -p dbs/cntrlDBA숫자.ctl backup
[/DBA3/DBA/dba숫자] cp -p dbs/initDBA숫자.ora backup
[/DBA3/DBA/dba숫자] rm *.arc
<SCENARIO 26 : Recovery from Online Backup - File들 모두가 사라졌다.
게다가, Archived Redo Log File의 일부가 없고, Data File Backup도 일부 없다.>
0) 바로 앞의 실습(SCENARIO 15번)을 하였다면 Redo Log가 Reset 되었으므로
Online Backup을 다시 받고 나서 아래의 과정으로 실습하여야 한다.
Online Backup은 <시나리오12>의 실습 참고.
1) 정상적인 업무를 수행
- Database를 기동
SVRMGR> connect internal
SVRMGR> startup
- 업무 수행 & Archived Log File 확인
SVRMGR> !ls -la *.arc --> 현재의 Archived Log File 확인
SVRMGR> @?/labs/more_emp
2) Failure를 만든다.
- Database의 모든 Data file들, 모든 Control file들, 모든 Online Redo Log file들,
Parameter file 즉, 몽조리 사라졌다. 난리 났다.
SVRMGR> shutdown abort
SVRMGR> exit
[/DBA3/DBA/dba숫자] rm u01/* u02/* u03/* u04/* dbs/*.ctl
3) Recovery 시작
- 게다가 Archived Redo Log File 마지막 2개도 사라졌다.
[/DBA3/DBA/dba숫자] ls *.arc
[/DBA3/DBA/dba숫자] rm -i *.arc --> 알아서 마지막 2개 삭제
[/DBA3/DBA/dba숫자] ls *.arc --> 존재하는 마지막 File의 번호를 기억
- File들을 Restore한다. 그런데 index_01.dbf File의 Backup이 사라졌다. 기절하시겠다.
[/DBA3/DBA/dba숫자] cd online_backup
[/DBA3/DBA/dba숫자/online_backup] ls
[/DBA3/DBA/dba숫자/online_backup] cp initDBA숫자.ora $ORACLE_HOME/dbs
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/dbs/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/u01/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cp backup_control.ctl $ORACLE_HOME/u02/cntrlDBA숫자.ctl
[/DBA3/DBA/dba숫자/online_backup] cp system.dbf $ORACLE_HOME/u01
[/DBA3/DBA/dba숫자/online_backup] cp query_01.dbf rbs_01.dbf users_01.dbf $ORACLE_HOME/u03
[/DBA3/DBA/dba숫자/online_backup] cp temp_01.dbf $ORACLE_HOME/u04
[/DBA3/DBA/dba숫자/online_backup] cd
- Online Redo Log file이 없으니까 Incomplete Recovery 수행
[/DBA3/DBA/dba숫자]svrmgrl
SVRMGR> connect internal
SVRMGR> startup mount
SVRMGR> recover database using backup controlfile until cancel
ORA-00283: Recovery session canceled due to errors
ORA-01233: file 5 is read only - cannot recover using backup controlfile
ORA-01110: data file 5: '/DBA3/DBA/dba숫자/u03/query_01.dbf'
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u03/query_01.dbf' offline;
SVRMGR> recover database using backup controlfile until cancel
ORA-00283: Recovery session canceled due to errors
ORA-01157: cannot identify data file 6 - file not found
ORA-01110: data file 6: '/DBA3/DBA/dba숫자/u01/index_01.dbf'
SVRMGR> alter database datafile '/DBA3/DBA/dba숫자/u01/index_01.dbf' offline;
SVRMGR> recover database using backup controlfile until cancel
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
cancel --> 마지막 Log 번호까지 처리하고 나서 "cancel" 입력
Media recovery cancelled.
SVRMGR> alter database open resetlogs;
SVRMGR> select * from v$datafile;
SVRMGR> alter tablespace query_data online;
SVRMGR> select * from dba_tablespaces;
SVRMGR> drop tablespace user_index; --> Backup 자체가 존재하지 않으므로 포기하는 수 밖에 없다.
SVRMGR> create tablespace user_index
datafile '/DBA3/DBA/dba숫자/u01/index_01.dbf' size 500k;
SVRMGR> select count(*) from scott.s_emp;
SVRMGR> shutdown
SVRMGR> exit
4) 반드시 Full Backup 해야 함.
[/DBA3/DBA/dba숫자]cp -rp u0* backup
[/DBA3/DBA/dba숫자]cp -p dbs/cntrlDBA숫자.ctl backup
[/DBA3/DBA/dba숫자]cp -p dbs/initDBA숫자.ora backup
[/DBA3/DBA/dba숫자]rm *.arc
<SCENARIO 27 : Recover with No Backup>
1) 정상적인 업무
[/DBA3/DBA/dba숫자]svrmgrl
SVRMGR> connect internal
SVRMGR> startup
SVRMGR> @?/labs/more_emp
SVRMGR> !ls *.arc
SVRMGR> create tablespace new_data
datafile '$ORACLE_HOME/u04/new_data.dbf' size 500k reuse ;
SVRMGR> create table scott.new_data tablespace new_data
as select * from scott.s_emp;
SVRMGR> @?/labs/more_emp
2) Failure
SVRMGR> shutdown abort
SVRMGR> exit
[/DBA3/DBA/dba숫자] ls -la $ORACLE_HOME/u04
[/DBA3/DBA/dba숫자] rm $ORACLE_HOME/u04/new_data.dbf
[/DBA3/DBA/dba숫자] ls -la $ORACLE_HOME/u04
3) Recovery
[/DBA3/DBA/dba숫자] svrmgrl
SVRMGR> connect internal
SVRMGR> startup
ORA-01157: cannot identify data file 7 - file not found
ORA-01110: data file 7: '/DBA3/DBA/dbapjw/u04/new_data.dbf'
SVRMGR> alter database
create datafile '/DBA3/DBA/dba숫자/u04/new_data.dbf';
SVRMGR> !ls -la $ORACLE_HOME/u04
SVRMGR> recover datafile '/DBA3/DBA/dba숫자/u04/new_data.dbf'
auto 입력
SVRMGR> alter database open;
4) 확인
SVRMGR> select count(*) from scott.new_data;
5) 원상 복구
SVRMGR> drop tablespace new_data including contents;
SVRMGR> !rm /DBA3/DBA/dba숫자/u04/new_data.dbf
SVRMGR> shutdown
SVRMGR> exit
<SCENARIO 28 : Incremental export 와 direct path >
$ sqlplus scott/tiger
SQL> SELECT COUNT(1) FROM s_emp;
COUNT(1)
----------
44
SQL> exit
$ exp userid=sys/change_on_install full=y file=Comp001.dmp inctype=complete
$ sqlplus system/manager
SQL> @?/labs/more_emp
SQL> exit
$exp userid=sys/change_on_install full=y file=Inc002.dmp inctype=incremental
$ sqlplus system/manager
SQL> @?/labs/more_emp
$ exp userid=sys/change_on_install full=y file=Inc003.dmp inctype=incremental
$ sqlplus system/manager
SQL> @?/labs/more_emp
$ exp userid=sys/change_on_install full=y file=Cum004.dmp inctype=cumulative
$ sqlplus system/manager
SQL> @?/labs/more_emp
$ exp userid=sys/change_on_install full=y file=Inc005.dmp inctype=incremental
$ sqlplus scott/tiger
SQL> select count(1) from s_emp;
SQL> drop table s_emp;
$ imp userid=sys/change_on_install full=y file=Comp001.dmp ignore=y
$ imp userid=sys/change_on_install full=y file=Cum004.dmp ignore=y
$ imp userid=sys/change_on_install full=y file=Inc005.dmp ignore=y
$ sqlplus scott/tiger
SQL> select count(1) from s_emp;
$
$
*********************************************************
** Direct mode Export Test **
*********************************************************
$
$
$vi direct.sh
date > Dstart
exp userid=scott/tiger table=s_emp file=direct.dmp direct=y
date > Dend
$vi conv.sh
date > Cstart
exp userid=scott/tiger table=s_emp file=conv.dmp direct=n
date > Cend
<SCENARIO 29 : standby database 생성>
PRIMARY DB part
Script started on Tue Jan 20 19:53:46 1998
$ pwd
/disk2/inst/parkjy/oracle
$ set | grep ORACLE
ORACLE_HOME=/disk2/inst/parkjy/oracle
ORACLE_SID=KELLOGG
$ svrmgrl
Oracle Server Manager Release 2.3.2.0.0 - Production
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
O racle7 Server Release 7.3.2.1.0 - Production Release
With the distributed and parallel query options
PL/SQL Release 2.3.2.0.0 - Production
SVRMGR> connect internal
Connected.
SVRMGR> @/tmp/more_emp;
Statement processed.
Statement processed.
4 rows processed.
Statement processed.
Statement processed.
4 rows processed.
Statement processed.
Statement processed.
4 rows processed.
Statement processed.
Statement processed.
Statement processed.
44 rows processed.
Statement processed.
Statement processed.
COUNT(*)
----------
44
1 row selected.
SVRMGR> shutdown;
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> exit
Server Manager complete.
$ pwd
/disk2/inst/parkjy/oracle
$ tar cvf dbf.tar u0?/*
seek = 0K a u01/system.dbf 10242K
seek = 10243K a u02/log1a.rdo 152K
seek = 10395K a u02/log1c.rdo 152K
seek = 10548K a u02/log1d.rdo 152K
seek = 10700K a u02/log2a.rdo 152K
seek = 10853K a u02/log3a.rdo 152K
seek = 11005K a u03/log1b.rdo 152K
seek = 11158K a u03/log2b.rdo 152K
seek = 11310K a u03/log3b.rdo 152K
seek = 11463K a u04/rbs_01.dbf 1026K
seek = 12489K a u05/users_01.dbf 5122K
seek = 17612K a u06/index_01.dbf 502K
seek = 18114K a u07/temp_01.dbf 1026K
seek = 19141K a u08/query_01.dbf 502K
$ ftp krnile3
Connected to krnile3.kr.oracle.com.
220 krnile3 FTP server (UNIX(r) System V Release 4.0) ready.
Name (krnile3:parkjy):
331 Password required for parkjy.
Password:
230 User parkjy logged in.
ftp> bin
200 Type set to I.
ftp> put dbf.tar
200 PORT command successful.
150 Binary data connection for dbf.tar (152.69.16.52,1842).
226 Transfer complete.
local: dbf.tar remote: dbf.tar
20116480 bytes sent in 20 seconds (9.6e+02 Kbytes/s)
ftp> pwd
257 "/disk2/inst/parkjy" is current directory.
ftp> quit
221 Goodbye.
$ svrmgrl
Oracle Server Manager Release 2.3.2.0.0 - Production
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle7 Server Release 7.3.2.1.0 - Production Release
With the distributed and parallel query options
PL/SQL Release 2.3.2.0.0 - Production
SVRMGR> connect internal
Connected to an idle instance.
SVRMGR> startup
ORACLE instance started.
Total System Global Area 2113588 bytes
Fixed Size 40436 bytes
Variable Size 1860160 bytes
Database Buffers 204800 bytes
Redo Buffers 8192 bytes
Database mounted.
Database opened.
SVRMGR> alter database create standby controlfile as '/tmp/stnb.ctl';
Statement processed.
SVRMGR> alter system archive log current;
Statement processed.
SVRMGR> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /disk2/inst/parkjy/oracle/arch/arc
Oldest online log sequence 35
Next log sequence to archive 37
Current log sequence 37
SVRMGR> shutdown;
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> exit
Server Manager complete.
$ cd /tmp
$ ftp krnile3
Connected to krnile3.kr.oracle.com.
220 krnile3 FTP server (UNIX(r) System V Release 4.0) ready.
Name (krnile3:parkjy):
331 Password required for parkjy.
Password:
230 User parkjy logged in.
ftp> bin
200 Type set to I.
ftp> put stnb.ctl
200 PORT command successful.
150 Binary data connection for stnb.ctl (152.69.16.52,1851).
226 Transfer complete.
local: stnb.ctl remote: stnb.ctl
145408 bytes sent in 0.1 seconds (1.4e+03 Kbytes/s)
ftp> pwd
257 "/disk2/inst/parkjy" is current directory.
ftp> quit
221 Goodbye.
$ cd
$ cd oracle/arch
$ ls
arc_1.arc arc_16.arc arc_22.arc arc_29.arc arc_35.arc arc_6.arc
arc_10.arc arc_17.arc arc_23.arc arc_3.arc arc_36.arc arc_7.arc
arc_11.arc arc_18.arc arc_24.arc arc_30.arc arc_4.arc arc_8.arc
arc_12.arc arc_19.arc arc_25.arc arc_31.arc arc_5.arc arc_9.arc
arc_13.arc arc_2.arc arc_26.arc arc_32.arc arc_514.arc
arc_14.arc arc_20.arc arc_27.arc arc_33.arc arc_515.arc
arc_15.arc arc_21.arc arc_28.arc arc_34.arc arc_516.arc
$ r ftp krnile3
Connected to krnile3.kr.oracle.com.
220 krnile3 FTP server (UNIX(r) System V Release 4.0) ready.
Name (krnile3:parkjy):
331 Password required for parkjy.
Password:
230 User parkjy logged in.
ftp> bin
200 Type set to I.
ftp> put arc_36.arc
200 PORT command successful.
150 Binary data connection for arc_36.arc (152.69.16.52,1854).
226 Transfer complete.
local: arc_36.arc remote: arc_36.arc
14336 bytes sent in 0 seconds (14 Kbytes/s)
ftp> quit
221 Goodbye.
STANDBY DB Part
Script started on Tue Jan 20 18:56:25 1998
$ pwd
/disk2/inst/parkjy
$ set | grep ORACLE
ORACLE_HOME=/disk2/inst/parkjy/oracle
ORACLE_SID=KELLOGG
$ ls
C++ TEST arc_36.arc dbf.tar oracle work
PROC WEB arch dbs_standby stnb.ctl
$ mv arc_36.* orace le/arch
$ mv stnb.ctl oracle/dbs/cntrlKELLOGG.ctl
$ ls oracle/dbs
cntrlKELLOG.ctl create_db.sql log1KELLOGG.dbf s2.ctl
cntrlKELLOGG.bak dbs1KELLOGG.dbf log2KELLOGG.dbf sql.bsq
cntrlKELLOGG.ctl destroydb mkdb standby.ctl
create_db.sh initKELLOGG.ora s.ctl
$ mv dbf.tar oracle
$ cd oracle
$ tar xvf dbf.. tar
x u01/system.dbf, 10487808 bytes, 10242K
x u02/log1a.rdo, 155648 bytes, 152K
x u02/log1c.rdo, 155648 bytes, 152K
x u02/log1d.rdo, 155648 bytes, 152K
x u02/log2a.rdo, 155648 bytes, 152K
x u02/log3a.rdo, 155648 bytes, 152K
x u03/log1b.rdo, 155648 bytes, 152K
x u03/log2b.rdo, 155648 bytes, 152K
x u03/log3b.rdo, 155648 bytes, 152K
x u04/rbs_01.dbf, 1050624 bytes, 1026K
x u05/users_01.dbf, 5244928 bytes, 5122K
x u06/index_01.dbf, 514048 bytes, 502K
x u07/temp_01.dbf, 1050624 bytes, 1026K
x u08/query_01.dbf, 514048 bytes, 502K
$ svrmgrl
Oracle Server Manager Release 2.1.4.0.0 - Production
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle7 Server Release 7.3.2.1.0 - Production Release
With the distributed and parallel query options
PL/SQL Release 2.3.2.0.0 - Production
SVRMGR> connect internal
Connected to an idle instance.
SVRMGR> startup nomount
ORACLE instance started.
Total System Global Area 2113588 bytes
Fixed Size 40436 bytes
Variable Size 1860160 bytes
Database Buffers 204800 bytes
Redo Buffers 8192 bytes
SVRMGR> alter database mount standby database;
Statement processed.
SVRMGR> recover standby database;
ORA-00279: Change 9735 generated at 01/20/98 19:54:43 needed for thread 1
ORA-00289: Suggestion : /disk2/inst/parkjy/oracle/arch/arc_36.arc
ORA-00280: Change 9735 for thread 1 is in sequence #36
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Log applied.
ORA-00279: Change 9743 generated at 01/20/98 19:57:41 needed for thread 1
ORA-00289: Suggestion : /disk2/inst/parkjy/oracle/arch/arc_37.arc
ORA-00280: Change 9743 for thread 1 is in sequence #37
ORA-00278: Logfile '/disk2/inst/parkjy/oracle/arch/arc_36.arc' no longer needed for this recovery
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
cancel;
Media recovery cancelled.
SVRMGR> alter database activate standby database;
Statement processed.
SVRMGR> shutdown;
sORA-01507: database not mounted
Database dismounted.
ORACLE instance shut down.
SVGMGR> startup
SVRMGR> ORACLE instance started.
Total System Global Area 2113588 bytes
Fixed Size 40436 bytes
Variable Size 1860160 bytes
Database Buffers 204800 bytes
Redo Buffers 8192 bytes
Database mounted.
Database opened.
SVRMGR> select count(*)
2> from d s_emp.scott scott.s_emp;
COUNT(*)
----------
44
1 row selected.
SVRMGR> shutdown;
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> exit
Server Manager complete
<SCENARIO 30 : Catalog DB를 이용한 복구 Oracle8 >
Part I.
1. Try starting the rman program.
What happens and why?
$ rman
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06009: using target database controlfile instead of recovery catalog
RMAN>
Recovery manager connects to your database expecting no recovery
catalog. All information is retrieved from the controlfile.
2. Disconnect from the recovery manager.
Connect to the recovery catalog using dbaXX/dbaXX@DBA16 as connect string.
You should connect to your targeted database as internal/admin@DBAXX.
XX is your account number.
Do not specify a log file that way all messages will be written to
your screen.
$ rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\"
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06008: connected to recovery catalog database
RMAN>
3. Register your database with the recovery catalog.
RMAN> register database;
RMAN-08006: database registered in recovery catalog
RMAN-08002: starting full resync of recovery catalog
RMAN-08029: snapshot controlfile name set to default value: ?/dbs/snapcf_@.f
RMAN-08004: full resync complete
RMAN>
4. List the incarnation of the database.
RMAN> list incarnation of database;
RMAN-06240: List of Database Incarnations
RMAN-06241: DB Key Inc Key DB Name DB ID CUR Reset SCN Reset Time
RMAN-06242: ------- ------- -------- ---------------- --- ---------- -------
RMAN-06243: 1 2 DBA15 4045670789 YES 1 18-FEB-97
RMAN>
5. Try to do a resync of the recovery catalog.
RMAN> resync catalog;
RMAN-08002: starting full resync of recovery catalog
RMAN-08004: full resync complete
RMAN>
6. Exit the recovery manager and reconnect directing your output to a logfile.
rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\" \
> msglog=\"rmanDBA15.log\"
7. Try to do a resync one more time.
RMAN> resync catalog;
RMAN>
8. Exit and investigate your logfile.
RMAN> exit
$ cat rmanDBA15.log
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06008: connected to recovery catalog database
RMAN> resync catalog;
RMAN-08002: starting full resync of recovery catalog
RMAN-08004: full resync complete
RMAN> exit
Recovery Manager complete.
Part II.
1. Investigate the script cre_back.rman
Change "YOUR_PATH" to contain your HOME directory
(Can be displayed using pwd from the unix prompt)
$ cat cre_back.rman
create script back_db_full {
allocate channel d1 type disk;
backup full filesperset 4
(database include current controlfile
format "/YOUR_PATH/BACK/back_DBA15_full.%s.%p");
release channel d1;}
2. Connect to the recovery catalog database and use your database
as the targeted database.
Create and run the backup script
What happens and why ?
Note that Recovery Manager does not accept the @script as svrmgr or
sqlplus, so you either have to cut and paste or type it in.
$ rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\"
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06008: connected to recovery catalog database
RMAN> create script back_db_full {
2> allocate channel d1 type disk;
3> backup full filesperset 4
4> (database include current controlfile
5> format "/users/dba15/BACK/back_DBA15_full.%s.%p");
6> release channel d1;}
RMAN-08085: created script back_db_full
RMAN> run { execute script back_db_full;}
RMAN-08030: allocated channel: d1
RMAN-08500: channel d1: sid=9 devtype=DISK
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=17 set_stamp=296089196
RMAN-03007: exception occurred during execution, error is retryable
RMAN-07004: unhandled exception during command execution on channel d1
RMAN-10032: unhandled exception during execution of job step 1: ORA-06512: at line 57
RMAN-10035: exception raised in RPC: ORA-19624: operation failed, retry possible
ORA-19602: cannot backup or copy active file in NOARCHIVELOG mode
ORA-06512: at "SYS.X$DBMS_BACKUP_RESTORE", line 312
RMAN-10031: ORA-19624 occurred during call to X$DBMS_BACKUP_RESTORE.BACKUPDATAFILE
This happens because your database is running in NOARCHIVELOG mode and a backup
from recovery manager can only be performed with the database in mounted state.
3. Shutdown your database and restart it in mount mode.
Rerun your script.
RMAN> exit;
Recovery Manager complete.
$ svrmgrl
Oracle Server Manager Release 3.0.2.0.0 - Beta
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle8 Server Release 8.0.2.0.0 - Beta
With the distributed, heterogeneous, replication, objects,
parallel query and Spatial Data options
PL/SQL Release 3.0.2.0.0 - Beta
SVRMGR> connect internal
Connected.
SVRMGR> shutdown
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> startup mount pfile=initDBA15.ora
ORACLE instance started.
Total System Global Area 4635056 bytes
Fixed Size 43724 bytes
Variable Size 4116196 bytes
Database Buffers 409600 bytes
Redo Buffers 65536 bytes
Database mounted.
SVRMGR> exit
Server Manager complete.
$ rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\"
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06008: connected to recovery catalog database
RMAN> run { execute script back_db_full;}
RMAN-08030: allocated channel: d1
RMAN-08500: channel d1: sid=8 devtype=DISK
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=18 set_stamp=296089658
RMAN-08010: channel d1: including datafile number 1 in backupset
RMAN-08010: channel d1: including datafile number 2 in backupset
RMAN-08010: channel d1: including datafile number 3 in backupset
RMAN-08010: channel d1: including datafile number 4 in backupset
RMAN-08013: channel d1: piece 1 created
RMAN-08503: piece handle=/users/dba15/BACK/back_DBA15_full.18.1 comment=NONE
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=19 set_stamp=296089694
RMAN-08010: channel d1: including datafile number 5 in backupset
RMAN-08010: channel d1: including datafile number 6 in backupset
RMAN-08010: channel d1: including datafile number 7 in backupset
RMAN-08010: channel d1: including datafile number 8 in backupset
RMAN-08013: channel d1: piece 1 created
RMAN-08503: piece handle=/users/dba15/BACK/back_DBA15_full.19.1 comment=NONE
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=20 set_stamp=296089706
RMAN-08010: channel d1: including datafile number 9 in backupset
RMAN-08010: channel d1: including datafile number 10 in backupset
RMAN-08010: channel d1: including datafile number 11 in backupset
RMAN-08010: channel d1: including datafile number 12 in backupset
RMAN-08013: channel d1: piece 1 created
RMAN-08503: piece handle=/users/dba15/BACK/back_DBA15_full.20.1 comment=NONE
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=21 set_stamp=296089717
RMAN-08010: channel d1: including datafile number 13 in backupset
RMAN-08010: channel d1: including datafile number 14 in backupset
RMAN-08010: channel d1: including datafile number 15 in backupset
RMAN-08010: channel d1: including datafile number 16 in backupset
RMAN-08013: channel d1: piece 1 created
RMAN-08503: piece handle=/users/dba15/BACK/back_DBA15_full.21.1 comment=NONE
RMAN-08008: channel d1: started datafile backupset
RMAN-08502: set_count=22 set_stamp=296089723
RMAN-08010: channel d1: including datafile number 17 in backupset
RMAN-08010: channel d1: including datafile number 18 in backupset
RMAN-08010: channel d1: including datafile number 19 in backupset
RMAN-08011: channel d1: including current controlfile in backupset
RMAN-08013: channel d1: piece 1 created
RMAN-08503: piece handle=/users/dba15/BACK/back_DBA15_full.22.1 comment=NONE
RMAN-08003: starting partial resync of recovery catalog
RMAN-08005: partial resync complete
RMAN-08031: released channel: d1
RMAN>
4. Startup the database and force some log switches using
the alter system switch logfile command.
svrmgrl
Oracle Server Manager Release 3.0.2.0.0 - Beta
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle8 Server Release 8.0.2.0.0 - Beta
With the distributed, heterogeneous, replication, objects,
parallel query and Spatial Data options
PL/SQL Release 3.0.2.0.0 - Beta
SVRMGR> connect internal
Connected.
SVRMGR> alter database open;
Statement processed.
SVRMGR> alter system switch logfile;
Statement processed.
SVRMGR> alter system switch logfile;
Statement processed.
SVRMGR> alter system switch logfile;
Statement processed.
SVRMGR>
5. Shutdown your database and remove the datafiles, all the logfiles and
all the controlfiles.
SVRMGR> shutdown
Database closed.
Database dismounted.
ORACLE instance shut down.
SVRMGR> exit
Server Manager complete.
$ rm *.dbf *.ctl *.log
6. Investigate the script cre_rec.rman
Change "YOUR_PATH" to contain your HOME directory
(Can be displayed using pwd from the unix prompt)
$ cat cre_rec.rman
create script rec_db_full{
allocate channel d1 type disk;
restore controlfile to "/YOUR_PATH/control1.ctl";
restore database;
release channel d1;}
7. Startup your instance.
$ svrmgrl
Oracle Server Manager Release 3.0.2.0.0 - Beta
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle8 Server Release 8.0.2.0.0 - Beta
With the distributed, heterogeneous, replication, objects,
parallel query and Spatial Data options
PL/SQL Release 3.0.2.0.0 - Beta
SVRMGR> connect internal
Connected.
SVRMGR> startup nomount pfile=initDBA15.ora
ORACLE instance started.
Total System Global Area 4635056 bytes
Fixed Size 43724 bytes
Variable Size 4116196 bytes
Database Buffers 409600 bytes
Redo Buffers 65536 bytes
SVRMGR> exit
Server Manager complete.
8. Connect to the recovery catalog and your instance.
Run the content of cre_rec.rman.
$ rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\"
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06006: connected to target database: DBA15 (not mounted)
RMAN-06008: connected to recovery catalog database
RMAN> create script rec_db_full{
2> allocate channel d1 type disk;
3> restore controlfile to "/users/dba15/control1.ctl";
4> restore database;
5> sql "alter database mount";
6> release channel d1;}
RMAN-08085: created script rec_db_full
9. Run the script rec_db_full.
RMAN> run {execute script "rec_db_full";}
MAN-08030: allocated channel: d1
RMAN-08500: channel d1: sid=6 devtype=DISK
RMAN-08016: channel d1: started datafile restore
RMAN-08021: channel d1: restoring controlfile
RMAN-08505: output filename=/users/dba15/control1.ctl
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.22.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08016: channel d1: started datafile restore
RMAN-08019: channel d1: restoring datafile number 1
RMAN-08509: destination for restored datafile number=1 filename=/users/dba15/systemDBA15.dbf
RMAN-08019: channel d1: restoring datafile number 2
RMAN-08509: destination for restored datafile number=2 filename=/users/dba15/rbsDBA15.dbf
RMAN-08019: channel d1: restoring datafile number 3
RMAN-08509: destination for restored datafile number=3 filename=/users/dba15/tempDBA15.dbf
RMAN-08019: channel d1: restoring datafile number 4
RMAN-08509: destination for restored datafile number=4 filename=/users/dba15/data01DBA15_1.dbf
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.18.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08016: channel d1: started datafile restore
RMAN-08019: channel d1: restoring datafile number 5
RMAN-08509: destination for restored datafile number=5 filename=/users/dba15/data01DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 6
RMAN-08509: destination for restored datafile number=6 filename=/users/dba15/data02DBA15_1.dbf
RMAN-08019: channel d1: restoring datafile number 7
RMAN-08509: destination for restored datafile number=7 filename=/users/dba15/data02DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 8
RMAN-08509: destination for restored datafile number=8 filename=/users/dba15/data03DBA15_1.dbf
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.19.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08016: channel d1: started datafile restore
RMAN-08019: channel d1: restoring datafile number 9
RMAN-08509: destination for restored datafile number=9 filename=/users/dba15/data03DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 10
RMAN-08509: destination for restored datafile number=10 filename=/users/dba15/data04DBA15_1.dbf
RMAN-08019: channel d1: restoring datafile number 11
RMAN-08509: destination for restored datafile number=11 filename=/users/dba15/data04DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 12
RMAN-08509: destination for restored datafile number=12 filename=/users/dba15/index01DBA15_1.dbf
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.20.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08016: channel d1: started datafile restore
RMAN-08019: channel d1: restoring datafile number 13
RMAN-08509: destination for restored datafile number=13 filename=/users/dba15/index01DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 14
RMAN-08509: destination for restored datafile number=14 filename=/users/dba15/index02DBA15_1.dbf
RMAN-08019: channel d1: restoring datafile number 15
RMAN-08509: destination for restored datafile number=15 filename=/users/dba15/index02DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 16
RMAN-08509: destination for restored datafile number=16 filename=/users/dba15/index03DBA15_1.dbf
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.21.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08016: channel d1: started datafile restore
RMAN-08019: channel d1: restoring datafile number 17
RMAN-08509: destination for restored datafile number=17 filename=/users/dba15/index03DBA15_2.dbf
RMAN-08019: channel d1: restoring datafile number 18
RMAN-08509: destination for restored datafile number=18 filename=/users/dba15/index04DBA15_1.dbf
RMAN-08019: channel d1: restoring datafile number 19
RMAN-08509: destination for restored datafile number=19 filename=/users/dba15/index04DBA15_2.dbf
RMAN-08023: channel d1: restored backup piece 1
RMAN-08511: piece handle=/users/dba15/BACK/back_DBA15_full.22.1 params=NULL
RMAN-08024: channel d1: restore complete
RMAN-08031: released channel: d1
RMAN>
10. Exit recovery manager.
Enter server manager and do a "fake" recovery using :
recover database until cancel using backup controlfile;
RMAN> exit
Recovery Manager complete.
$ svrmgrl
Oracle Server Manager Release 3.0.2.0.0 - Beta
Copyright (c) Oracle Corporation 1994, 1995. All rights reserved.
Oracle8 Server Release 8.0.2.0.0 - Beta
With the distributed, heterogeneous, replication, objects,
parallel query and Spatial Data options
PL/SQL Release 3.0.2.0.0 - Beta
SVRMGR> connect internal
Connected.
SVRMGR> recover database until cancel using backup controlfile;
ORA-00279: change 134717 generated at 03/17/97 23:05:27 needed for thread 1
ORA-00289: suggestion : /oracle/app/oracle/product/8.0.2/dbs/arch1_623.dbf
ORA-00280: change 134717 for thread 1 is in sequence #623
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
CANCEL
Media recovery cancelled.
SVRMGR>
11. Open the database with the resetlog option.
SVRMGR> alter database open resetlogs;
Statement processed.
SVRMGR>
12. Reset the database from recovery manager.
(Needs to be done after an incomplete recovery)
$ rman target=\"internal/admin@DBA15\" rcvcat=\"dba15/dba15@DBA16\"
Recovery Manager: Release 8.0.2.0.0 - Beta
RMAN-06005: connected to target database: DBA15
RMAN-06008: connected to recovery catalog database
RMAN> reset database;
RMAN-08006: database registered in recovery catalog
RMAN-08002: starting full resync of recovery catalog
RMAN-08029: snapshot controlfile name set to default value: ?/dbs/snapcf_@.f
RMAN-08004: full resync complete
RMAN>
13. Check how many incarnations of your database you have now.
RMAN> list incarnation of database "DBA15";
RMAN-06240: List of Database Incarnations
RMAN-06241: DB Key Inc Key DB Name DB ID CUR Reset SCN Reset Time
RMAN-06242: ------- ------- -------- ---------------- --- ---------- -------
RMAN-06243: 1 2 DBA15 4045670789 NO 1 18-FEB-97
RMAN-06243: 1 2172 DBA15 4045670789 YES 134718 18-MAR-97
출처 : -
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
|---|---|
| ORA-04031 에러 : 메모리 단편화 (0) | 2006.05.09 |
| [Oracle]오라클 어드민 팁 (0) | 2006.03.17 |
| 오라클 SID변경 작업 (0) | 2006.03.09 |
| [펌] isqlplusdba / 브라우저에서 dba 로 접속하기!!! (0) | 2005.05.25 |
ORACLE_SID를 변경하는 방법에 관한 자료
Explanation
-----------
1. 먼저 변경하고자 하는 SID를 v$thread 로 확인한다.
SVRMGR> select instance from v$thread;
INSTANCE
----------------
RC815UT
1 row selected.
2. DB를 shutdown한다. (shutdown normal or immediate)
3. Full backup을 받는다.(All control, redo, data files backup)
1) datafiles
SVRMGR> select file_name from dba_data_files;
FILE_NAME
----------------------------------------------------
/mnt2/data/RC815UT/oradata/system01.dbf
/mnt2/data/RC815UT/oradata/rbs01.dbf
/mnt2/data/RC815UT/oradata/tools01.dbf
/mnt2/data/RC815UT/oradata/users01.dbf
/mnt2/data/RC815UT/oradata/temp01.dbf
2) redo log files
SVRMGR> select group#, member from v$logfile;
GROUP# MEMBER
---------- -----------------------------------------
1 /mnt2/data/RC815UT/oradata/redoRC815UT01.log
2 /mnt2/data/RC815UT/oradata/redoRC815UT02.log
3 /mnt2/data/RC815UT/oradata/redoRC815UT03.log
3 rows selected.
3) control files
SVRMGR> select name from v$controlfile;
NAME
----------------------------------------------------
/mnt2/data/RC815UT/oradata/control01.ctl
/mnt2/data/RC815UT/oradata/control02.ctl
/mnt2/data/RC815UT/oradata/control03.ctl
3 rows selected.
4) full backup
SVRMGR> ! cp /mnt2/data/RC815UT/oradata/* /mnt3/rctest8i/backup
4. .profile, .cshrc, .login, oratab, tnsnames.ora 파일에
ORACLE_SID가 설정되어있다면 이를 모두 새로운 ORACLE_SID명으로 변경시킨다.
OLD ORACLE_SID : RC815UT
NEW ORACLE_SID: RC815NEW
5. $ORACLE_HOME/dbs directory에서 새로운 SID명을 사용하기 위해 다음 파일을 수정한다.
1) initSID.ora 를 새로운 initSID.ora로 rename한다.
initRC815UT.ora -> initRC815NEW.ora
2) initSID.ora file의 ifile에 설정한 configuration parameters 파일도 rename한다.
configRC815UT.ora -> contifRC815NEW.ora
3) initSID.ora와 configSID.ora 파일에 예전 ORACLE_SID관련 사항이 있으면
새로운 ORACLE_SID로 모두 변경한다.
예) initSID.ora
OLD) ifile = /mnt2/data/RC815UT/pfile/configRC815UT.ora
NEW) ifile = /mnt2/data/RC815UT/pfile/configRC815NEW.ora
6. Optional!!!
-> 기존의 SID명을 가진 data file이나 redo log file을 이용시 6번은 skip해도 된다.
만약 ORACLE_SID를 변경하면서 datafile이나 redo log file 이름도 새로운
SID명으로 함께 변경하려면 새로운 SID명의 디렉토리를 생성하여 mv로 기존 datafile과
redo log file을 모두 옮긴뒤 alter 문으로 rename한다.
기존의 /mnt2/data/RC815UT 에 있는 datafile과 redo log file을 새로운 SID명인
RC815NEW 디렉토리로 unix command 'mv'를 이용하여 모두 이동시킨다.
$mnt2/data/RC815UT> cd..
$mnt2/data> mkdir RC815NEW
$mv mnt2/data/RC815UT/redo* /mnt2/data/RC815NEW
$mv mnt2/data/RC815UT/system01.dbf /mnt2/data/RC815NEW
$mv mnt2/data/RC815UT/rbs01.dbf /mnt2/data/RC815NEW
$mv mnt2/data/RC815UT/tools01.dbf /mnt2/data/RC815NEW
$mv mnt2/data/RC815UT/users01.dbf /mnt2/data/RC815NEW
$mv mnt2/data/RC815UT/temp01.dbf /mnt2/data/RC815NEW
$svrmgrl>
SVRMGR> startup mount
SVRMGR> alter database rename file '/mnt2/data/RC815UT/redoRC815UT01.log' to '/mnt2/data/RC815NEW/redoRC815NEW01.log'
...
7. $ORACLE_HOME/dbs 밑에 orapw<OLD_SID> 가 있으면 새로운 password file로 rename 작업을 수행한다.
만약 orapw<OLD_SID>가 없으면 8번은 넘어간다.
그리고 새로운 orapw<NEW_SID>를 생성하고 싶으면 아래 COMMAND를 이용한다.
orapwd file=orapw<NEWSID password=?? entries=<number of user to be
granted permission to start the database instance>
8. db를 startup하고 shutdown한 다음 full backup을 수행한다.
(backup control, redo, data f iles)
9. 변경된 .profile을 적용하기 위해 다음을 수행한다.
$. ./.profile 을 실행하거나
$export ORACLE_SID=RC815NEW
command를 수행한다.
10. db를 startup 한다.
11. select instance from v$thread;
로 변경된 ORACLE_SID를 확인한다.
SVRMGR> select instance from v$thread;
INSTANCE
----------------
RC815NEW
1 row selected.
12. 기존에 SID명이 기록되어있는 파일들을 수정한다.
$ORACLE_HOME/network/admin/listener.ora 의 SID를 RC815NEW 로 수정
$ORACLE_HOME/network/admin/tnsnames.ora의 SID를 RC815NEW 로 수정
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
|---|---|
| ORA-04031 에러 : 메모리 단편화 (0) | 2006.05.09 |
| [Oracle]오라클 어드민 팁 (0) | 2006.03.17 |
| Oracle 장애의 유형과 문제해결 (0) | 2006.03.15 |
| [펌] isqlplusdba / 브라우저에서 dba 로 접속하기!!! (0) | 2005.05.25 |
1. 설치를 위한 기본 환경
- 메모리 권장 : 128 MB 이상
- HDD : 1 GB정도의 빈 공간.
- CPU : Celeron 366 혹은 펜티엄 II 350 이상 .
위의 사양은 말 그대로 설치를 위한 최소사양이다. 위 내용중 메모리는 256MB를 장착하면 쾌적하게 오라클을 설치하여 사용할 수 있다. 128MB와 256MB의 차이점은 오라클 설치에 필요한 소요시간에서도 명확히 나타난다.
2. ROOT 권한하에서 할 일.
가. ORACLE 계정 등록
- 오라클 설치 및 운영을 위한 USER 계정을 새로 만든다. (admintool을 이용하는 것이 편하다) 아래와 같이 설정해주면 된다.
* 사용자명 : oracle (임의로 설정가능)
* Primary Group : oinstall
* Secondary Group : dba
* 홈 디렉토리 : /ora (임의로 설정 가능. 단 오라클 홈 디렉토리와는 절대로 일치시키지 말 것. 과거 리눅스용은 오라클 홈 디렉토리로 사용자 홈 디렉토리를 설정하였으나 솔라리스용은 다르다)
* Login Shell : Bourne shell (/bin/sh)
나. 솔라리스 커널 Parameter 설정
/etc/system 파일 맨 밑부분에 아래 내용을 삽입한다.
set shmsys:shminfo_shmmax=4294967295
set shmsys:shminfo_shmmin=1
set shmsys:shminfo_shmmni=100
set shmsys:shminfo_shmseg=10
set semsys:seminfo_semmni=100
set semsys:seminfo_semmsl=100
set semsys:seminfo_semmns=200
set semsys:seminfo_semopm=100
set semsys:seminfo_semvmx=32767
** 상기 사항을 입력할 때 주의하세요. 오타가 나면 부팅시 에러메시지가 나타납니다.
다. 환경변수 설정
- oracle user의 환경변수를 설정해준다. oracle user의 홈 디렉토리안에 있는 .profile을 수정해주면 된다.
* DISPLAY=deskpia(자신의 워크스테이션 이름):0.0
* ORACLE_HOME=/export/home/OraHome1
* PATH=/usr/bin:/usr/ccs/bin:/usr/ucb:/etc:$ORACLE_HOME/bin:/bin:/opt/bin
* TMDIR=/var/tmp
* umask=022
* ORACLE_OWNER=oracle
** 주의사항 : oracle 계정은 위에 언급한 대로 Bourne shell을 사용한다. C shell과는 달리 Bourne shell이나 Korn shell에서는 환경변수를 지정한후에는 반드시 export 명령을 주어야만이 변수가 적용된다.
예를 들어 위에서 설정한 ORACLE_HOME=/export/home/OraHome1 의 경우에도 밑줄에 export ORACLE_HOME 을 추가로 설정해 주어야 된다.
여기까지는 oracle을 인스톨하기 전에 만들어준다.
라. oracle 홈디렉토리의 사용권한 설정
- oracle user가 새로이 생성될 오라클 홈디렉토리에 쓰기권한을 가질 수 있도록 해주는 것이다. 만일 오라클 홈디렉토리가 위에 지정한 것처럼 /export/home/OraHome1이라면..
# chown oracle:oinstall /export/home
이렇게 지정해주면 된다.
root 권한하에서 할 일을 마쳤으면 이제 새로 생성한 oracle user로 다시 login하여 다음 작업을 수행해주자.
가. umask 값 확인
- umask라고 쉘에서 입력했을 때 0022값이 나오면 된다. 다른값이 나왔다면 .profile에서 umask 설정을 잘못해준 것이다.
4. oracle 데이터베이스 설치
아래 내용은 모두 oracle 사용자로 로긴하여 수행해야 하는 일이다. 절대 root로 login하지 말기 바란다.
가. 로긴시 언어설정
가장 애를 먹은 부분이다. 이제껏 기본적으로 한글 (Korean) 환경에서 솔라리스를 수행하여 왔을 것이다. 그러나 Oracle database를 설치할 때 만큼은 영어환경에서 설치를 해주도록 하자. 그 이유는.... 한글환경에서 설치를 해보면 안다. Oracle Database Configuration Assistant를 수행할 때 나오는 원인모를 에러.. 그리고 멈춤. 이것 때문에 며칠을 허송세월하였다. 결국 오라클 사용자모임의 게시판에서 해답을 얻을 수 있었다.
나. Oracle 8i CD 삽입
다 아는 내용이겠지만 솔라리스는 CD를 삽입함과 동시에 자동으로 CD를 마운트해준다. 오라클 CD를 넣으면 CD의 루트 디렉토리에 있는 파일들이 파일관리자 화면에 보일 것이다. 여기서 아래에 흰색으로 표시된 runInstaller 파일을 수행시키면 된다. 마우스로 더블클릭해보자. JAVA를 기반으로 한 멋진 GUI환경의 Universal Installer Program이 실행된다.
오라클 CD를 넣었을 때 나타나는 파일매니저

다. Oracle 8i 설치
설치 프로그램 화면을 따라가면서 설치를 수행하자.
설치도중 tmp/OraInstall/orainstRoot.sh 스크립트 파일을 root 권한으로 수행하라고 나온다. (물론 새로 root로 로긴하라는 것이 아니고 잠시 su를 이용 root권한을 가지고 하면 된다)
File location 지정화면은 특별한 이유가 없는 이상 시스템에서 기본적으로 지정하는 위치에 설치하면 된다.
설치하는 유형을 선택하는 메뉴는 다음 3가지로 나뉜다.
1) Oracle Enterprise Edition 8.1.5 : Oracle db server와 관련된 모든 프로그램
2) Oracle 8i Client 8.1.5 : client용 프로그램
3) Oracle Programmer 8.1.5 : 기본적인 클라이언트 프로그램 (Net8, SQL*Pluse) 및 프리 컴파일러, 도움말등.
위에서 자신에게 알맞는 사항을 선택후 Next 버튼을 누르면 설치유형 선택화면이 나온다. 여기서 Custom을 선택하여야만 프로그램 및 데이터베이스에서 사용할 언어를 선택할 수 있다.
다음 화면은 설치가 가능한 각 프로덕트가 박스안에 나열된다. 상단의 'Product Language'를 클릭하면 설치할 언어를 선택할 수 있다. 기본적으로는 'English'로 되어있겠지만 이것을 'Korean'으로 변경한다.
Java Runtime Applicaiton의 경로설정 및 보안인증방법 (Authentification Methods) 설정부분은 그냥 Next 버튼을 누르면 기본값으로 설정된다.
Oracle Home Directory는 기본적으로 export/home/OraHome1으로 되어있을 것이다. 설정된 기본값 그대로 하면 된다.
오라클 소프트웨어를 갱신할 수 있는 UNIX 그룹을 지정하라고 나오면 oinstall을 입력한다.
설치에 필요한파일이 복사되는 과정이 진행된다.
라. Net8 Configuration
맨 아래 참조.
** 설치중 정해주어야 할 값.
Oracle SID: 4-5자정도의 짧은 알파벳 이름을 지어준다. 이값은 추후 .profile에도 설정해주어야 하므로 잊지 않도록 한다. (Default : ORCL)
DB 명 : 역시 자기마음에 드는 이름을 지어준다
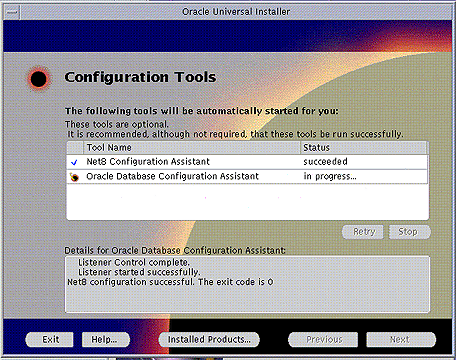
.
마. 데이터베이스 생성
설치 후반부로 가면 자동으로 수행에 필요한 데이터베이스 생성으로 들어간다. (Oracle Database Configuration Assistant) 데이터베이스 생성 옵션으로서는 설치 CD에 있는 데이터베이스 파일 복사를 선택하면 된다. 데이터베이스 생성작업에 소요되는 시간은 시스템 메모리 크기에 따라 차이가 있을 것이다. (메모리가 클수록 소요시간은 짧아진다)
바. root.sh 실행
필요한 파일 설치가 끝나고 링크작업이 완료되면 Oracle Home 디렉토리에 있는 root.sh를 root권한으로 실행하라는 메시지가 나온다. 이것을 실행시켜도 실행이 되지 않을 경우에는 chmod 명령을 사용하여 root.sh의 속성을 실행가능 파일로 바꿔준다.
실행후 ORACLE_OWNER, ORACLE_HOME, ORACLE_SID의 설정값이 나오면 이것을 확인해둔다. local bin 디렉토리의 full path명은 자신의 시스템에 설정된 값으로 고쳐준다. (예. /usr/bin)
모든 설치가 끝나게 되면 아래와 같은 엔딩 화면을 보게된다. 이걸 보기위하여 얼마나 많은 노력을 하였는가.... 라고 생각하면 안된다. 아직 확인해야 할 일이 많다.
5. 설치후 해야할 일
가. 환경변수 추가 설정
- oracle user의 환경변수를 추가로 설정해준다. 설치하기 전과 마찬가지로 oracle user의 홈 디렉토리안에 있는 .profile을 수정해주면 된다.
* ORACLE_SID= 아까 설정한 값을 넣어준다. (예 : ORCL등)
* CLASSPATH=/export/home/jre/1.1.7/bin:$ORACLE_HOME/jlib
* LD_LIBRARY_PATH=$ORACLE_HOME/lib
** 참고로 필자의 oracle 계정에 설정한 .profile값을 공개한다. 여기서 DISPLAY 변수에 나오는 서버명(deskpia)은 여러분의 시스템에 맞게 수정해야 한다. 나머지 사항은 대체로 동일하게 설정해도 되는 사항들이다.
tty istrip
DISPLAY=deskpia:0.0
export DISPLAY
ORACLE_HOME=/export/home/OraHome1
export ORACLE_HOME
PATH=/usr/bin:/usr/ccs/bin:/usr/ucb:/etc:$ORACLE_HOME/bin:/bin:/opt/bin
export PATH
TMDIR=/var/tmp
export TMDIR
umaks=022
export umask
ORACLE_OWNER=oracle
export ORACLE_OWNER
ORACLE_SID=ORCL
export ORACLE_SID
CLASSPATH=/export/home/jre/1.1.7/bin:$ORACLE_HOME/jlib
LD_LIBRARY_PATH=/usr/java/lib:$ORACLE_HOME/lib
이제 시스템을 rebooting후 oracle user로 새로이 login한다.
가. 이미 path가 지정되어 있으므로 곧바로 아래와 같이 쉘에서 입력해보자.
$ svrmgrl
아래와 같이 화면이 나타나면 1차 성공이다.
Oracle Server Manager Release 3.1.5.0.0 - Production
(c) Copyright 1997. Oracle Coprporation. All Rights Reserved.
Oracle8i Enterprise Edition Release 8.1.5.0.0 - Production
with the Partitioning and Java options
PL/SQL Release 8.1.5.0.0 - Production
SVRMGR>
나. 이제 데이터베이스에 연결해본다.
SVRMGR> connect internal
Connected 라고 나오면 된다. 여기서 Connected라는 메시지와 함께 어떤 error 메시지가 나온다면 오라클 db가 정상적으로 설치되지 못한 것이다.
다. 다음으로는 데이터베이스를 구동시킨다.
SVRMGR> startup
잠시후 아래와 같이 메시지가 나오면 성공적으로 데이터베이스가 구동되고 있는 것이다.
** 아래 수치는 시스템에 따라 다를 수 있음 **
Oracle instance started
Total System Global Area 35028368 bytes
Fixed Size 64912 bytes
Variable Size 18014208 bytes
Database Buffers 16777216 bytes
Redo Buffers 172032 bytes
Database mounted.
Database Opened.
라. 내친김에 데이터베이스에 있는 테이블들을 살펴보자.
SVRMGR> select * from tab;
수많은 테이블들이 주욱 나오면서 마지막에 다음 메시지가 나올 것이다.
1433 rows selected.
이제 오라클 데이터베이스 설치라는 기나긴 여정이 끝났다. 남은 일은 dba로서 해야 할 일이다. 항상 끝마칠 때 shutdown을 잊지 않으면 아무런 문제없이 oracle DB를 사용할 수 있을 것이다.
p.s. http://technet.oracle.com으로 가면 오라클 데이터베이스에 관한 아주 많은 자료들이 체계적으로 정리되어 있다. 이것을 이용하려면 회원으로 가입하면 된다. 회비는 무료이다. 물론 모든 자료는 영어로 되어 있다.
Database 설치에 웬 네트웍 ? 하실지도 모르겠다. 오라클은 클라이언트/서버 환경에서 수많은 고객을 만족시켜온 데이터베이스이다. (지금도 많이 쓰이고 있지만). 서버에 설치된 하나의 오라클 엔터프라이즈 에디션만 있으면 클라이언트는 아주 경량화된 클라이언트 component만을 자신의 PC에 설치해서 오라클을 기반으로 한 응용 프로그램을 실행시킬 수 있다. 이때 서버와 클라이언트간의 연결은 네트웍을 통하여 이루어지게 된다. 이러한 Client/Server간의 통신을 위하여 설정해주어야 하는 부분이 바로 네트웍 설정이다. 본격적인 설정에 앞서서 네트웍 설정에 나오는 용어 몇가지를 정리하도록 해보자. client측이 오라클 서버로 접속할 수 있도록 필요한 프로토콜 및 포트번호(주로 1521) 를 설정해 주는 파일로서 서버에 위치한다. protocol로서는 주로 tcp/ip가 사용될 것이다. 이제 오라클 DB 설치도중 나오는 Net8 Configuration 설정과정을 예로 들면서 하나씩 알아보도록 한다. 오라클을 설치하다보면 Configuration tools라는 그래픽 박스가 나타나면서 가. Net8 Configuration 제일 먼저 화면에는 Listener configuration과 Naming Method configuration을 시작하고자 한다는 정중한 메시지가 나온다. 말 그대로 Listner와 Naming Method를 설정하는 부분이다. Next 버튼을 클릭하면 Listener의 이름을 지어달라고 부탁하는 화면이 나올 것이다. 여기서 Listener의 이름 작명에 머리아파하지 말자. 기본값으로 LISTNER라고 나올 것이다. 이걸 그대로 사용하면 된다. (물론 사용자가 자기 이름으로 변경해도 된다.) 다음으로는 리스너 프로세서가 사용할 통신 프로토콜을 설정하자. 이부분은 자신의 시스템이 사용하는 프로토콜을 선택하면 된다. (일반적으로 TCP/IP라 생각되는데...) TCP/IP Client Type 화면에서는 선택된 프로토콜이 어떤 클라이언트 유형에 적용될지를 선택할 수 있다. 일번적인 C/S환경에서는 'Net8 Client'를 선택한다. 인터넷과 관련된 클라이언트 유형이라면 IIOP Clients를 선택할 수 도 있다. 다음 화면에서는 사용할 TCP/IP Port number를 지정하게 된다. 기본값은 1521이 된다. 여기서 한가지 주의사항이 있다. 지정된 포트를 제대로 사용하려면 솔라리스의 etc/services 파일에 'listener 1521/tcp'라는 값이 설정되어 있어야 한다. 물론 여러분이 처음 오라클을 설치하였다면 설정이 되어있을리 만무하다. 오라클 설치를 모두 마친후에, 파일을 열어서 꼭 설정해주도록 하자. (설정후에는 시스템을 리부팅해주어야 한다) 만일 여러분이 설치한 오라클 서버에 수많은 사용자들이 동시에 접속해야 한다면 리스너 프로세서 하나만으로는 모자라는 경우가 생길 수 있다. 이 경우에는 리스너를 하나이상 설치해 주어야 한다. 'More Listner ?' 화면에서는 이러할 때를 대비하여 복수 리스너를 설치할 수 있도록 해준다. 그러나 일반적으로는 하나의 Listner로도 충분하므로 'No'를 선택하자. 리스너 설치가 완료되면 다음으로는 Naming Method 설치메뉴가 나온다. 여러분이 속해있는 네트워크에 여러개의 데이터베이스가 설치되어 운영중이라면 Named Server를 설치하여 오라클 데이터베이스에 접속할때의 환경을 만들어 주어야 한다. 그렇지 않고 오라클 데이터베이스만을 사용한다면 이것 역시 'No'를 선택하고 넘어가면 된다. 이것을 마치면 Net8 Configuration Assistance 설치가 모두 완료되었다는 화면이 나온다. 나. 리스너 동작상태 확인 작동을 멋지게 시작할 것이다. 그래도 작동을 하지 않는다면... 위에서 언급한 etc/services 파일에 'listener 1521/tcp'라는 값이 설정되어 있는지를 확인해보자. 대부분 이것이 제대로 설정되어 있지 않아 일어나는 불상사이다.
![]() Oracle 8i 설치를 위한 네트웍 설정
Oracle 8i 설치를 위한 네트웍 설정
2) tnsnames.ora : client측에서 오라클 서버로 접속할때 필요한 프로토콜 및 포트번호, 서버주소, 인스턴스등을 설정해주는 파일로서 클라이언트에 위치한다.
** linstener.ora와 tnsnames.ora는 둘다 Net8 configuration 작업을 해주면 자동으로 설정된 값에 의거하여 만들어지는 파일들이다. 위에서 명시한바와 같이 둘의 이름은 다를지언정 추구하는 목적은 똑같다. (listener는 서버용, tns는 클라이언트용)
이 과정이 수행된다.
이제껏 설치한 서버의 리스너가 잘 동작하는지 동작상태를 확인해보자.
$ lsnrctl status 라는 명령을 주면 된다.
만약 protocal adapter error니 no listener니 하는 에러메시지가 잔뜩 나오면서 작동을 하지 않고 있으면 ... 실망하지 말고 아래 명령어를 실행해보자.
$ lsnrctl start listener
| Linux x86에 oracle 10g 설치하기 위한 시스템 요구사항 (0) | 2006.11.23 |
|---|---|
| LINUX오라클 설치 (0) | 2006.06.27 |
| ORACLE DATABASE 재설치하기 (0) | 2006.06.07 |
| [펌] Redhat 9.0 기반에서 오라클 9.2.0 설치 (0) | 2005.05.25 |
| [펌] 레드헷+오라클 설치하기 (0) | 2005.05.25 |
문서에 적힌 대로 몇줄만 그대로 따라해보니 접속이 됩니다.
형식은 다음과 같습니다
htpasswd [-cmdps] passwordfile username
다음은 사용예입니다.
C:\oracle\ora92\Apache\Apache\bin\htpasswd -c C:\oracle\ora92\sqlplus\admin\iplusdba.pw hr(유저명)
유저네임까지쓰고 엔터 그리고 패스워드/패스워드확인을 마치면 패스워드파일이 생성됩니다.
그리고 아래와 같이 주소창에 입력합니다.(각자의 환경에 맞추어서)
http://61.109.232.86:7778/isqlplusdba
으로 접속하면 네트웍인증창이 뜨면, 위에서 생성된 유저명과 패스워드로 인증을 합니다.
그러면, 다음과 같은
isqlplusdba 라는 반가운 창이 뜹니다
해당 접속정보를 입력하면 프롬프트상에서와 똑같이 DB를 내리고 올릴수 있는
막강 SYSDBA로서의 임무를 감당할 수 있습니다.
신기하지 않습니까? 난 참 신기한데......즐휴일...
| open_cursor의 개수를 보는 방법 (0) | 2006.06.09 |
|---|---|
| ORA-04031 에러 : 메모리 단편화 (0) | 2006.05.09 |
| [Oracle]오라클 어드민 팁 (0) | 2006.03.17 |
| Oracle 장애의 유형과 문제해결 (0) | 2006.03.15 |
| 오라클 SID변경 작업 (0) | 2006.03.09 |
Redhat 9.0 기반에서 오라클 9.2.0 설치하기
INSTALL oracle9i On redhat 9.0
1. 참조문서
http://linux.oreillynet.com/lpt/a/4141
http://otn.oracle.co.kr/Starter/database/install/9ir2_install_viewlet_swf.html (강력추천)
2. 설치전 필요한 페키지
X-Window 필수
gcc-3.2.2-5
cpp-3.2.2-5
glibc-devel-2.3.2-11.9
binutils-2.13.90.0.18-9
compat-gcc-7.3-2.96.118.i386.rpm
compat-libgcj-7.3-2.96.118.i386.rpm
compat-libgcj-devel-7.3-2.96.118.i386.rpm
nss_db-compat-2.2-20.i386.rpm
pdksh-5.2.14-21
libncursers
3. 다운로드 소스
http://otn.oracle.com/software/products/oracle9i/htdocs/linuxsoft.html
적당한곳에 3개의 파일을 받아 압축을 푼다.
# zcat lnx_920_disk1.cpio.gz | cpio -idmv <-- http로 받지 않았을 때
# cpio -idmv < lnx_920_disk1.cpio.gz.cpio.gz <-- http로 받았을 때
4. 계정 및 그룹생성 시스템 설정
# groupadd dba
# adduser -g dba oracle
# vi /etc/sysctl.conf
kernel.shmmax = 536870912
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
# vi /etc/security/limits.conf
oracle soft nofile 65536
oracle hard nofile 65536
oracle soft nproc 16384
oracle hard nproc 16384
만약 리붓팅하지 않을려면 다음과 같이한다.
# echo 250 32000 100 128 > /proc/sys/kernel/sem
# echo 536870912 > /proc/sys/kernel/shmmax
# echo 4096 > /proc/sys/kernel/shmmni
# echo 2097152 > /proc/sys/kernel/shmall
# echo 65536 > /proc/sys/fs/file-max
# echo 1024 65000 > /proc/sys/net/ipv4/ip_local_port_range
오라클은 최소 512MB의 메모리와 400MB의 스왑 공간을 필요로 한다. 따라서 부족하다면
임시적으로 스왑공간을 아래와 같이 만들어준다.
# dd if=/dev/zero of=tmp_swap bs=1k count=900000
# chmod 600 tmp_swap
# mkswap tmp_swap
# swapon tmp_swap
스왑해제
# swapoff tmp_swp
# rm tmp_swap
5. 환경변수 설정(여기서 부터 oracle 계정으로 바꾼다.)
$ vi .bash_profile
export ORACLE_BASE=/home/oracle
export ORACLE_HOME=$ORACLE_BASE/product/9.2.0.1
export ORACLE_OWNER=oracle
export ORACLE_SID=oraccle
export ORACLE_TERM=xterm
#export TMPDIR=$ORACLE_BASE/tmp
#export TNS_ADMIN=$ORACLE_HOME/network/admin
export NLS_LANG='AMERICAN_AMERICA.KO16KSC5601'
export ORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/data
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$ORAClE_HOME/oracm/lib:/lib:/usr/lib:/usr/local/lib
export LANG=C
export LD_ASSUME_KERNEL=2.4.1
export THREADS_FLAG=native
export PATH=$PATH:$ORACLE_HOME/bin:$ORACLE_HOME/oracm/bin
CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib:$ORACLE_HOME/network/jlib
$ /Where/Disk1/runInstaller <- 오라클 소스압축푼 디렉터리
6. 5번의 과정이 성공적으로 끝났다면 설치창이 뜬다.
언어설정에 korean을 추가하고 설치는 custem으로하여 +sqlplus를 체크하고 넘어간다.
설치 중 두번의 에러메세지가 나온다.
Error in invoking target install of makefile
/usr/ora9/product/9.2/network/lib/ins_oemagent.mk
위의 경우 무시하고 지나간다.
Error in invoking target install of makefile
/usr/ora9/product/9.2/ctx/lib/ins_ctx.mk
위의 경우는 X terminel을 하나 더 띄우고 oracle 계정으로 아래순서대로 실행한다.
$ cd $ORACLE_HOME/install
$ tail make.log
gcc -o ctxhx -L/opt/ora9/product/9.2/ctx/lib/ -L/opt/ora9/product/9.2/lib/
-L/opt/ora9/product/9.2/lib/stubs/ /opt/ora9/product/9.2/ctx/lib/ctxhx.o
-L/opt/ora9/product/9.2/ctx/lib/ -lm -lsc_ca -lsc_fa -lsc_ex -lsc_da -lsc_ut
-lsc_ch -lsc_fi -lctxhx -lc -Wl,-rpath,/opt/ora9/product/9.2/ctx/lib -lnls9
-lcore9 -lnls9 -lcore9 -lnls9 -lxml9 -lcore9 -lunls9 -lnls9
긁어 붙인다음 -ldl 을 추가한 후 엔터한다.
100% 설치후 루트권한으로 아래 명령을 실행시키라는 메세지가 뜬다.
/home/oracle/product/9.2.0.1/root.sh
모든 과정이 다 끝났다.
이후의 설정이나 가지고 노는것(?)에 대해서는 잘 모르겠다....
처음깔아보는거라.. ^^;
9.0 으로 설치했지만 7.3에서도 적용됨.
오라클코리아 기술지원팀과 통화를 통해 알게되었는데 물론 오라클 홈페이지에도 언급이
된 내용이지만 레드핫 스탠다드 버젼에서는 7.2 기반에서 제작되었기 때문에 다른 버젼에서는
문제가 될수있다고한다. 물론 9.0에 설치했을때도 다운되는 문제가 생겼다. 설치시 다운된
시점의 로그를 살펴본다면 어떤문제인지 자세히 알수있을것이다.(기록하는 습관이 들지 않아 기록해
놓지 않았따.^^;) 오라클측에서는레드핫 엔터프라이즈버젼을 사용할것을 권고하고 있습니다.
저의 경험으로는 스탠다드 7.3 버젼에서도 무리없이 설치되고 구동되는것을 확인했습니다
---------------------------------------------------------------
| Linux x86에 oracle 10g 설치하기 위한 시스템 요구사항 (0) | 2006.11.23 |
|---|---|
| LINUX오라클 설치 (0) | 2006.06.27 |
| ORACLE DATABASE 재설치하기 (0) | 2006.06.07 |
| [펌] [SUN]Oralcle 8i 설치하기 (0) | 2006.01.26 |
| [펌] 레드헷+오라클 설치하기 (0) | 2005.05.25 |
 http://www.vader.co.kr
http://www.vader.co.kr http://www.vader.co.kr/bbs/view.php?id=Linux&page=1&sn1=&divpage=1&sn=off&ss=on&sc=on&select_arrange=headnum&desc=asc&no=18
http://www.vader.co.kr/bbs/view.php?id=Linux&page=1&sn1=&divpage=1&sn=off&ss=on&sc=on&select_arrange=headnum&desc=asc&no=18
◆ 설치환경
Pentium 4 CPU 2.6GHz
RAM 2GB
Microsoft Windows XP Professional Version 2002 Service Pack2
VMware Workstation 4.5.2 build-8848
Redhat Linux 9 (2.4.20) HDD 20GB, RAM 1740MB
◆ 계정 생성
[root@localhost root]# groupadd dba
[root@localhost root]# groupadd oinstall
[root@localhost root]# useradd -g oinstall -G dba oracle
[root@localhost root]# passwd oracle
◆ 디렉토리 생성
[root@localhost root]# mkdir -p /opt/ora9/product/9.2
[root@localhost root]# mkdir /var/opt/oracle
[root@localhost root]# chown oracle.dba /var/opt/oracle
[root@localhost root]# chown -R oracle.dba /opt/ora9
◆ 필수 RPM 파일 확인 및 설치
gcc-3.2.2-5
cpp-3.2.2-5
glibc-devel-2.3.2-11.9
binutils-2.13.90.0.18-9
compat-gcc-7.3-2.96.118.i386.rpm
compat-libgcj-7.3-2.96.118.i386.rpm
compat-libgcj-devel-7.3-2.96.118.i386.rpm
nss_db-compat-2.2-20.i386.rpm
설치되어 있지 않다면 http://rpmfind.net 에서 해당 rpm을 다운 받아 설치한다.
rpm -Uvh (package_name)
◆ Maximum Share Memory Size의 증가
/etc/sysctl.conf 를 vi로 열고 다음을 추가한다.
kernel.shmmax = 1073741824
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
/etc/security/limits.conf 에는 다음을 추가한다.
oracle soft nofile 65536
oracle hard nofile 65536
oracle soft nproc 16384
oracle hard nproc 16384
저장하고 재부팅.
◆ .bashrc 수정
다음을 추가한다.
#oracle 9i
export ORACLE_BASE=/opt/ora9
export ORACLE_HOME=/opt/ora9/product/9.2
export PATH=$ORACLE_HOME/bin:$ORACLE_HOME/Apache/Apache/bin:$PATH
export ORACLE_OWNER=oracle
export ORACLE_SID=ora9
export ORACLE_TERM=vt100
export LD_ASSUME_KERNEL=2.4.1
export THREADS_FLAG=native
export LD_LIBRARY_PATH=/opt/ora9/product/9.2/lib:$LD_LIBRARY_PATH
export PATH=/opt/ora9/product/9.2/bin:$PATH
export NLS_LANG=AMERICAN_AMERICA.KO16KSC5601;
◆ Oracle 설치 파일 다운로드
다운로드 : http://www.oracle.com/technology/software/products/oracle9i/htdocs/linuxsoft.html
다운 받은 파일의 압축을 풀어준다.
[oracle@localhost oracle]$ zcat ship_9204_linux_disk1.cpio.gz | cpio -idmv
[oracle@localhost oracle]$ zcat ship_9204_linux_disk2.cpio.gz | cpio -idmv
[oracle@localhost oracle]$ zcat ship_9204_linux_disk3.cpio.gz | cpio -idmv
◆ Oracle 설치
※ 만약 Redhat Linux9의 기본 언어가 한글로 설정되어 있다면 아래와 같이 한글이 깨진다. 이럴 경우 ./runInstaller를 실행하기 전에 한글을 패치한다.
Oracle 한글 패치
/home/oracle/Disk1/stage/Components/oracle.swd.jre/1.3.1.0.0/1/DataFiles/Expanded/jre/linux/lib/fonts 에 다음 파일을 업로드 한다.(클릭하면 다운 받을 수 있음)
batang.ttc
gulim.ttc
mingliu.ttc
fonts.dir
/home/oracle/Disk1/stage/Components/oracle.swd.jre/1.3.1.0.0/1/DataFiles/Expanded/jre/linux/lib 에 다음 파일을 업로드 한다.(클릭하면 다운 받을 수 있음)
font.properties.ko
[oracle@localhost oracle]$ chmod 755 -R /home/oracle/Disk1/stage/Components/oracle.swd.jre/1.3.1.0.0/1/DataFiles/Expanded/jre/linux/lib
[oracle@localhost oracle]$ chmod 755 -R /home/oracle/Disk1/stage/Components/oracle.swd.jre/1.3.1.0.0/1/DataFiles/Expanded/jre/linux/lib/fonts
oracle 계정으로 X window 에서 설치한다. 터미널 창을 열고 다음과 같이 실행.
[oracle@localhost oracle]$ cd Disk1
[oracle@localhost Disk1]$ ./runInstaller 
『다음』을 클릭
인벤토리 위치를 지정하고(수정할 필요 없음) 『확인』을 클릭한다.
dba를 입력하고>『다음』을 클릭
위와 같은 창이 뜨게되면
터미널 창을 열고 루트 권한으로 다음과 같이 실행하고 『계속』을 클릭.
[root@localhost root]# /tmp/orainstRoot.sh
Oracle 인벤토리 포인터 파일 생성 중 (/etc/oraInst.loc)
그룹 이름 변경 중 /opt/ora9/oraInventory 대상 dba.
『다음』을 클릭.


데이터베이스는 생성하지않고 프로그램만 설치한다.


위와 같은 창이 뜨면 터미널에서 루트 권한으로 /opt/ora9/product/9.2/root.sh 를 실행하고 『확인』을 클릭한다.
◆ Database 생성
[oracle@localhost oracle]$ cd $ORACLE_HOME/bin
[oracle@localhost bin]$ ./dbca


『New Database』선택








『데이터 딕셔너리 뷰 생성』단계에서 『ORA-29807 : specified operator does not exist』오류가 발생함.
이것은 알려진 문제로(Bug: 2686156) 무시해도 됨. 『무시』를 클릭하고 계속 진행
『Oracle Spatial 추가』 단계에서 『ORA-01430』에러가 발생하는데 이것 또한 알려진 문제로 무시해도 상관없음. 『무시』를 클릭하고 계속 진행
설치 마지막 부분에서 패스워드를 설정하고 『종료』를 클릭하면 아무런 반응이 없었음.
데이터 베이스 생성은 완료 된것 같아 X윈도우를 강제 종료하였음.(버그인 듯)
◆ 테이블 스페이스와 사용자의 생성, 권한설정
[oracle@localhost ora9]$ sqlplus /nolog
SQL*Plus: Release 9.2.0.4.0 - Production on Thu May 12 16:55:30 2005
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
SQL> connect /as sysdba
Connected.
SQL> create tablespace vader
2 datafile '/opt/ora9/oradata/ora9/vader.dbf' size 500M;
Tablespace created.
==> 500MB 의 크기로 vader라는 테이블스페이스를 생성함.
SQL> create user vader identified by passwd
2 default tablespace vader
3 temporary tablespace temp;
User created.
==> 패스워드가 "passwd"인 vader라는 사용자를 생성.
SQL> grant create session to vader with admin option;
Grant succeeded.
SQL> grant create table to vader with admin option;
Grant succeeded.
SQL> grant create view to vader;
Grant succeeded.
SQL> alter user vader quota unlimited on vader;
User altered.
==>vader 사용자에게 데이터베이스 접속, 테이블, 뷰 생성 권한을 부여한다.
◆ Listener 설정
[oracle@localhost oracle]$ cd $ORACLE_HOME/newwork/admin
[oracle@localhost admin]$ vi listener.ora
※ 서버 IP를 입력
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC))
)
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.32.130)(PORT = 1521))
)
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = ora9)
(ORACLE_HOME = /opt/ora9/product/9.2)
(SID_NAME = ora9)
)
)
[oracle@localhost admin]$ vi tnsnames.ora
※ 서버 IP를 입력
ORA9 =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.32.130)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = ora9)
)
)
◆ TEST
[oracle@localhost admin]$ sqlplus /nolog
SQL*Plus: Release 9.2.0.4.0 - Production on Thu May 12 18:34:15 2005
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
SQL> connect /as sysdba
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 236000356 bytes
Fixed Size 451684 bytes
Variable Size 201326592 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
Database mounted.
Database opened.
SQL> exit
Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
[oracle@localhost admin]$ lsnrctl start
LSNRCTL for Linux: Version 9.2.0.4.0 - Production on 12-MAY-2005 18:35:03
Copyright (c) 1991, 2002, Oracle Corporation. All rights reserved.
Starting /opt/ora9/product/9.2/bin/tnslsnr: please wait...
TNSLSNR for Linux: Version 9.2.0.4.0 - Production
System parameter file is /opt/ora9/product/9.2/network/admin/listener.ora
Log messages written to /opt/ora9/product/9.2/network/log/listener.log
Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC)))
Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.32.130)(PORT=1521)))
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC)))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 9.2.0.4.0 - Production
Start Date 12-MAY-2005 18:35:03
Uptime 0 days 0 hr. 0 min. 0 sec
Trace Level off
Security OFF
SNMP OFF
Listener Parameter File /opt/ora9/product/9.2/network/admin/listener.ora
Listener Log File /opt/ora9/product/9.2/network/log/listener.log
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.32.130)(PORT=1521)))
Services Summary...
Service "ora9" has 1 instance(s).
Instance "ora9", status UNKNOWN, has 1 handler(s) for this service...
The command completed successfully
[oracle@localhost admin]$ sqlplus vader/passwd@ora9
SQL*Plus: Release 9.2.0.4.0 - Production on Thu May 12 18:35:20 2005
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL>
※참고 : http://www.puschitz.com/InstallingOracle9i.shtml
※참고 : http://linux.oreillynet.com/lpt/a/4141
| Linux x86에 oracle 10g 설치하기 위한 시스템 요구사항 (0) | 2006.11.23 |
|---|---|
| LINUX오라클 설치 (0) | 2006.06.27 |
| ORACLE DATABASE 재설치하기 (0) | 2006.06.07 |
| [펌] [SUN]Oralcle 8i 설치하기 (0) | 2006.01.26 |
| [펌] Redhat 9.0 기반에서 오라클 9.2.0 설치 (0) | 2005.05.25 |

|