5. Data Pump Export 사용하기
이제 본격적으로 Data Pump Export 를 사용하는 방법과, 여러 가지 옵션들에 대해 살펴
보고, 실 상황에서 옵션들이 어덯게 동작하는지 테스트 해보는 시간을 가져 보도록 하겠습
니다.
1) 컴맨드 라인을 이용한 Data Pump 사용
$ expdp system/manager DIRECTORY=datapump_dir1 DUMPFILE=dangntong_dump01.dmp
컴맨드 라인을 이용하여 보기와 같이 expdp 를 사용하실 수 있습니다. 커맨들 라인을
이용 할 때는 비교적 적은 수의 옵션들이 사용되거나 간단한 구문일 때 이용하시는 것이
좋습니다. 복잡하고, 옵션이 많게 되면 수정 하거나, 잘못 타이핑할 때 시간이 많이
걸리게 됩니다.
2) 파라메타 파일을 이용한 Data Pump 사용
파라메타 파일에 다음과 같이 기록합니다. 파일명은 dangtong.par입니다.
ⓛ dangtong.par 파일을 다음과 같이 작성하세요
SCHEMAS=SCOTT
DIRECTORY=datapump_dir1
DUMPFILE=dangtong_dump01.dmp
LOGFILE=dangtong_dump.log
$ expdp dangtong/imsi00 PARFILE=dangtong.par
6. Data Pump Export 모드
1) Full export 모드
FULL 파라메타를 사용합니다.
데이터 베이스 전체를 export 받을수 있습니다. 한가지 주의 할점은
EXPORT_FULL_DATABASE 롤이 Full export 받고자 하는 사용자 에게 부여되어 있
어야 합니다.
2) 스키마 모드
SCHEMAS 파라메타를 사용합니다.
하나의 유저가 소유하고 있는 데이타및 오브젝트 전체를 export 받고자 할때 사용할 수
있는 모드입니다.
3) 테이블스페이스 모드
TABLESPACE 파라메타를 사용합니다.
하나 이상의 테이블스페이스에 대해 해당 테이블스페이스에 속한 모든 테이블을 받을수
있습니다. 만약 TRANSPORT_TABLESPACES 파라메타를 이용한다면, 테이블 뿐 아니라 테이
블스페이스의 메타데이타 까지 export 받게 되어 다른 서버에 dump 파일을 카피 한 후
import 하게 되면 테이블 스페이스 및 테이블이 자동으로 생성됩니다.
4) 테이블 모드
TABLES 파라메타를 사용합니다.
하나 이상의 테이블을 export 받을 때 사용합니다.
7. Data Pump Export 파라메타
1) 파일 및 디렉토리 관련 파라메타
파라메타 :DIRECTORY,DUMPFILE,FILESIZE,PARFILE,LOGFILE,NOLOGFILE,COMPRESSION
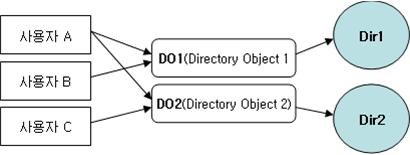
① DIRECTORY : 디렉토리 오브젝트를 참조 하는 DIRECTORY 파라메타를 이용하여
덤프 파일의 위치 및 로그 파일의 위치를 지정할 수 있습니다.
DIRECTORY=directory_object_name 형식으로 사용할 수 있습니다.
② DUMPFILE : Export 받아 파일시스템에 저장될 덤프파일의 이름을 지정하는 파
라메터 입니다. 파라메타를 사용할 때 다음을 기억하시고 사용하시면 됩니다.
- %U 를 사용하여 여러 개의 덤프 파일을 구분할 수 있습니다.
DUMPFILE=DANGTONG_DUMO_%U.dmp 로 파라메타를 정의 합니다. 만약 덤프 파일
이 10개가 생성 된다고 가정하면 DANGTONG_DUMO_01.dmp 부터 DANGTONG_DUMO_10.dmp
까지 %U 부분이 자동 증가하여 파일을 구분하여 줍니다. %U의 범위는 01~99 까
지입니다.
- ',' 를 이용하여 여러게의 파일명을 구분할 수 있습니다. 예를 들어 다음과 같이
DUMPFILE=DANGTONG_DUMO_01.dmp,DANGTONG_DUMO_02.dmp,DANGTONG_DUMO_03.dmp 라고
정의 할 수 있습니다.
- 만약 DUMPFILE 파라메타를 지정하지 않는다면 expdat.dmp 라는 파일명으로 오
라클이 자동 선언하게 됩니다.
③ FILESIZE : Export 받는 1개 파일의 최대 크기를 지정하는 파라메타 입니다.
만약 총데이터 량이 10Gigabyte 이고 FILESIZE 를 1Gigabyte 로 지정하였다면
1Gigabyte 크기의 dump file 이 10개 만들어 지게 됩니다.
FILESIZE=N [ BYTES | KILOBYTES | MEGABYTES | GIGABYTES ] 형식으로 쓸 수 있습
니다.
④ PARFILE : 파일에 파라메타 들을 저장해두고 Data Pump 를 이용할 때 마다 참조
하여 작업을 수행하고 싶을 때 PARFILE 파라메타 를 사용할 수 있습니다.
PARFILE=filename.par 형식으로 사용할 수 있으며, 파일 확장자는 아무런 영향을
미치지 않습니다.
⑤ LOGFILE and NOLOGFILE : 로그파일명을 지정하는 파라메타 입니다.
LOGFILE=logfile_name 형식으로 사용 하시면 됩니다. 파라메타 를 설정하지 않
는다면 export.log 라는 파일명으로 로그가 남게 됩니다. 로그파일을 남기고 싶
지 않을 때는 NOLOGFILE 파라메타 를 사용하시면 됩니다.
⑥ COMPRESSION : 오라클에서 EXPORT 시에 메타데이터는 압축을 하여 파일에 저장
하게 됩니다. COMPRESSION 파라메타를 사용 하지 않을 경우에는 덤프파일 내에
메타데이타가 압축되어 보관됩니다. COMPRESSION 파라메타 에는 METADATA_ONLY,
NONE 두개의 옵션이 있으며,METADATA_ONLY 는 파라메타를 사용하지 않으면 디펄
트로 인식되는 옵션입니다. COMPRESSION=OPTION_NAME 형식으로 사용하시면 됩니다.
$expdp dangtong/imsi00 DIRECTORY=datapump_dir1 DUMPFILE=dump.dmp COMPRESSION=NONE
2) Export 모드 관련 파라메타
파라메타 :FULL,SCHEMAS,TABLES,TABLESPACES,TRANSPORT_TABLESPACES
TRANSPORT_FULL_CHECK 가 있으며, TRANSPORT_FULL_CHECK 파라메타를 제외한 파라메타
들은 여러분들 께서 이미 "6. Data Pump Export 모드" 에서 학습 하셨습니다. 그럼
TRANSPORT_FULL_CHECK 파라메타에 대해서만 학습 하도록 하겠습니다.
TRANSPORT_FULL_CHECK 파라메타는 Export 작업시에 테이블스페이스 내에 존재하는 테
이블과 인덱스의 의존성을 검사 할 것인지 하지 않을 것인지를 설정하는 파라메타 이
며 'Y' 또는 'N' 두개의 값만을 허용 하는 파라메타 입니다. TRANSPORT_FULL_CHECK
파라메타는 TRANSPORT_TABLESPACES 와 같이 사용 되어 집니다.
① 'Y' 일경우 TABLESPACE 내에 테이블만 있고 인덱스가 없다면 작업은 실패합니다.
반드시 INDEX도 같은테이블 스페이스에 존재 해야합니다.
② 'Y' 일경우 TABLESPACE 내에 인덱스만 존재하고 테이블이 없다면 작업은 실패합니다.
반드시 TABLE 또한 존재 해야합니다.
③ 'N' 일경우 TABLESPACE 내에 테이블만 있고 인덱스가 없다면 작업은 성공합니다.
④ 'N' 일경우 TABLESPACE 내에 인덱스만 있고 테이블이 없다면 작업은 실패합니다.
3) Export 필터링 관련 파라메타
파라메타 :CONTENT,EXCLUDE,EXCLUDE,QUERY 파라메타가 있으며, 이러한 파라메타들은
어떤 데이터를 Export 된 파일에 포함시킬지 결정 하는 파라메타 입니다.
① CONTENT :3개의 옵션을 가질 수 있으면 옵션 들은 다음과 같습니다.
- ALL : 테이블과 메터데이터를 포함한 모든것을 포함시키겠다는 옵션
$ expdp dangtong/edu2006 DUMPFILE=datadump.dmp CONTENT=ALL
- DATA_ONLY : 테이블 데이터만 포함 시키겠다는 옵션
$ expdp dangtong/edu2006 DUMPFILE=datadump.dmp CONTENT=DATA_ONLY
- METADATA_ONLY : 메타데이터 만을 포함하겠다는 옵션이며, 이경우 Export된
파일을 이용해 다른 데이터베이스에 Import할 경우 테이블 구조만 생성되게
됩니다.
$ expdp dangtong/edu2006 DUMPFILE=datadump.dmp CONTENT=METADATA_ONLY
② EXCLUDE and INCLUDE : 원하는 오브젝트를 선택하여 받을 수 있습니다.
그렇다면 EXCLUDE 와 INCLUDE 파라메타가 가질 수 있는 오브젝트의 종류에는 어떤
것들이 있을까요? 오라클에서 오브젝트란 유저스키마, 테이블, 인덱스, 프로시져
등을 통칭해서 오브젝트라고 합니다. 파라메타의 사용방법은 아래와 같습니다.
- SCOTT 유저와 관련된 모든것을 Export 받고 싶은데 단, BONUS 테이블을 제외하고
받고 싶다면 아래와 같이 하시면 됩니다.
$ expdp dangtong/edu2006 dumpfile=ex_dump.dmp schemas=scott
exclude=TABLES:"='BONUS'"
- SCOTT 유저와 관련된 모든 것을 Export 받고 싶은데 단, EMP 테이블의 인덱스는 받
지 않고 싶다면 다음과 같이 하시면 됩니다.
$ expdp dangtong/edu2006 dumpfile=ex_dump.dmp schemas=scott
exclude=INDEX:\"='EMP%'\"
[exclude | include]=object_name:조건 형식으로 사용하실 수 있습니다.
③ QUERY : 테이블 내에 있는 데이터 중 특정 조건에 만족하는 데이터 만을 Export 받
고자 할때 사용 하는 파라메타 입니다. 사용방법은 다음과 같습니다.
QUERY=SCHEMA.TABLE: "조건" 이며 다음과 같은 예들을 볼 수 있습니다.
- QUERY=SCOTT.EMP: "where SAL > 1200 '
SCOTT유저의 EMP 테이블을 Export 하되 SAL 컬럼의 값이 1200 보다 큰 값들만 Export
한다는 뜻입니다.
④ SAMPLE : 오라클 10g 에서 새롭게 지원하는 기능중 하나로써 테이블의 데이터를
Export 할때 퍼센트를 정하여 지정된 퍼센트 만큼의 데이터를 샘플링 해서 뽑을
때 사용 하는 옵션입니다. 사용방법은 아래와 같습니다.
$ expdp dangtong/edu2020 DIRECTORY=datapump_dir1 DUMPFILE=datapump.dmp
SAMPLE=scott.emp:20
SCOTT 유저의 EMP 테이블의 데이터 중 20%만을 Export 하게 됩니다.
- 입력 가능한 PERCENT 의 범위는 0.000001 ~ 100 까지 입니다.
4) 네트웍링크 파라메타
원격지 데이터 베이스에 있는 데이터에 접근하여 로컬 데이터베이스 머신에 Export
된 덤프 파일을 저장하고자 한다면 NETWORK_LINK 파라메타를 사용함으로써 가능합니다.
원격지 데이터는 DB_LINK를 통해 가져올 수 있으며 NETWORK_LINK 파라메타 를 사용하기
위해서는 원격지 데이터베이스의 테이블에 대한 DB_LIBK 를 만들어 놓아야 합니다.
A 데이터베이스에 B 테이터베이스의 EMP 테이블을 소유한 SCOTT_B 유저에 대한
DB LINK link_b_scott_b 이 존재 한다면 다음과 같이 NETWORK_LINK 파라메타를 사용
하여 export 할 수 있습니다.
$ expdp dangtong/edu2006 DIRECTORY=datapump_dir1 dumpfile=datapump.dmp
NETWORK_LINK=EMP@link_b_scott LOGFILE=datapump.log
5) 암호화 관련 파라메타
Export 되는 데이터중 일부 컬럼이 암호화 되어 있거나, 중요한 데이터 라면
ENCRYPTION_PASSWORD 파라메타를 이용하여 Export 시에 암호를 설정 하여 Export
된 데이터가 위 변조 되지 못하게 설정할 수 있습니다. 사용 방법은 아래와 같습니다.
$expdp dangtong/edu2006 TABLES=EMP DUMPFILE=datapump.dmp
ENCRYPTION_PASSWORD=abcdef
위와 같이 설정 하게 되면 차후 Import 시에 패스워드를 물어 보게 됩니다.
6) JOB 관련 파라메타
JOB 관련 파라메타 에는 JOB,STATUS 가 있습니다.
① JOB : JOB 파라메타를 설정하면 Data Pump 의 작업 명을 오라클에서 자동할당 하지
않고 JOB 파라메타에 주어진 이름으로 등록 하게 되게 됩니다. 작업 마스터 테이블에
작업명이 등록괴어 작업에 대한 정보들을 JOB 파라메타에 등록된 이름으로 조회할 수
있습니다.
② STATUS :STATUS 파라메타는 Data Pump Export 작업시에 작업의 갱신된 내용을 STATUS
에 설정된 크기의 시간 간격으로 진행상태를 보고 받고자 할때 사용하는 파라메타 입
니다. STATUS=30 이면 30초 간격으로 작업결과를 갱신하여 보여 주게 됩니다. 만약 이
파라메타를 설정하지 않으면 디펄트는 0입니다. 디펄트로 설정하게 되면 거의 실시간
으로 작업 정보를 보여 주게 됩니다.
③ FLASHBACK_SCN :System Change Number(SCN)는 시스템의 테이블이나 오브젝트가 변경
되었을 때 변경 되는 SCN값을 가집니다. FLASHBACK_SCN 파라메타를 이용하여 SCN 값을
지정할 경우에 파라메타에 설정된 SCN 기준 이전까지의 상태를 받게 됩니다.
$expdp dangtong/edu2006 dircetory=datapump_dir1 dumpfile=datapump.dmp
FLASHBACK_SCN=120001
④ FLASHBACK_TIME : FLASHBACK_TIME은 번호 대신에 시간 값을 가집니다. FLASH_BACK
파라메타를 사용하면 파라메타에 지정된 시간까지 의 변경사항만을 Export 하게 됩니다.
FLASHBACK_TIME 의 값은 TIMESTAMP 형식의 값을 가지며 TO_TIMESTAMP 함수를 사용하여
설정할 수 있습니다.
⑤ PARALLEL : PARALLEL 파라메타를 사용할 경우 Export 작업시에 프로세스를 필요한
숫자 만큼 만들어 수행 함으로써 작업의 속도를 향상 시킬 수 있습니다. 디펄트 값은
1로 설정되어 있으며, 주의할 점은 PARALLEL 에 지정된 갯수 만큼의 dumpfile 을 지정
해주어야 합니다. 앞서 배운 %U 를 사용 하면 지정된 PARALLEL 갯수 만큼 자동으로 파일
을 만들게 됩니다.
$expdp dangtong/edu2006 direcotry=datapump_dir1 dumpfile=datapump%U.dmp
PARALLEL=3
위와 같이 설정하게 되면 datapump01.dmp, datapump02.dmp, datapump03.dmp 3개의 덤프
파일이 생성 됩니다.
$expdp dangtong/edu2006 direcotry=datapump_dir1 dumpfile=(datapump1.dmp,
datapump2.dmp, datapump3.dmp) PARALLEL=3
위와 같이 %U를 사용하지 않고 사용자가 직접 3개의 파일명을 ',' 로 구분하여 입력해도
무방 합니다.
⑥ ATTACH : ATTACH 파라메타 를 이용하여 Interactive Mode 로 들어 갈수 있습니다.
오라클에서는 작업을 제어하고 모니터링 하기 위해 Interactive Mode 를 제공합니다.
Interactive mode 로 들어가는 방법은 2가지가 있으며 다음과 같습니다.
- Crtl + C 를 입력 함으로써 들어 갈 수 있습니다.
$expdp dangtong/edu2006 directory=datapump_dir1
table=scott.emp dumpfile=datapump.dmp
LOGFILE=datapump.log JOBNAME=MYJOB
작업로그.........
................. -> 작업에 대한 로그가 떨어질때 Crtl + C 를 누르게 되면
export> _ -> 와 같이 프롬프트 상태로 진입하게 됩니다.
로그가 멈춘다고 해서 작업이 중단 된게 아니라 여러분 께서는 이상태에서 Inter
active mode 명령을 사용하여 작업을 모티너링 하고 작업을 제어 할수 있습니다.
- $expdp username/password ATTACH=SCHEMA.JOB_NAME 형식 으로 원하는 작업의
Interactive mode 로 들어 갈수 있습니다.
$expdb dangtong/edu2006 ATTACH=scott.MYJOB
하게 되면 조금 전에 실행한 작업의 Interactive mode 로 들어 가게 됩니다.
이처럼 ATTACH 파라메타는 현재 수행 중신 작업의 Interactive mode 로 진입 하는데
사용 되어 지며 InterActive Mode 명령에는 다음과 같은 것들이 있습니다.
|
명령어
|
설명
|
|
ADD_FILE
|
덤프파일 을 추가 할 때 사용합니다.
|
|
CONTINUE_CLIENT
|
Interactive Mode 에서 Logging Mode 로 전환 할 때 사용합니다.
|
|
EXIT_CLIENT
|
Client Session 을 종료하고 Job 의 상태에서 벗어납니다.
|
|
HELP
|
Interactive mode 도움말페이지
|
|
KILL_JOB
|
작업을 삭제합니다.
|
|
PARALLEL
|
현재 수행중인 작업의 프로세스 개수를 조정할때 사용합니다.
|
|
START_JOB
|
실패한 작업이나 중단된 작업을 다시 시작시킬 때 사용합니다.
|
|
STATUS
|
현재 작업상태를 모니터링 할 때의 갱신 시간을 설정합니다.
|
|
STOP_JOB
|
작업의 실행을 중단하고 Client 를 종료합니다.
|