■ Share pool과 성능문제
xx지원 오라클 장애처리
========================
작성자 :
1. 장애처리
장애 시간 : 2006-07-21 11:34
장애 서버 : xx지원 서버2의 오라클 데이터베이스
장애 유형 : 오라클 데이터베이스 인스턴스 다운
장애 원인 : 오라클의 LMD(LOCK MONITOR DEADON) 다운으로 오라클 인스턴스 다운이 발생함
(장애분석 참조)
장애 조치 : 오라클 인스턴스 재시작함
복구 시간 : 2006-07-21 11:53
장애 예방방안 : 장애대처 예방 참조
2. 장애분석
[ alert! 로그 파일]
Fri Jul 21 11:34:26 2006 ==> 장애 시간
LMD0: terminating instance due to error 4031 ==> 장애 메시지
Instance terminated by LMD0, pid = 19848 ==> 데이터베이스 다운
[ trace 파일 분석 ]
파일명 : llmd0_19848_hiraops2.trc
*** 2006-07-21 11:34:26.346
*** SESSION ID:(3.1) 2006-07-21 11:34:26.306
error 4031 detected in background process
[ 장애원인 ]
ORA-4031 : shared pool memory 분석으로 LMD 프로세스 다운으로 발생함
Shared Pool의 정확인 영역은 나타나지 않음
<참조 : 메시지 >
04031, 00000, "unable to allocate %s bytes of shared memory (\"%s\",\"%s\",\"%s\",\"%s\")"
*Cause: More shared memory is needed than was allocated in the shared pool.
*Action: If the shared pool is out of memory, either use the dbms_shared_pool package to pin
large packages,reduce your use of shared memory, or increase the amount of available shared
memory by increasing the value of the INIT.ORA parameters "shared_pool_reserved_size" and
"shared_pool_size".
If the large pool is out of memory, increase the INIT.ORA parameter "large_pool_size".
< Ora-4031 란 ? >
이 에러는 사용자가 특정 Object를 사용하고자 할 때 해당 Object를 위해 Shared_Pool에 공간을 할당하려 할 때 충분한
공간을 얻지 못하는 경우이다
Shared_Pool 영역에 차지하는 크기가 큰 PL/SQL 사용시 오라클은 공간 확보를 위해 현재 사용되지 않는 Object를 Flush시킨다.
기존 V7.2. 이하에서는 특정 프로시저를 Shared_Pool에 올리기 위해 연속된 공간을 필요로 하였으나, 이후 버전에
서는 꼭 연속되지 않아도 사용이 가능하여 ORA-4031 에러가 발생하는 경우가 많이줄어들었다.
이의 해결을 위해서는 Shared_Pool을 늘려주도록 한다 .
이 에러를 유발시키는 문제인 메모리의 단편화 (fragmentation)를 줄이기 위해서, 또는 일반적인 경우 자주 사용하는 Object가
메모리에서 밀려 내려가는 경우를 없애기 위해서 Object를 미리 Shared_Pool에 Keep 한다.
3.장애 예방 방안
[ 목적 ]
- Shared Pool Memory 부족(ORA-4031) 장애발생 예방
[ 예방 방법 ]
- shared pool size , shared pool reserved size , large pool size를 증가 한다.
[ Shared Pool Memory 할당 값]
#shared_pool_size = 471859200 # 450MB
#shared_pool_reserved_size = 47185920 # shared pool * 10%
#shared_pool_size = 512000000 # 500MB 2005.07.21
#shared_pool_reserved_size = 51200000 # shared pool * 10% 2005.07.21
shared_pool_size = 629145600 # 600MB 2005.08.08
shared_pool_reserved_size = 62914560 # shared pool * 10% 2005.08.08
java_pool_size = 2097152
large_pool_size = 10M # 2004/10/30
[ 메모리 사용률 ]
전체 메모리 : 19.9G
사용률 : Sys Mem : 4.68GB User Mem: 2.71GB Buf Cache: 1.99GB Free Mem: 10.5GB
[ shared pool free memory 확인 QUERY 및 flush 명령어]
SQL> select v$sgastat.pool, to_number(v$parameter.value) value, v$sgastat.bytes,
(v$sgastat.bytes/v$parameter.value)*100 "Percent Free"
from v$sgastat , v$parameter
where v$sgastat.name = 'free memory'
and v$parameter.name = 'shared_pool_size';
POOL VALUE BYTES Percent Free
---------------------------------------------------------------
shared pool 629145600 140415416 22.3184293111165 <-- free space 확인
large pool 629145600 299984 0.0476811726888021
java pool 629145600 2097152 0.333333333333333
SQL> alter system flush shared_pool; <-- 단편화된 조각화를 flush 해주는 방법(메모리 조각모음) (업무외시간에 수행)
[ Library Cache Fragmentation 확인 Query]
select
decode(sign(ksmchsiz - 812), -1, (ksmchsiz - 16) / 4,
decode(sign(ksmchsiz - 4012), -1, trunc((ksmchsiz + 11924) / 64),
decode(sign(ksmchsiz - 65548), -1, trunc(1/log(ksmchsiz - 11, 2)) + 238, 254 ))) bucket,
sum(ksmchsiz) free_space, count(*) free_chunks, trunc(avg(ksmchsiz)) average_size,
max(ksmchsiz) biggest
from
sys.xm$ksmsp
where
inst_id = userenv('Instance') and ksmchcls = 'free'
group by
decode(sign(ksmchsiz - 812), -1, (ksmchsiz - 16) / 4,
decode(sign(ksmchsiz - 4012),-1, trunc((ksmchsiz + 11924) / 64),
decode(sign(ksmchsiz - 65548),-1, trunc(1/log(ksmchsiz - 11, 2)) + 238, 254)))
BUCKET FREE_SPACE FREE_CHUNKS AVERAGE_SIZE BIGGEST
---------- ---------- ----------- ------------ -------------------------------------------------------
6 92000 2300 40 40
8 1392 29 48 48
10 1456 26 56 56
……
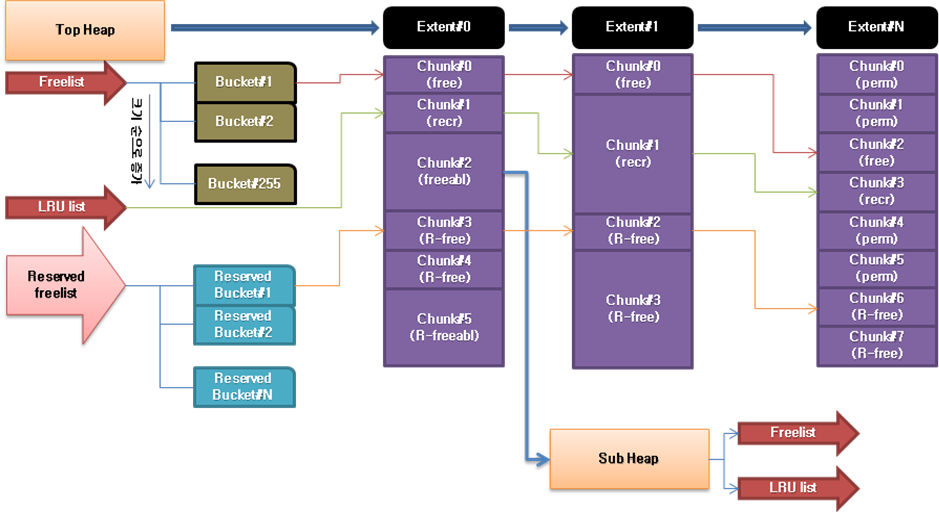
위의 결과처럼 shared pool 영역에 작은 chunk 들의 다수 존재하는 경우에는 free list 검색시 shared pool latch를 장시간 holding하게 되며,
이는 shared pool latch free 대기 현상이 발생할 가능성을 높여주게 된다. 일반적으로 hard parsing에 의해 이러한 현상들이 발생하게 됨.
[ Shared Pool size 적절성 확인 Query ]
column kghlurcr heading "RECURRENT|CHUNKS"
column kghlutrn heading "TRANSIENT|CHUNKS"
column kghlufsh heading "FLUSHED|CHUNKS"
column kghluops heading "PINS AND|RELEASES"
column kghlunfu heading "ORA-4031|ERRORS"
column kghlunfs heading "LAST ERROR|SIZE"
select
kghlurcr "RECURRENT|CHUNKS" ,
kghlurcr *3,
kghlutrn "TRANSIENT|CHUNKS" ,
kghlufsh "FLUSHED|CHUNKS" ,
kghluops "PINS AND|RELEASES" ,
(kghlufsh/ kghluops) *100,
kghlunfu "ORA-4031|ERRORS" ,
kghlunfs "LAST ERROR|SIZE"
from
sys.x_$kghlu
where
inst_id = userenv('Instance');
RECURRENT TRANSIENT FLUSHED PINS AND ORA-4031 LAST ERROR
CHUNKS CHUNKS CHUNKS RELEASES ERRORS SIZE
---------- ---------- --------------- ---------- -----------------------------------------------------------------
587 1687 8946 28416904 0 0
-- 일반적으로 Transient list가 Recurrent List 의 3배 이상이면 shared pool 이 oversize 된 것이며, chunk flush 수치가
-- pins and released 수치의 5% 이상이면 shared pool 이 작게 설정된 것이라고 볼 수 있다.
shared pool 의 free 공간 확인
select to_number(v$parameter.value) value, v$sgastat.bytes,
(v$sgastat.bytes/v$parameter.value)*100 "Percent Free"
from v$sgastat, v$parameter
where v$sgastat.name = 'free memory'
and v$parameter.name = 'shared_pool_size';
■ Shared Pool 관련 wait
|
Latch |
Lock |
|
latch free ( library cache )
latch free ( library cache load lock) |
library cache lock, library cache pin
library cache load lock |
|
latch free ( row cache objects ) |
row cache lock |
|
latch free ( shared pool ) |
|
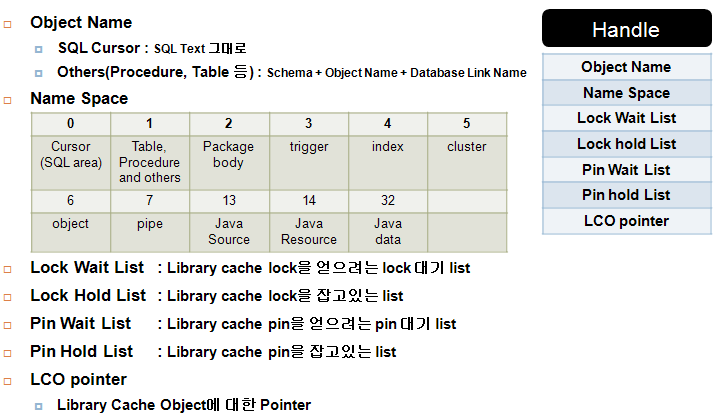
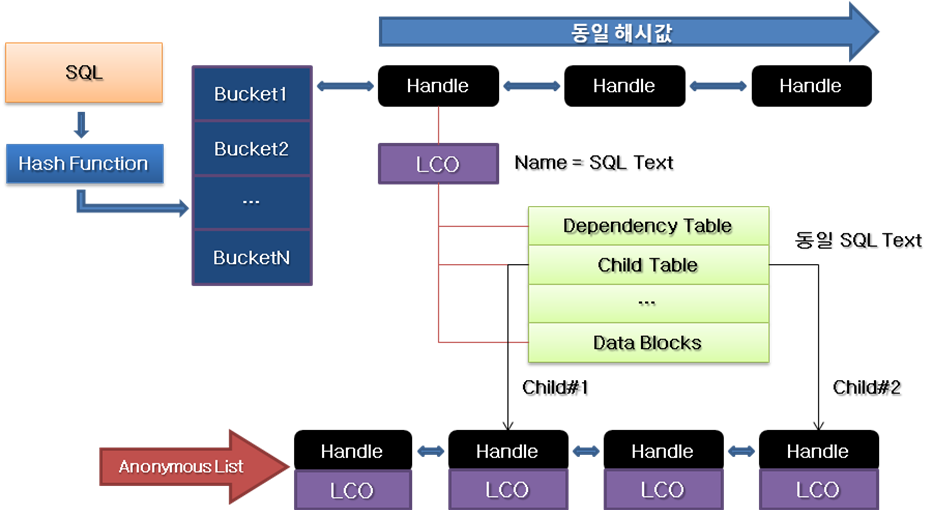
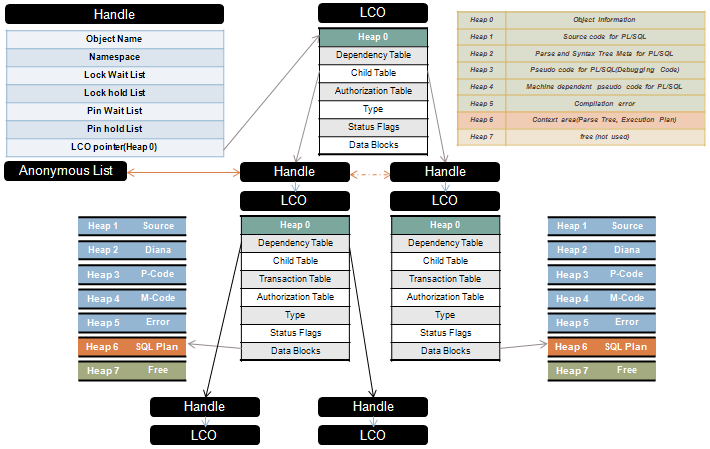
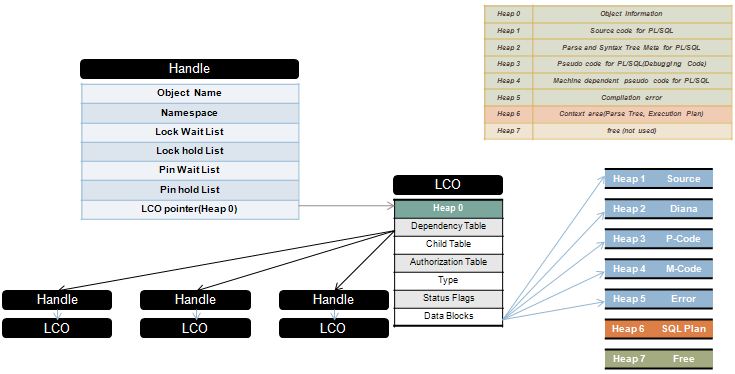
☞ 4-6 library cache 알고리즘
라이브러리 캐쉬는 lru 알고리즘에의해 관리가 되며
문장이 이미 캐쉬에 저장되어 있는가를 찾기 위하여, 오라클 서버는 다음을 수행합니다:
1. ASCII 텍스트의 수치로 문장을 줄임
2. 이 수치에 해시 함수 사용
☞ 4-7 shared pool latch
SQL 이 공유되지 못하고 파싱해달라고 하는 SQL 이 많아지면 공간을 할당 받아야하는데 이때
공간을 할당 받을때 메모리에 락(latch) 를 건다. latch 를 사용하는 이유는 파싱해달라고 요청하는
sql 에 대하여 순서를 정하는 것인데 먼저 요청한 sql 에 대하여 작업을 원할히 수행하기 위해 메모리에 락을 거는것이다.즉 동시 엑세스를 제어하기 위해 latch 를 사용한다.
그런데 조각화(단편화) 가 심해지면 free list 가 그만큼 길어지므로 공간 할당받을때 시간이 많이 소유될것이고 이로 인해 발생하는 wait event ( latch free(library cache) ) 가 다량으로 발생할것이다.
이를 해결하기 위해서는
1. 바인드변수 사용
2. cursor_sharing 사용
3. shared pool size 늘린다.
4. large pool 을 구성한다.
☞ 4-8 shared pool 에 공유되지 않은 SQL 에 대한 정보 보기
select *
from v$sqlarea
where executions < 5
order by upper(sql_Text)
select sql_Text, parse_calls, executions
from v$sqlarea
order by parse_calls;
☞ 4-12 ~ 실습
v$sqlarea
(라이브러리 캐쉬: 문장저장)
동일한 문장
1. 대소문자
2. 스키마(schema)
3. 공백
4. 주석
5. bind 변수의 type(아래설명)
*****************************************
scott1
실행
SQL> select empno,ename from emp where deptno=10;
EMPNO ENAME
---------- ----------
7782 CLARK
7839 KING
7934 MILLER
internal에서 실행
SQL> ed
Wrote file afiedt.buf
select sql_text,SHARABLE_MEM,EXECUTIONS
from v$sqlarea
where sql_text like 'select empno,ename from emp where%';
SQL_TEXT SHARABLE_MEM EXECUTIONS
-------------------------------------------------------------- ----------
select empno,ename from emp where deptno=10 5234 1
사용했던 문장이 나옴
scott1
변수 선언
SQL> variable v1 varchar2(10)
SQL> declare
2 begin
3 :v1 := '10';
4 end;
5 /
PL/SQL procedure successfully completed.
SQL> select empno, ename from emp where deptno=:v1;
EMPNO ENAME
---------- ----------
7782 CLARK
7839 KING
7934 MILLER
internal
SQL> /
SQL_TEXT SHARABLE_MEM EXECUTIONS
-------------------------------------------------- ------------ ----------
select empno,ename from emp where deptno=10 5234 1
select empno,ename from emp where deptno=:v1 5067 1
scott1
변수값을 바꾸어줌
SQL> declare
2 begin
3 :v1 := '20';
4 end;
5 /
PL/SQL procedure successfully completed.
SQL> select empno,ename from emp where deptno=:v1;
EMPNO ENAME
---------- ----------
7369 SMITH
7566 JONES
7788 SCOTT
7876 ADAMS
7902 FORD
internal
scott의 결과는 달라도 새로 파싱을 안함
SQL> /
SQL_TEXT SHARABLE_MEM EXECUTIONS
-------------------------------------------------- ------------ ----------
select empno,ename from emp where deptno=10 5234 1
select empno,ename from emp where deptno=:v1 5067 2
문제) select empno,ename from emp where deptno=30 을 하고 출력해보아라 !!!
scott2
변수형을 넘버로 선언
SQL> variable v1 number
SQL> declare
2 begin
3 :v1 :=20;
4 end;
PL/SQL procedure successfully completed.
SQL> select empno,ename from emp where deptno=:v1;
EMPNO ENAME
---------- ----------
7369 SMITH
7566 JONES
7788 SCOTT
7876 ADAMS
7902 FORD
internal
scott2에 실행한 문장후 크기가 늘어남 (파싱계획변경)
SQL> /
SQL_TEXT SHARABLE_MEM EXECUTIONS
-------------------------------------------------- ------------ ----------
select empno,ename from emp where deptno=10 5234 1
select empno,ename from emp where deptno=:v1 8939 3
********** bind type에 따라 파싱이 다르다 ****************
☞ 4-13 실습
1) v$librarycache 를 통해 hit율(gethitratio)를 분석
- gets : 사용자가 실행한 SQL문이 구문 분석되어 라이브러리 캐시 영역에 로드되려 했던 수.
- gethits : 그 중 로드되었던 수
- hit율(gethitratio)이 90% 이상일때 좋은 성능 기대
select namespace , gets , gethits,gethitratio
from v$librarycache
where namespace = 'SQL AREA' ;
NAMESPACE GETS GETHITS GETHITRATIO
--------------- ---------- ---------- -----------
SQL AREA 141767 141498 .99810252
<= GETHITRATIO 컬럼 값이 90%이상이면 라이브러리 캐시 영역이 개발자들의 SQL 파싱정보를
저장하기에 충분한 메모리 공간을 확보하고 있슴을 의미하며, 만약 90% 이하라면 성능이 저하
될 수 있다는 것을 의미.
물론 90% 이하라도 사용자들이 성능에 만족한다면 튜닝 대상이 안될 수도 있으며 반드시 튜닝
을 해야 할 필요는 없다.
▷ 유의사항
- 히트율 분석은 기업에서 가장 일을 바쁘게 진행하고 있는 시간대의 분석 결과를 기준으로
하여야 한다.
▷ 초치사항
- HIT율이 90% 이하일 경우 SHARED_POOL_SIZE 파라메터 값을 높게 설정.
ex) initSID.ora
......
SHARED_POOL_SIZE = 32000000 <= 이전 보다 큰 값으로 변경
.....
2) v$library 자료사전을 통해 RELOAD 비율 분석.
- RELOADS 비율 = ( Reloads / Pins ) * 100
- Library Cache Area 의 크기가 너무 작아서 사용자의 SQL 구문분석 정보가 로드되지 못하고
가장 오래된 SQL문 정보를 삭제 후 사용자의 SQL 문장이 다시 실행될 때 Reloads 증가.
- 구분분석된 SQL문에서 사용된 객체가 다른 사용자에 의해 삭제된 상태에서 다시 SQL문이
재실행될 때에는 RELOADS 컬럼값이 증가.
- PINS : 구문분석되어 Library Cache Area 에 저장될 수 있었던 SQL 정보.
- PINS 컬럼에 대한 Realods 컬럼의 백분율이 1% 미만일 때 좋은 성능 기대.
select sum(pins),sum(reloads),sum(reloads)/sum(pins)
from v$librarycache
where namespace = 'SQL AREA' ;
SUM(PINS) SUM(RELOADS) SUM(RELOADS)/SUM(PINS)
---------- ------------ ----------------------
320823 10 .00003117
<= PINS에 대한 RELOADS의 비율이 1% 미만일 때 라이브러리 캐시 영역의 크기가 AQL 파싱정보
를 저장하기에 충분하다는 것을 의미. 1% 이상이라면 성능이 저하될 수도 있다는 것을 의미.
3) v$librarycache 를 통해 SQL문에서 사용된 객체가 다른 사용자들에 의해 얼마나 자주
삭제,변경되었는 지를 분석하는 방법.
주로 ANALYZE ,ALTER , DROP명령어에 의해 테이블 구조가 변경되는 경우에 발생.
select namespace, invalidations
from v$librarycache
where namespace = 'SQL AREA' ;
NAMESPACE INVALIDATIONS
--------------- -------------
SQL AREA 0
<= INVALIDATIONS 컬럼의 값이 높게 출력 되거나 계속적으로 증가 값을 보인다면 공유 풀 영역
에 작아서 성능이 저하되도 있음을 의미. 즉, 불필요한 재파싱. 재로딩 작업이 발생할 가능성이 높
아지는 것이다.
☞ 4-14 ~ 실습
SQL> alter system set cursor_sharing=force scope=both;
시스템이 변경되었습니다.
SQL>
SQL>
SQL> select sql_text,SHARABLE_MEM,EXECUTIONS
from v$sqlarea
where sql_text like 'select empno,ename from emp where%';
SQL_TEXT
--------------------------------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=10
6693 1
select empno,ename from emp where deptno=30
6725 1
select empno,ename from emp where deptno=:v1
6546 1
SQL> alter system flush shared_pool;
시스템이 변경되었습니다.
SQL> select sql_text,SHARABLE_MEM,EXECUTIONS
2 from v$sqlarea
3 where sql_text like 'select empno,ename from emp where%';
SQL_TEXT
--------------------------------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=30
1461 0
scott 창에서
SQL> select empno,ename from emp where deptno=10;
SQL> /
SQL_TEXT
--------------------------------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=30
1461 0
select empno,ename from emp where deptno=:"SYS_B_0"
11873 1
scott 창에서
SQL> select empno,ename from emp where deptno=20;
SQL> /
SQL_TEXT
--------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=30
1461 0
select empno,ename from emp where deptno=:"SYS_B_0"
11873 1
문제) 다시 exact 로 바꾸고 실습하여라 !!!
SQL> alter system set cursor_Sharing=exact;
시스템이 변경되었습니다.
SQL> select sql_text,SHARABLE_MEM,EXECUTIONS
2 from v$sqlarea
3 where sql_text like 'select empno,ename from emp wh
SQL_TEXT
------------------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=10
6705 1
select empno,ename from emp where deptno=30
1461 0
select empno,ename from emp where deptno=:"SYS_B_0"
11873 2
SQL>
SQL> /
SQL_TEXT
------------------------------------------------------------------
SHARABLE_MEM EXECUTIONS
------------ ----------
select empno,ename from emp where deptno=10
6705 1
select empno,ename from emp where deptno=20
6725 1
select empno,ename from emp where deptno=30
1461 0
select empno,ename from emp where deptno=:"SYS_B_0"
11873 2
☞ 4-17 실습
**************** 테이블과 뷰만들어서 파싱확인하기 ****************
scott1
테이블 생성 및 뷰 생성
SQL> create table abc
2 (a1 number, a2 number);
Table created.
SQL> insert into abc values(111,111);
1 row created.
SQL> commit;
Commit complete.
SQL> create view abcvw
2 as
3 select a1+a2 summun
4 from abc;
View created.
scott2
테이블 뷰 실행
SQL> select * from abcvw;
SUMMUN
----------
222
scott1
테이블 드랍
SQL> drop table abc;
Table dropped.
internal
SQL> ed
Wrote file afiedt.buf
1 select sql_text,SHARABLE_MEM,EXECUTIONS, INVALIDATIONS
2 from v$sqlarea
3* where sql_text like 'select * from abcvw%'
SQL> /
SQL_TEXT SHARABLE_MEM EXECUTIONS INVALIDATIONS
----------------------------------------------- -----------------------
select * from abcvw 866 1 1
scott2
테이블 뷰 쿼리
SQL> select * from abcvw;
select * from abcvw
*
ERROR at line 1:
ORA-04063: view "SCOTT.ABCVW" has errors
scott1
다시 테이블 생성
SQL> create table abc
2 (a1 number, a2 number);
Table created.
SQL> insert into abc values(111,111);
1 row created.
SQL> commit;
Commit complete.
scott2
뷰 실행(다시 실행이 됨)
SQL> select * from abcvw;
SUMMUN
----------
222
internal
SQL> /
SQL_TEXT SHARABLE_MEM EXECUTIONS INVALIDATIONS
----------------------------------- ------------ ---------- -------------
select * from abcvw 5718 2 1
☞ 4-20 실습
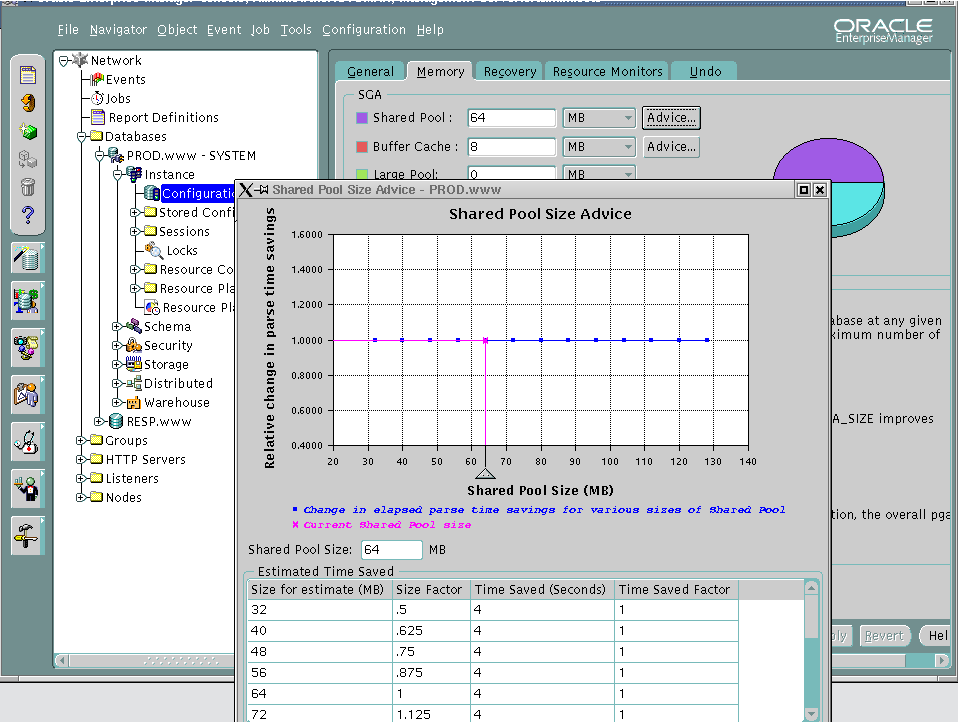
select shared_pool_size_for_estimate as pool_size, estd_lc_size, estd_lc_time_saved
from v$shared_pool_advice;
SHARED_POOL_SIZE_FOR_ESTIMATE NUMBER : Shared pool size for the estimate (in megabytes)
ESTD_LC_SIZE NUMBER: Estimated memory in use by the library cache (in megabytes)
ESTD_LC_TIME_SAVED NUMBER
Estimated elapsed parse time saved (in seconds), owing to library cache memory objects being found in a shared pool of the specified size. This is the time that would have been spent in reloading the required objects in the shared pool had they been aged out due to insufficient amount of available free memory
☞ 4-25 실습
■ V$SQL_PLAN
- Oracle9i 부터 새롭게 추가된 기능
- SQL문이 실행되면서 작성된 실행계획이 Shared Pool Area에 저장됨.
SQL>connect system/manager
SQL>grant dba to scott ;
SQL>connect scott/tiger
SQL>select * from dept ;
SQL>select sql_text , hash_value , address
from v$sqlarea ;
SQL_TEXT HASH_VALUE ADDRESS
------------------- ---------- ----------
select * from dept 3015709834 04165C60
SQL>select id, lpad(' ',depth)||operation operation , options , object_name,optimizer,cost
from v$sql_plan
where hash_value = &1 and address='&2'
start with id=0
connect by ( prior id = parent_id and prior hash_value = hash_value
and prior_child_number = child_number)
order siblings by id, position;
&1 : 3015709834 (HASH_VALUE )
&2 : 04165C60 (ADDRESS)
ID OPERATION OPTIONS OBJECT_NAME OPT COST
---- ---------------------- ----------- --------------- ------ ------
0 SELECT STATEMENT CHO
1 TABLE ACCESS FULL DEPT
<= 또는, set autotrace on 사용으로 SQL문 실행시 파싱단계에서 옵티마이저가 작성한 실행계획
을 참조할 수 있다.
☞ 4- 26 실습
SQL> show parameter shared_pool_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 50331648
SQL> select sum(sharable_mem)
from v$db_object_cache;
SUM(SHARABLE_MEM)
-----------------
331406
☞ 4-30 ~ 4-32 실습
show parameter shared
select p.value/r.value * 100 "reserved radit"
from v$parameter p, v$parameter r
where p.name = 'shared_pool_reserved_size'
and r.name = 'shared_pool_size';
select * from v$db_object_cache
where sharable_mem > 10000
and ( type='PACKAGE' or type='PACKAGE BODY' or
type='FUNCTION' or type='PROCEDURE' )
and kept='NO';
@d:\oracle\ora92\rdbms\admin\dbmspool.sql
desc dbms_shared_pool
execute dbms_shared_pool.keep('dbms_sql');
select * from v$db_object_cache
where sharable_mem > 10000
and ( type='PACKAGE' or type='PACKAGE BODY' or
type='FUNCTION' or type='PROCEDURE' )
☞ 4-30 ~ 4-32 실습
SQL> declare x number;
begin x :=5;
end;
/
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL>
SQL> declare /* keep_me */ x number;
begin x := 5;
end;
/
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL> select address, hash_value
from v$sqlarea
where command_type=47
and sql_Text like '%keep_me%';
ADDRESS HASH_VALUE
-------- ----------
669841E4 4215866029
execute dbms_shared_pool.keep('669841E4,4215866029','c');
select distinct name, sharable_mem, loads
from v$db_object_cache
where name like '%keep_me%';
DBMS_SHARED_POOL을 이용한 KEEP
Shared Poll에 크기가 큰 프로그램을 KEEP하기 위해서는 아래에 있는 것처럼 DBMS_SHARED_POOL Package를 이용 할 수 있습니다.
SQL> @C:\oracle\ora92\rdbms\admin\dbmspool.sql
패키지가 생성되었습니다.
권한이 부여되었습니다.
뷰가 생성되었습니다.
패키지 본문이 생성되었습니다.
SQL> @C:\oracle\ora92\rdbms\admin\prvtpool.plb
뷰가 생성되었습니다.
패키지 본문이 생성되었습니다.
SQL> grant execute on dbms_shared_pool to scott;
권한이 부여되었습니다.
Object를 KEEP하는 방법은 다음과 같습니다.
Procedure,Function,Package : exec dbms_shared_pool.keep(‘pname’,’p’)
Trigger : exec dbms_shared_pool.keep(‘tr_emp’,’r’)
Sequence : exec dbms_shared_pool.keep(‘seq_empno,’q’)
SQL문은 아래와 같은 방법으로 KEEP 합니다.
예를들어 select empno, ename, sal from emp where deptno = ‘20’ 라는 SQL문장을 Library Cache안의 Shared Cursor 부분에 KEEP하기 위해서는 아래처럼 하면 됩니다…
SQL> conn scott/tiger
연결되었습니다.
SQL> select empno, ename, sal from emp where deptno = 20;
EMPNO ENAME SAL
---------- ---------- ----------
7369 SMITH 800
7566 JONES 2975
7788 SCOTT 3000
7876 ADAMS 1100
7902 FORD 3000
SQL> conn / as sysdba
연결되었습니다.
SQL> select address, hash_value from v$sqlarea
2 where sql_text = 'select empno, ename, sal from emp where deptno = 20';
ADDRESS HASH_VALUE
-------- ----------
7856AC4C 1137127237 <- 원하는 SQL문장에 대한 주소와 해시 값
아래 명령으로 KEEP 합니다.
SQL> exec dbms_shared_pool.keep('7856AC4C, 1137127237','c');
PL/SQL 처리가 정상적으로 완료되었습니다.
Object의 KEEP 상태는 다음으로 체크 가능 합니다.
SQL> select distinct name, sharable_mem, loads
from v$db_object_cache
where name like '%emp%'
and kept = 'YES';
NAME SHARABLE_MEM LOADS
------------ ----------------------------------------------
select empno, ename, sal from emp where deptno = 20 1469 1
또는 exec dbms_shared_pool.sizes(0)로 확인 가능 합니다. 이 sizes라는 procedure는 제한된 사이크 이상의 keep된 Object를 나타내 줍니다.
SQL> set serveroutput on size 2000
SQL> exec dbms_shared_pool.sizes(0) -> buffer overflow가 나더라도 pin시킬(KEEP할) SQL문장을 찾을 수는 있습니다.
각 Object를 Shared Pool에 유지하던 것을 해제 할 때는 아래의 unkeep 프로시저를 이용 합니다.
SQL> exec dbms_shared_pool.unkeep('7856AC4C, 1137127237','c');
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL> select distinct name, sharable_mem, loads
2 from v$db_object_cache
3 where name like '%emp%'
4 and kept = 'YES';
결과가 없겠죠…
☞ 자주 사용되는 PL/SQL 블록을 캐싱한다.
- PL/SQL(프로시저,함수,패키지,트리거) 블록들은 너무 커서 실행시 마다 라이브러리 캐시영역
에 로드되었다가 다시 제거되는 현상이 반복 --> 라이브러리 캐시영역의 단편화 현상 발생
- PL/SQL 블록 , SEQUENCE 등을 라이브러리 영역에 캐싱할 수 있도록 DBMS_SHARED_POOL
패키지 제공.
SQL> select name,type,kept
from v$db_object_cache
where type in ('PACKAGE','PROCEDURE','TRIGGER','PACKAGEBODY');
NAME TYPE KEPT
------------------- --------- ------
<= 캐싱된 PL/SQL 블록 정보가 없다
SQL>connect scott/tiger
SQL>create or replace procedure check_swan <= 샘플 Procedure 생성
( v_emp_no in emp.empno%type )
is
begin
delete from emp where empno = v_emp_no ;
end check_swan ;
/
SQL>execute DBMS_SHARED_POOL.KEEP('CHECK_SWAN')
<= 해당 프로시저를 공유 풀 영역에 상주.
SQL> select name,type,kept
from v$db_object_cache
where type in ('PACKAGE','PROCEDURE','TRIGGER','PACKAGEBODY');
NAME TYPE KEPT
------------------- ------------- ------
CHECK_SWAN PROCEDURE Y <= 해당 프로지셔 캐싱
SQL>execute DBMS_SHARED_POOL.UNKEEP('CHECK_SWAN')
SQL> select name,type,kept
from v$db_object_cache
where type in ('PACKAGE','PROCEDURE','TRIGGER','PACKAGEBODY');
NAME TYPE KEPT
------------------- ------------- ------
CHECK_SWAN PROCEDURE N <= 해당 프로지셔 캐싱 해제
☞ 4-41 실습
아래의 쿼리를 이용하여 가장 빈번하게 사용되는 오브젝트를 찾을 수 있다.
select cache#, type, parameter, gets, getmisses, modifications mod
from v$rowcache
where gets > 0
order by gets;
CACHE# TYPE PARAMETER GETS GETMISSES MOD
------ ----------- ------------------ ---------- ---------- ------
7 SUBORDINATE dc_user_grants 1615488 75 0
2 PARENT dc_sequences 2119254 189754 100
15 PARENT dc_database_links 2268663 2 0
10 PARENT dc_usernames 7702353 46 0
8 PARENT dc_objects 11280602 12719 400
7 PARENT dc_users 81128420 78 0
16 PARENT dc_histogram_defs 182648396 51537 0
11 PARENT dc_object_ids 250841842 3939 75
row cache 튜닝은 매우 제한적이다. 최상의 솔루션은 V$ROWCACHE 의 결과를 기반으로 딕셔너리 접근을 줄이는 것이다. 예를 들어, 만일 시퀀스가 문제라면, 시퀀스를 캐슁하는 것을 고려할 수 있다. 여러 개의 테이블 조인을 포함하는 뷰 및 중첩된 뷰는 래치 경합을 증가시키게 된다. 일반적인 대안은 단순히 SHARED_POOL_SIZE를 증가하는 것이다.
기타>
LIBRARY CACHE LOCK WAIT EVENT가 나타날 때의 해결방법
====================================================
PURPOSE
-------
v$session_wait event 에 'library cache lock'이 발생하면서 session이
waiting 되는 경우가 있다. 오랫동안 이 현상이 지속될 경우 어떤 session이
이 library cache lock 을 갖고 있는지 확인해 볼 수 있다.
Explanation
-----------
v$session_wait view에 'library cache lock'이 나타날 수 있는 경우가
어떠한 것이 있는 지 알아보자.
예를 들어 다음과 같은 alter table 문장의 경우를 살펴보자.
ALTER TABLE x MODIFY (col1 CHAR(200));
X 라는 Table의 row가 많다면 위의 문장으로 인해서 모든 row의 값이
200 bytes로 update되어야 하므로 굉장히 오랜 시간이 걸리게 된다.
이 작업 중에는 Table에 dml이 실행되어도 waiting되는 데, 이런 때에
'library cache lock' 이라고 나오게 된다.
또 package가 compile 되는 중에는 다른 user가 같은 package 내의
procedure나 function 등을 실행시켜도 waiting이 걸리면서 library cache
lock 이나 library cache pin event가 나타난다.
이 library cache lock 을 잡고 있는 session을 확인해 보자.
1. waiting session의 session address 확인
library cache lock으로 waiting하고 있는 session의 sid를 찾아서
그 session address - v$session의 saddr column 을 확인한다.
2. 다음과 같은 sql로 해당 library cache lock을 잡고 있는 session을
확인할 수 있다.
아래의 SQL 중에서 'saddr_from_v$session' 부분에 위의 1번에서 찾은
Waiting session의 saddr 값을 입력한다.
단, 아래의 sql은 반드시 sys 또는 internal user에서 실행해야 한다.
SELECT SID,SERIAL#,USERNAME,TERMINAL,PROGRAM
FROM V$SESSION
WHERE SADDR in
(SELECT KGLLKSES FROM X$KGLLK LOCK_A
WHERE KGLLKREQ = 0
AND EXISTS (SELECT LOCK_B.KGLLKHDL FROM X$KGLLK LOCK_B
WHERE KGLLKSES = 'saddr_from_v$session' /* BLOCKED SESSION */
AND LOCK_A.KGLLKHDL = LOCK_B.KGLLKHDL
AND KGLLKREQ > 0)
);
3. 2번에서 확인한 blocking session에 의해 waiting하고 있는 session들도
확인할 수 있다. 2번에서 찾은 session의 saddr 값을 다음 sql에 대입하여
찾을 수 있다.
SELECT SID,USERNAME,TERMINAL,PROGRAM
FROM V$SESSION
WHERE SADDR in
(SELECT KGLLKSES FROM X$KGLLK LOCK_A
WHERE KGLLKREQ > 0
AND EXISTS (SELECT LOCK_B.KGLLKHDL FROM X$KGLLK LOCK_B
WHERE KGLLKSES = 'saddr_from_v$session' /* BLOCKING SESSION */
AND LOCK_A.KGLLKHDL = LOCK_B.KGLLKHDL
AND KGLLKREQ = 0)
);
4. blocking session이 왜 오래 걸리는 것인지, v$session_wait 를 다시
확인하거나 실행하고 있는 sql 문장이나 object 등을 v$sql view 등을 확인
해 보아야 한다. 작업이라면 종료될 때까지 기다릴 수 있겠지만, 비정상적인
경우 또는 waiting session을 위해서는 다음과 같이 kill 할 수도 있다.
alter system kill session 'SID, SERIAL#';


 \
\