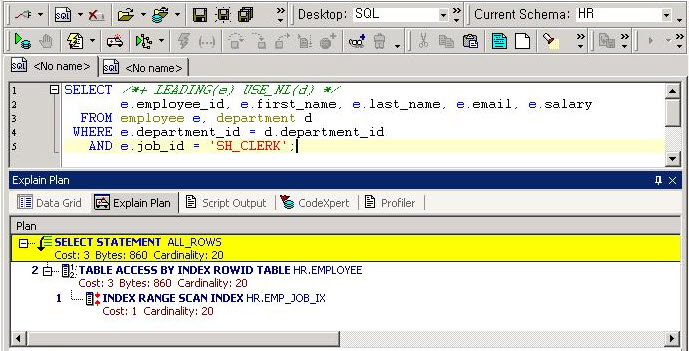
|
수위가 높은 하이 워터 마크
HWM가 어떠한 것일까에 대해서는 제2장으로 해설했습니다.단지, 제2장으로 해설하고 있지 않는 중요한 포인트가 한 개
있습니다.그것은, HWM는 자동에서는 결코 내려가지 않는다는 점입니다.구체적인 낮추는 방법은 다음 번에 설명합니다만 예를 들면
전건을 DELETE문으로 삭제했다고 해도, HWM의 위치는 그대로입니다.
| 그림2:DELETE로 움직이지 않는 하이 워터 마크 |
 |
세그먼트
(segment) 레벨의 HWM는 주로
에 영향을 줍니다.이하 구체적으로 해설합니다.
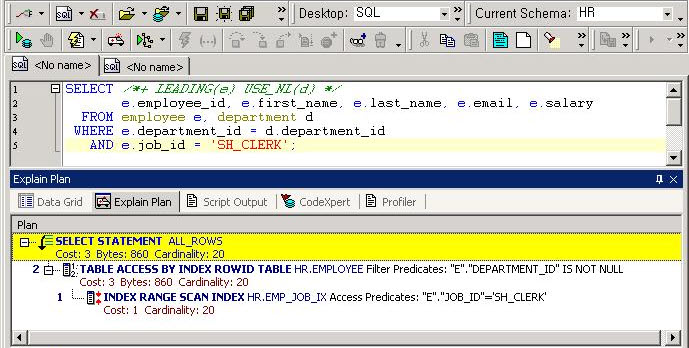
(1)HWM의 전건검색에 대한 영향
테이블이나 인덱스의 풀 스캔을 실행하는
경우, 실제의 스캔 범위는 테이블이나 인덱스 전체가 아니고, HWM의 위치까지를 스캔 합니다.이것에 의해 그림 3의 상부와 같이
실제로 용량을 확보하고 있는 사이즈에 비교해 데이터량이 적은 경우의 처리 시간을 단축하고 있습니다.그러나, HWM가 자동으로
내려갈리 없습니다. 그 때문에 일단 많이 데이터가 들어가 있는 상태로부터 대량 삭제가 있으면, 그림 3의 하부와 같이, 실제로는
데이터가 들어가 있지 않음에도 불구하고 HWM의 위치까지 스캔 해 버려, 실데이터량에 비교해 검색에 시간이 걸려 버립니다.
| 그림3:하이 워터 마크의 풀 스캔시의 영향 |
 |
(2)HWM의 다이렉트 처리에 대한 영향
다이렉트·로드나 다이렉트·로드·인서트는
INSERT문에 의해 데이터를 삽입하는 것이 아니라, 먼저 블록에 저장된 포맷 이미지를 작성해, 그 블록 이미지를 직접
씁니다.그렇기 때문에 조금이라도 데이터가 들어가 있는 블록에는 쓸 수 없습니다. HWM 이후의 블록은 비어 있는 것이 보증되고
있기 때문에, 다이렉트 처리는 그림 4의 상부와 같이 HWM 이후의 블록에 데이터를 씁니다.이러한 처리에 의해 다이렉트 처리는
퍼포먼스를 확보하고 있습니다.덧붙여서 패러렐·다이렉트·로드 때는 HWM 이후의 extent로부터 씁니다. 만약 HWM 이전의
영역에 빈 곳이 많은 경우, 그림 4의 하부와 같이 세그먼트(segment)내에 큰 빈 영역이 생기게 됩니다.만약 이 테이블에
다이렉트 처리에 의한 데이터 삽입 밖에 없는 경우, 이 빈영역은 사용되지 않는채 남아 버립니다.
| 그림4:하이 워터 마크의 다이렉트 처리에의 영향 |
 |
(3)HWM의 위치를 찾는 방법
HWM의 위치를 알려면
DBMS_SPACE 패키지에 있는 UNUSED_SPACE 프로시저를 이용합니다.이 프로시저를 이용하기 위해서는, ANALYZE
혹은 ANALYZE ANY 시스템 권한이 필요합니다. 다만 실제로 ANALYZE를 실시하는 것은 아니기 때문에, 룰 베이스로
운용하고 있는 시스템에서도 이용 가능합니다. 또 빈영역 관리를 프리 리스트가 아닌 자동 세그먼트(segment) 관리(ASSM)를
이용하고 있는 경우는, UNUSED_SPACE 프로시저말고 SPACE_USA GE프로시저를 이용하지 않으면 잘못된 결과가 되어
버립니다.다음의 UNUSED_SPACE 프로시저의 이용 예를 이용해 HWM의 위치가 어떻게 표현되는지를 설명합니다.
SQL>
SQL> set
serveroutput on
SQL> declare
v_total_blocks
number;
v_total_bytes number;
v_unused_blocks number;
v_unused_bytes number;
v_last_used_extent_file_id number;
v_last_used_extent_block_id number;
v_last_used_block number;
begin
dbms_space.unused_space(upper('&uname'), upper('&sename'),
'&stype',
v_total_blocks, v_total_bytes, v_unused_blocks,
v_unused_bytes,
v_last_used_extent_file_id,
v_last_used_extent_block_id, v_last_used_block);
dbms_output.put_line('HWM가 있는 데이터 파일의 ID :'
||
to_char(v_last_used_extent_file_id, '9,999,990'));
dbms_output.put_line('HWM가 있는 extent의 개시 블록 ID :'
||
to_char(v_last_used_extent_block_id, '9,999,990'));
dbms_output.put_line('HWM가 있는 블록의 위치 :'
||
to_char(v_last_used_block, '9,999,990'));
end;
/
uname에
값을 입력해 주세요: SCOTT
sename에 값을 입력해 주세요: CUSTOMERS
stype에 값을 입력해 주세요:
TABLE
구 10:
dbms_space.unused_space(upper('&uname'), upper('&sename'),
'&stype',
신 10: dbms_space.unused_space(upper('SCOTT'),
upper('CUSTOMERS'), 'TABLE',
HWM가 있는 데이터 파일의 ID : 11
HWM
가 있는 extent의 개시 블록 ID : 1,033
HWM가 있는 블럭의 위치
: 6
PL/SQL프로시져가 정상적으로 종료했습니다.
상기 SQL 스크립트의 실행에 있어서, uname에는 세그먼트(segment) 소유자명을,
sename에는 세그먼트(segment)명을, stype에는 세그먼트(segment)의 타입(TABLE/TABLE
PARTITION/TABLE SUBPARTITION/INDEX/INDEX PARTITION/INDEX
SUBPARTITION/CLUSTER/LOB의 어느쪽이든)을 입력한다.
상기 SQL 스크립트의 행 결과를 설명하면「HWM가 있는 데이타
파일의 ID」는 프로시져의 V_LAST_USED_EXTENT_FILE_ID파라미터의 값이 됩니다. DBA_DATA_FILES
딕쇼내리의 FILE_ID열이 V_LAST_USED_EXTENT_FILE_ID파라미터와 일치하는 데이터 파일중에 HWM가 존재하는
것을 나타내고 있습니다
「HWM가 있는 extent의 개시 블록 ID」는, 프로시저의
V_LAST_USED_EXTENT_BLOCK_ID파라미터의 값이 됩니다.???_EXTENTS(이하???(은)는
DBA/ALL/USER의 어느것이든) 딕쇼내리의 FILE_ID열이 V_LAST_USED_EXTENT_FILE_ID와 같고, 한편
BLOCK_ID열이 V_LAST_USED_EXTENT_BLOCK_ID와 일치하는 익스텐트중에 HWM가 존재하는 것을 나타내고
있습니다.「HWM가 있는 블록의 위치」는, 프로시저의 V_LAST_USED_BLOCK 파라미터의 값이 됩니다.해당 extent의
V_LAST_USED_BLOCK 파라미터의 값번째의 블록에 HWM가 존재하는 것을 나타내고 있습니다.
| 그림5:하이 워터 마크의 위치 |
 |
세
그먼트(segment) 레벨의 미사용 영역의 발생 HWM 이후의 미사용 영역
제2장의 데이터 파일의 HWM 이후의 미사용 영역과 같은 영향이 있습니다. HWM 이후의 미사용 영역은 이하와 같은 방법으로
조사할수 있다.
(1)DBMS_SPACE.UNUSED_SPACE프로시져의
사용
앞서 기술한
DBMS_SPACE.UNUSED_SPACE 프로시저를 이용하는 것으로 세그먼트(segment)의 HWM 이후의 미사용 영역의
크기를 계산할 수 있습니다. 아래의 샘플 스크립트를 참조해 주세요.
SQL> set
serveroutput on
SQL> declare
v_total_blocks number;
v_total_bytes number;
v_unused_blocks number;
v_unused_bytes number;
v_last_used_extent_file_id number;
v_last_used_extent_block_id number;
v_last_used_block number;
begin
dbms_space.unused_space(upper('&uname'), upper('&sename'),
'&stype',
v_total_blocks, v_total_bytes, v_unused_blocks,
v_unused_bytes,
v_last_used_extent_file_id,
v_last_used_extent_block_id, v_last_used_block);
dbms_output.put_line('현세그먼트용량:'
|| to_char(v_total_bytes,
'999,999,999,990') || ' バイト');
dbms_output.put_line('소비용량 :'
|| to_char(v_total_bytes - v_unused_bytes, '999,999,999,990') || '
バイト');
dbms_output.put_line('나머지용량 :'
||
to_char(v_unused_bytes, '999,999,999,990') || ' バイト');
dbms_output.put_line('소비율 : '
||
to_char((v_total_bytes - v_unused_bytes) / v_total_bytes * 100,
'990.99') || ' %');
end;
/
uname에 값을 입력해
주세요: SCOTT
sename에 값을 입력해 주세요: CUSTOMERS
stype에 값을 입력해 주세요: TABLE
구10:
dbms_space.unused_space(upper('&uname'), upper('&sename'),
'&stype',
신 10: dbms_space.unused_space(upper('SCOTT'),
upper('CUSTOMERS'), 'TABLE',
현세그먼트용량 : 9,437,184 바이트
소비용량
: 8,593,408 바이트
나머지용량 : 843,776 바이트
소비율
: 91.06 %
PL/SQL프로시져가 정상 종료하였습니다.
상
기 SQL의 실행에 있어서, uname에는 세그먼트(segment) 소유자명을, sname에는 세그먼트(segment)명을,
stype에는 세그먼트(segment)의 타입(TABLE/TABLE PARTITION/TABLE
SUBPARTITION/INDEX/INDEX PARTITION/INDEX SUBPARTITION/CLUSTER/LOB)을
입력한다.
(2)ANALYZE 실행 후 딕쇼내리를 참조한다
테이블의 경우는 ANALYZE를 실행한
후의???_TABLES 딕쇼내리의 BLOCKS와 EMPTY_BLOCKS의 값을 검색하는 것으로도 HWM 이후의 미사용 영역의
크기를 구할 수 있습니다.BLOCKS는 세그먼트(segment)내의 사용이 끝난 블록수, EMPTY_BLOCKS는
세그먼트(segment)내의 미사용 블록수(HWM 이후)를 나타냅니다.
SQL>
analyze table scott.customers compute statistics;
테이블이 분석되었습니다.
SQL>
select
to_char((blocks + empty_blocks) * 8192, 'FM999,999,999,990') as "테이블
용량",
to_char(empty_blocks * 8192, 'FM999,999,999,990') as
"남은용량"
from dba_tables where owner = '&uname' and
table_name = '&tname';
uname에 값을 입력해
주세요: SCOTT
tname에 값을 입력해 주세요: CUSTOMERS
구 3: from dba_tables where
owner = '&uname' and table_name = '&tname'
신 3: from
dba_tables where owner = 'SCOTT' and table_name = 'CUSTOMERS'
테이블
용량 남은용량
-----------------------
--------------------------------
9,428,992
843,776
상기의 테이블의 사용량에 관해서 SQL의 실행에 있어서, uname에는 세그먼트(segment) 소유자명을, tname에는
테이블명을 입력한다.
이 방법에 의한 세그먼트(segment) 용량과 (1)의 DBMS_SPACE.UNUSED_SPACE
프로시저를 이용하는 방법에 따르는 세그먼트(segment) 용량의 1 블록분 (본시험대에서는, 블록 사이즈를 8,192바이트로
하고 있습니다)의 차이는, 세그먼트(segment) 헤더를 포함하는지 포함하지 않는지의 차이입니다.전자가 세그먼트(segment)
헤더를 포함한 크기가 되어 있습니다.
세그먼트(segment) 레벨의 미사용 영역의 발생 HWM 이전의
미사용 영역
HWM 이전의 미사용 영역의 영향은, 본장의 최초로 설명한 HWM의 해설을 참조. 계산방법은, 테이블만의 대응입니다만,
이하와 같은 SQL로 산출할 수 있습니다.
SQL> analyze
table scott.customers compute statistics;
테이블이 분석되었습니다
SQL>
select
to_char(avg_space * blocks, 'FM999,999,999,999') "빈영역"
from
dba_tables where owner = '&uname' and table_name = '&tname';
uname
에 값을 입력해 주세요: SCOTT
tname에 값을 입력해 주세요: CUSTOMERS
구 2: from
dba_tables where owner = '&uname' and table_name = '&tname'
신
2: from dba_tables where owner = 'SCOTT' and table_name = 'CUSTOMERS'
빈
영역
--------------------------------
595,264
상기의 테이블의 사용량에 관해서 SQL의 실행에 있어서 uname에는 세그먼트(segment) 소유자명을, tname에는
테이블명을 입력해 주세요.
계층이 깊은 인덱스
B*Tree 인덱스는 계층 구조로 되어 있습니다. 이 계층이 깊으면 검색에 시간이 걸리게 됩니다. 계층의 깊이는, 인덱스를
ANALYZE 한 뒤 INDEX_STATS 딕쇼내리의 HEIGHT열 내지는 ???_INDEXES 딕쇼내리의 BLEVEL열로 조사할
수 있습니다. 이러한 열의 값이 4이상의 경우는, 인덱스를 이용한 검색의 퍼포먼스에 영향이 있으므로 때문에 재편성을 검토
한다. 또한 INDEX_STATS 딕쇼내리를 검색하는 경우는, VALIDATE STRUCTURE 옵션 첨부로 ANALYZE
커멘드를 실행할 필요가 있습니다.
|