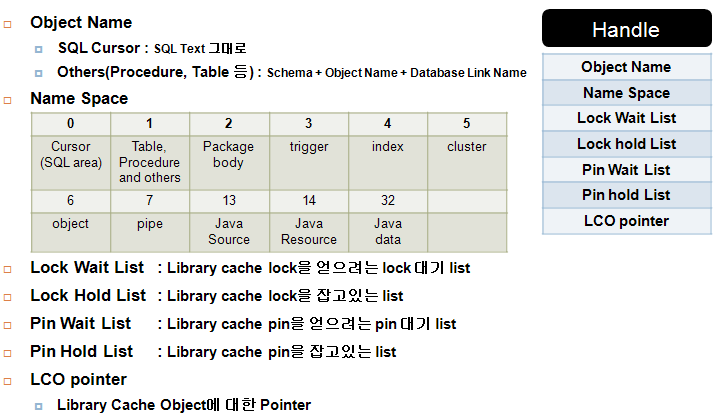
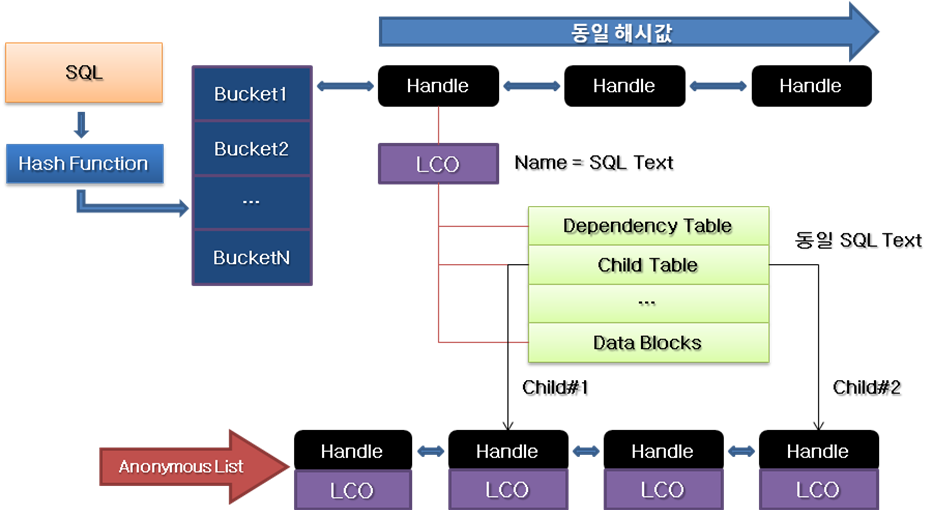
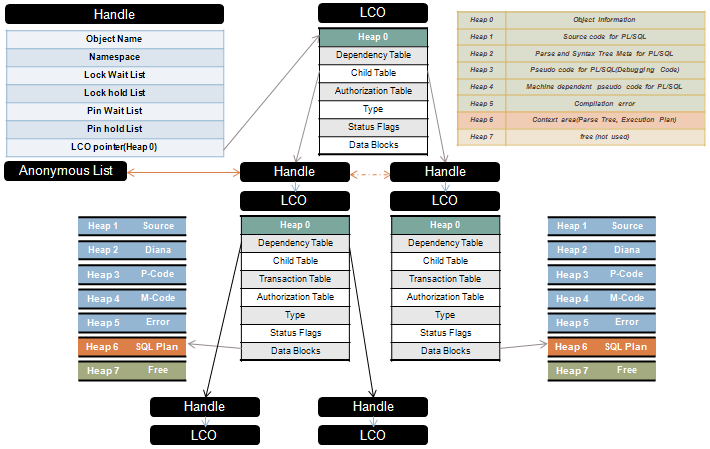
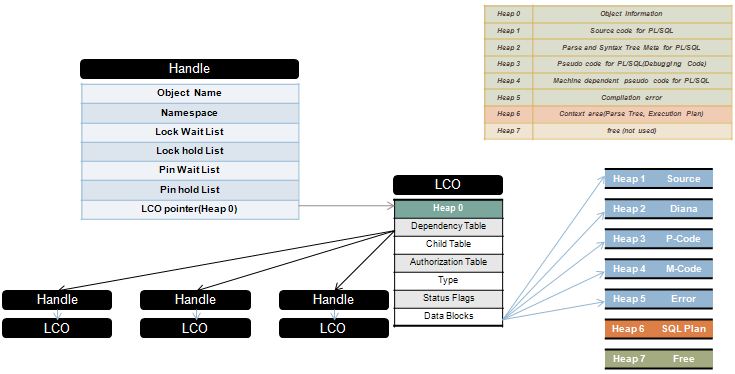
###### What are the major tuning areas in database performance tuning #######
- Memory - shared pool, large pool, buffer cache, redo log buffer, and sort area size.
- I/O - distributing I/O, striping, multiple DBWn processes, and DBWn I/O slaves.
- CPU - CPU utilization.
- Space management - extent allocation and Oracle block efficiency.
- Redo log and checkpoint - redo log file configuration, redo entries, and checkpoint.
- Rollback segment - sizing rollback segments.
- Network
###### 조정해야할 메모리 영역
전체 SGA 영역 : 2.4G
shared_pool_size = ???
large_pool_size = ???
java_pool_size = ???
db_cache_size = ???
SHARED_POOL_RESERVED_SIZE=???
##################################################
### PGA 성능(할당량) 조정
##################################################
PGA target advice => v$pga_target_advice를 이용하여 적당 할당량을 조사한다.
-- PGA 어드바이스
select round(pga_target_for_estimate/1024/1024) as target_size_MB,
bytes_processed,estd_extra_bytes_rw as est_rw_extra_bytes,
estd_pga_cache_hit_percentage as est_hit_pct,
estd_overalloc_count as est_overalloc
from v$pga_target_advice;
=>위의 쿼리를 실행해서 최적의 PGA할당량을 찾아낸다
PGA Memory Advisory DB/Inst: KMSMESV1/KMSMESV1 End Snap: 886
-> When using Auto Memory Mgmt, minimally choose a pga_aggregate_target value
where Estd PGA Overalloc Count is 0
Estd Extra Estd PGA Estd PGA
PGA Target Size W/A MB W/A MB Read/ Cache Overalloc
Est (MB) Factr Processed Written to Disk Hit % Count
---------- ------- ---------------- ---------------- -------- ----------
94 0.1 326,688.8 11,869.3 96.0 2,140
188 0.3 326,688.8 11,869.3 96.0 2,139
375 0.5 326,688.8 2,393.2 99.0 646
563 0.8 326,688.8 110.8 100.0 0
750 1.0 326,688.8 110.8 100.0 0
900 1.2 326,688.8 110.8 100.0 0
1,050 1.4 326,688.8 110.8 100.0 0
1,200 1.6 326,688.8 110.8 100.0 0
1,350 1.8 326,688.8 110.8 100.0 0
1,500 2.0 326,688.8 110.8 100.0 0
2,250 3.0 326,688.8 110.8 100.0 0
3,000 4.0 326,688.8 110.8 100.0 0
4,500 6.0 326,688.8 110.8 100.0 0
6,000 8.0 326,688.8 110.8 100.0 0
-------------------------------------------------------------
::::::::::::::::::::::: 결과 ::::::::::::::::::::::::::::::
=========> PGA 사이즈 조정 : 현재 사이즈 적정
##################################################
### SGA 크기 조정
##################################################
SGA Target Advisory DB/Inst: KMSMESV1/KMSMESV1 End Snap: 886
SGA Target SGA Size Est DB Est DB Est Physical
Size (M) Factor Time (s) Time Factor Reads
---------- -------- -------- ----------- --------------
752 .5 78,897 1.0 5,109,138
1,128 .8 78,044 1.0 4,873,605
1,504 1.0 77,494 1.0 4,723,249
1,880 1.3 77,293 1.0 4,667,665
2,256 1.5 77,238 1.0 4,653,967
2,632 1.8 77,238 1.0 4,653,967
3,008 2.0 77,239 1.0 4,653,967
-------------------------------------------------------------
::::::::::::::::::::::: 결과 ::::::::::::::::::::::::::::::
=========> SGA 사이즈 조정 : 1.5GB -> 2.5GB로 사이즈 조정
★★★★ statspack분석 결과에 의해 SGA_TARGET 파라메타 2.5GB로 재조정.
alter system set SGA_MAX_SIZE=(2.5GB)
##################################################
### shared pool 성능(할당량) 조정
##################################################
1.먼저 현재 사용중인 데이타베이스에 대해 라이브러리 캐시영역에 대한 크기가 적정한지 조사한다.
select namespace,gets,gethits,gethitratio
from v$librarycache
where namespace = 'SQL AREA';
=> 참조 : 만약 gethitratio 컬럼의 값이 90%이상이라면 라이브러리 캐쉬영역이 개발자들의 SQL 파싱정보를 저장하기에 충분한 메모리 공간을
확보하고 있음을 의미하며 만약 90% 이하라면 성능이 저하 될 수도 있다는 것을 의마한다.
=> Quality DB의 경우 다음과 같은 결과가 나옴.
NAMESPACE GETS GETHITS GETHITRATIO
--------------- ---------- ---------- -----------
SQL AREA 885978 878552 .991618302
=========> 99%
## 부가적으로 pins에 대한 reloads의 비율을 확인한다.
select sum(pins),sum(reloads),sum(reloads) / sum(pins)
from v$librarycache
where namespace = 'SQL AREA';
=> 완성차 DB의 경우 다음과 같이 나옴.
SUM(PINS) SUM(RELOADS) SUM(RELOADS)/SUM(PINS)
---------- ------------ ----------------------
85931701 506 5.8884E-06
========> 참조 : PINS에 대한 reloads에 대한 비율이 1%미만일 경우 라이브러리 캐쉬 영역의 크기가 SQL 파싱정보를
저장하기에 충분하다는 의미이다.
현재 할당된 shared_pool 사이즈를 조사한다.
select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
=> 완성차 DB의 경우 다음과 같이 나옴.
POOL MBYTES
------------ ----------
863.996956
shared pool 511.985039
streams pool 48.0495529
large pool 32
java pool 64
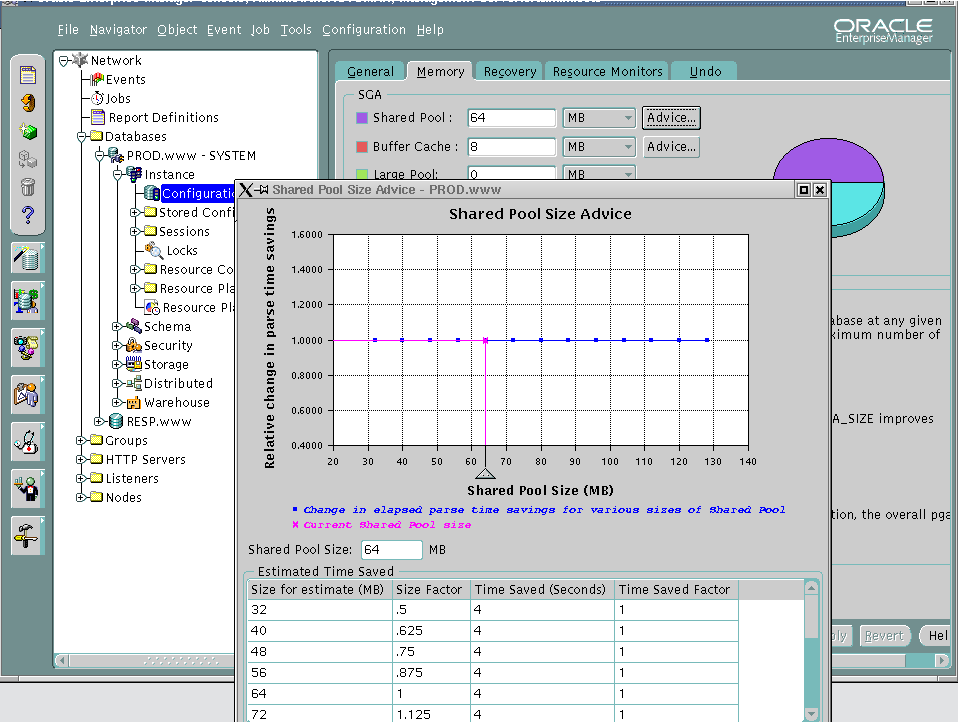
2. Shared pool advice => v$shared_pool_advice 를 이용해서 oracle의 사이즈 advice를 조사한다.
SELECT shared_pool_size_for_estimate "Size of Shared Pool in MB",
shared_pool_size_factor "Size Factor",estd_lc_time_saved "Time Saved in sec"
FROM v$shared_pool_advice;
Shared Pool Advisory DB/Inst: KMSMESV1/KMSMESV1 End Snap: 886
-> SP: Shared Pool Est LC: Estimated Library Cache Factr: Factor
-> Note there is often a 1:Many correlation between a single logical object
in the Library Cache, and the physical number of memory objects associated
with it. Therefore comparing the number of Lib Cache objects (e.g. in
v$librarycache), with the number of Lib Cache Memory Objects is invalid
Est LC Est LC Est LC Est LC
Shared SP Est LC Time Time Load Load Est LC
Pool Size Size Est LC Saved Saved Time Time Mem
Size (M) Factr (M) Mem Obj (s) Factr (s) Factr Obj Hits
---------- ----- -------- ------------ ------- ------ ------- ------ -----------
256 .5 72 4,370 ####### 1.0 33,605 1.4 32,095,562
320 .6 132 7,162 ####### 1.0 28,485 1.2 32,102,312
384 .8 195 12,092 ####### 1.0 24,534 1.0 32,102,864
448 .9 204 13,130 ####### 1.0 24,534 1.0 32,102,864
512 1.0 204 13,130 ####### 1.0 24,534 1.0 32,102,864
576 1.1 204 13,130 ####### 1.0 24,534 1.0 32,102,864
640 1.3 204 13,130 ####### 1.0 24,534 1.0 32,102,864
704 1.4 204 13,130 ####### 1.0 24,534 1.0 32,102,864
768 1.5 204 13,130 ####### 1.0 24,534 1.0 32,102,864
832 1.6 204 13,130 ####### 1.0 24,534 1.0 32,102,864
896 1.8 204 13,130 ####### 1.0 24,534 1.0 32,102,864
960 1.9 204 13,130 ####### 1.0 24,534 1.0 32,102,864
1,024 2.0 204 13,130 ####### 1.0 24,534 1.0 32,102,864
-------------------------------------------------------------+ The above output shows the current setting of the shared pool is
512M (for which Size factor is 1).
+ It also shows decreasing the size of the shared pool to the 50% of its
current value will also be equally efficient as the current value.
+ Also doubling the size of the shared pool will save extra 2300 sec in parsing.
+ Using this view a DBA has the correct picture to design Shared pool.
========> 결론 : 현재 PEMS DB의 shared_pool 사이즈를 init*.ora 파일에서 늘려준다.
shared_pool_size = 800M(????)
### 현재 SGA에 대한 할당 조사
select current_size from v$buffer_pool;
select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
3. SHARED_POOL_RESERVED_SIZE에 대한 성능 조절
=> SHARED_POOL_RESERVED_SIZE는 PL/SQL 블록으로 실행된 sql문의 구문분석 정보를 저장할때 사용되는 공유 풀 영역의 크기를
지정하는 파라메타이다
=> 기본값은 SHARED_POOL_SIZE의 10%이며 최대값은 SHARED_POOL_SIZE 값의 1/2 이다.
=> v$shared_pool_reserved 자료사전의 REQUEST_FAILURES의 컬럼값이 0이 아니거나 계속 증가값을 보일때 이파라메타 값을
크게 해준다.
select request_failures from v$shared_pool_reserved;
REQUEST_FAILURES
----------------
0
========> 결론 :SHARED_POOL_RESERVED_SIZE 변경 없음
SHARED_POOL_RESERVED_SIZE = 25M(?????)
##################################################
#### DB Cache Size 성능 조정
##################################################
1. DB cache advice => v$db_cache_advice 동적 성능 뷰를 이용하여 db cache 사이즈를 시뮬레이션 해본다.
column size_for_estimate format 999,999,999,999 heading 'Cache Size (m)'
column buffers_for_estimate format 999,999,999 heading 'Buffers'
column estd_physical_read_factor format 999.90 heading 'Estd Phys|Read Factor'
column estd_physical_reads format 999,999,999 heading 'Estd Phys| Reads'
SELECT size_for_estimate, buffers_for_estimate,estd_physical_read_factor, estd_physical_reads
FROM V$DB_CACHE_ADVICE
WHERE name = 'DEFAULT'
AND block_size = (SELECT value FROM V$PARAMETER
WHERE name = 'db_block_size')
AND advice_status = 'ON';
Size for Size Buffers Read Phys Reads Est Phys % dbtime
P Est (M) Factr (thousands) Factr (thousands) Read Time for Rds
--- -------- ----- ------------ ------ -------------- ------------ --------
D 80 .1 10 2.1 9,703 21,737 28.0
D 160 .2 20 1.1 5,315 5,540 7.1
D 240 .3 30 1.1 5,029 4,485 5.8
D 320 .4 40 1.0 4,948 4,186 5.4
D 400 .5 50 1.0 4,897 4,001 5.2
D 480 .6 59 1.0 4,862 3,869 5.0
D 560 .6 69 1.0 4,829 3,750 4.8
D 640 .7 79 1.0 4,796 3,628 4.7
D 720 .8 89 1.0 4,761 3,497 4.5
D 800 .9 99 1.0 4,740 3,419 4.4
D 864 1.0 107 1.0 4,723 3,359 4.3
D 880 1.0 109 1.0 4,709 3,306 4.3
D 960 1.1 119 1.0 4,668 3,152 4.1
D 1,040 1.2 129 1.0 4,649 3,083 4.0
D 1,120 1.3 139 1.0 4,621 2,979 3.8
D 1,200 1.4 149 1.0 4,607 2,929 3.8
D 1,280 1.5 159 1.0 4,599 2,899 3.7
D 1,360 1.6 169 1.0 4,594 2,882 3.7
D 1,440 1.7 178 1.0 4,594 2,880 3.7
D 1,520 1.8 188 1.0 4,592 2,875 3.7
D 1,600 1.9 198 1.0 4,580 2,829 3.7
-------------------------------------------------------------
========> 결론 : 현재 PEMS DB의 db_cache 사이즈를 1.6GB로 변경
db_cache_size = 1.6GB(???)
##################################################
#### Redo buffer Size 성능 조정
##################################################
Check the statistic redo buffer allocation retries in the V$SYSSTAT view.
If this value is high relative to redo blocks written, try to increase the LOG_BUFFER size.
Query for the same is
select * from v$sysstat where name like 'redo buffer allocation retries'
or
select * from v$sysstat where name like 'redo blocks written';
혹은 v$sysstat 자료사전에서 서버 프로세스가 로그 정보를 저장했던 로그버퍼의 블록 수(REDO ENTRIES)와 로그버퍼의 경합으로
인해 발생한 대기상태에서 다시 로그 버퍼공간을 할당 받았던 불록 수(redo buffer allocation entries)를 확인한다.
=>이 SQL문에 의한 실행 결과
select name,value
from v$sysstat
where name in ('redo buffer allocation retries','redo entries');
NAME VALUE
---------------------------------------------------------------- ----------
redo entries 23465374
redo buffer allocation retries 91=>0일 수록 좋은것
========> 결론 : 현재 quality DB의 log_buffer 사이즈를 14MB * 2 이상으로 init*.ora 파일에서 늘려준다.
log_buffer = 30M
##################################################
#### java_pool Size 성능 조정
##################################################
** Java Pool advice => v$java_pool_advice
select JAVA_POOL_SIZE_FOR_ESTIMATE,JAVA_POOL_SIZE_FACTOR,ESTD_LC_LOAD_TIME
from v$java_pool_advice
JAVA_POOL_SIZE_FOR_ESTIMATE JAVA_POOL_SIZE_FACTOR ESTD_LC_LOAD_TIME
--------------------------- --------------------- -----------------
4 1 9493
8 2 9493
========> 결론 : 현재 PEMS DB의 java_pool_size 사이즈를 8MB 이상으로 init*.ora 파일에서 늘려준다.
java_pool_size=128M(20971520)
##################################################
#### Redo-log file Size 성능 조정
##################################################
FAST_START_MTTR_TARGET='숫자값'으로 설정한다(V$MTTR_TARGET_ADVICE)
alter system set FAST_START_MTTR_TARGET=300
SQL> select ACTUAL_REDO_BLKS,TARGET_REDO_BLKS,TARGET_MTTR,ESTIMATED_MTTR,
OPTIMAL_LOGFILE_SIZE,CKPT_BLOCK_WRITES from v$instance_recovery;
ACTUAL_REDO_BLKS TARGET_REDO_BLKS TARGET_MTTR ESTIMATED_MTTR OPTIMAL_LOGFILE_SIZE
---------------- ---------------- ----------- -------------- --------------------
942 18432 71 59 49
388462
The recommended optimal redolog file size is 49 MB as seen from column -OPTIMAL_LOGFILE_SIZE.
This is as per the setting of "fast_start_mttr_target" = 170
각 리두로그 사이즈 600M로 조정
$@# !! SQL 튜닝 전에
SQL>alter session set timed_statistics=true;
SQL>alter session set sql_trace=true;
요거 켜주기......
### REDO LOG 파일 재배치 해야함.(물리적으로 서로 다른 디스크 경로에 변경 배치한다)
ALTER DATABASE DROP LOGFILE GROUP 1;
ALTER DATABASE ADD LOGFILE GROUP 1 ('/ora_log/KMSMESV1/rdo1/redo01a.log','/ora_dump/KMSMESV1/rdo2/redo01b.log') SIZE 500M
ALTER DATABASE DROP LOGFILE GROUP 2;
ALTER DATABASE ADD LOGFILE GROUP 2 ('/ora_log/KMSMESV1/rdo1/redo02a.log','/ora_dump/KMSMESV1/rdo2/redo02b.log') SIZE 500M
ALTER DATABASE DROP LOGFILE GROUP 3;
ALTER DATABASE ADD LOGFILE GROUP 3 ('/ora_log/KMSMESV1/rdo1/redo03a.log','/ora_dump/KMSMESV1/rdo2/redo03b.log') SIZE 500M
ALTER DATABASE DROP LOGFILE GROUP 4;
ALTER DATABASE ADD LOGFILE GROUP 4 ('/ora_log/KMSMESV1/rdo1/redo04a.log','/ora_dump/KMSMESV1/rdo2/redo04b.log') SIZE 500M
ALTER DATABASE DROP LOGFILE GROUP 5;
ALTER DATABASE ADD LOGFILE GROUP 5 ('/ora_log/KMSMESV1/rdo1/redo05a.log','/ora_dump/KMSMESV1/rdo2/redo05b.log') SIZE 500M
ALTER DATABASE DROP LOGFILE GROUP 6;
ALTER DATABASE ADD LOGFILE GROUP 6 ('/ora_log/KMSMESV1/rdo1/redo06a.log','/ora_dump/KMSMESV1/rdo2/redo06b.log') SIZE 500M
### ADDITIONAL 1 : Disk I/O 튜닝
select tablespace_name,file_name,phyrds, phywrts
from dba_data_files df,v$filestat fs
where df.file_id = fs.file#;
===============> 결론 : 쿼리 결과 system 테이블 스페이스와 undo table space를 분리해야함.
1.DB SHUTDOWN
2.undo datafile 이동 ex)F:\->H:\
=>이동 후 기존 datafile 삭제
3.db startup(mount까지)
alter database rename file 'E:\ora_data1\KMSMESP1\UNDOTBS01.DBF' to 'H:\ora_data4\KMSMESP1\undo_data\UNDOTBS01.DBF';
alter database rename file 'E:\ora_data1\KMSMESP1\UNDOTBS02.DBF' to 'H:\ora_data4\KMSMESP1\undo_data\UNDOTBS02.DBF';
alter database rename file 'E:\ora_data1\KMSMESP1\UNDOTBS03.DBF' to 'H:\ora_data4\KMSMESP1\undo_data\UNDOTBS03.DBF';
4.DB OPEN
##### redolog 변경 샘플
ALTER DATABASE DROP LOGFILE GROUP 1;
ALTER DATABASE ADD LOGFILE GROUP 1 ('I:\ora_log\KMSMESQ1\rdo1\REDO01A.LOG', 'H:\ora_dump\KMSMESQ1\rdo2\REDO01B.LOG') SIZE 200M;
ALTER DATABASE DROP LOGFILE GROUP 2;
ALTER DATABASE ADD LOGFILE GROUP 2 ('I:\ora_log\KMSMESQ1\rdo1\REDO02A.LOG', 'H:\ora_dump\KMSMESQ1\rdo2\REDO02B.LOG') SIZE 200M;
ALTER DATABASE DROP LOGFILE GROUP 3;
ALTER DATABASE ADD LOGFILE GROUP 3 ('I:\ora_log\KMSMESQ1\rdo1\REDO03A.LOG', 'H:\ora_dump\KMSMESQ1\rdo2\REDO03B.LOG') SIZE 200M;
 sql_tuning_script_etc1.txt
sql_tuning_script_etc1.txt
 \
\