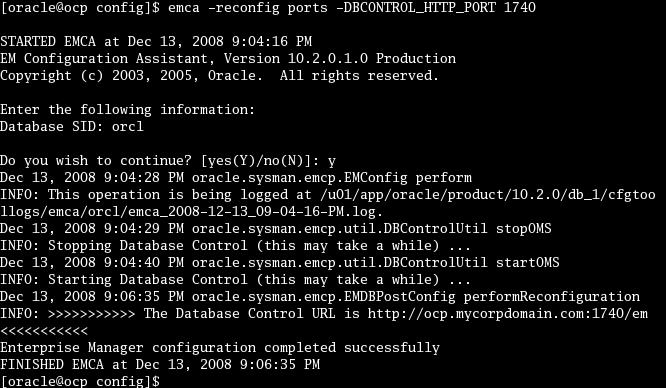
이번달 퀴즈는 두가지 부정형 조인 NOT IN, NOT EXISTS 의 차이점을 설명하는것입니다.
문제를 명확히 하기 위해서 아래와 같은 상황을 고려하겠습니다.
테이블 : TEST1
| NO |
Name
|
|
1
|
Lee
|
|
2
|
Kim
|
|
3
|
Park
|
|
<NULL>
|
Jang
|
|
<NULL>
|
<NULL>
|
테이블 : TEST2
|
NO
|
Name
|
|
1
|
Lee
|
|
2
|
Kim
|
|
3
|
Park
|
|
<NULL>
|
Jang
|
* <NULL>은 데이터가 NULL값인 경우입니다.
테스트 쿼리
1) NOT IN 의 경우
SELECT *
FROM TEST1 A
WHERE A.NO NOT IN (SELECT NO FROM
TEST2)
2) NOT EXISTS 의 경우
SELECT *
FROM TEST1 A
WHERE NOT EXISTS (SELECT 1 FROM
TEST2 B WHERE A.NO = B.NO)
위와 같은 상황에서 두 개의 테스트 쿼리를 실행하여 그 결과에 대해 왜 그렇게 나왔는지 설명하세요.
답안)
이번달 퀴즈의 문제는 NOT IN과 NOT EXISTS의 차이점이 무엇인가입니다.
1번, 2번의 경우에서 NO의 값 1,2,3은 모두 결과에 나오지 않습니다. 즉, TEST2에 속하지 않는것을 찾는것이므로
결과에 나오지 않게됩니다. 차이점은 NULL 값이 결과에 나오는가 아닌가에 있습니다.
NOT IN(1번)의 경우
where절의 조건이 맞는지 틀리는지를 찾는것입니다. 그런데 NULL은 조인에 참여하지 않기때문에 결과에서 빠집니다. 여기서
TEST1의 NULL값이 나오지 않은 이유는 IN 서브쿼리의 결과에 NULL유무에 영향을 받지 않습니다. 즉, TEST2의
NO컬럼에 NULL값이 없어도 TEST1의 NO컬럼의 NULL값은 결과에 나오지 않습니다.
NOT EXISTS(2번)의 경우
EXISTS는 서브쿼리가 TRUE인지 FALSE인지 체크하는 것이므로 NOT EXISTS는 서브쿼리가 FALSE이면
전체적으로 TRUE가 됩니다. 서브쿼리에서 TEST1과 TEST2의 조인시 NULL은 결과에서 빠지게 됩니다. 이것은 서브쿼리를
FALSE로 만들게 되고 전체적으로 TRUE가 되어 TEST1의 NULL값이 결과에 나오게 됩니다.
이번 퀴즈는 매우 쉬운것 같으나 자칫 잘못 생각할 수 있는 내용이기 때문에 퀴즈로 다루었습니다. 일반적으로 대용량을 처리할 때
성능상의 이유로 Hash Anti-Join, Merge Anti-Join으로 유도하기 위해 NOT EXISTS를 NOT IN으로
바꿔서 처리하기도 합니다. 이때 두 부정형 조인의 결과가 같다는 전제 조건이 있어야 합니다. 그러나 위에서와 같이 연결고리가
되는 컬럼의 값 중 NULL이 포함된 경우 결과가 다르다는것을 주의해야 합니다.
=========================================================================================================================
=========================================================================================================================
not in 과 not exists 차이점 / 부정형을 긍정으로 변경할때
일반적으로 대용량을 처리할때 성능상의 이유로 Not Exists로 되어 있는 것을
Not In으로 바꿔서 Hash나 Merge Anti Join으로 유도하는 경우가 있는데
이는 Not Exists와 Not In의 관계가 "="이 성립한다는 전제 조건에서 이루어 진다.
하지만 모든경우 Not Exists와 Not In의 관계가 "=" 성립하는지에 대한 의문에서
아래와 같이 테스트를 해보았습니다.
<결론>
Not In 과 Not Exists는 다르다.
+ Not IN과 Not
Exists의 차이점은 연결고리가 되는 컬럼의
값중 null값을 처리하는 부분에서 차이가 난다.
<이유>
+ Not In 은 where 절의 조건이 만족하더라도
연결고리
컬럼이 Null값을 가진 다면 결과에서 무조건 제외 된다.
+ Not Exists는 Not In과 달리 Null값을 가진 row들도 결과에 포함된다.
+ 간단히 생각해보면 in은 조건에 만족하는 row를 찾는 것이고
exists는 exists이하 절이
true인지 아닌지를 체크하는 것이기 때문에
연결고리 컬럼의 값이 null값을 가질때 null은 조인에 참여하지
못하기 때문에
in은 조건에 만족하는 것을 찾을 수 없는 것이고
exists는 false의 값을
return한다.
따라서 연결고리 값이 null값을 가질때
Not in은 조인
연산을 하지 않기 때문에 결과에서 제외되며
Not Exists는 exists이하의 절이 false를 리턴하고
거기에 대한 Not이기 때문에
결과적으로 true가 되어 결과에 포함된다.
<참고사항>
1) 부정형을 긍정으로 변경할 때
+ Not In일 때는 상관 없지만 Not Exists일때는
논리적으로 부정형을 긍정으로
변경 한 후 연결고리가 되는 컬럼이 null값 가질 경우에
대해서 반드시 True가 되도록 처리해 줘야 된다.
+ 즉 null 값을 가지는 컬럼에 대해서도 결과에 포함 되도록 해야 된다.
ex)
SELECT :current_il,
A.SNG_NO,
A.SNG_SEQ,
A.JI_HANDO,
A.JI_HAN_BAL,
FROM IRMS_SNG_MAS A
WHERE A.WONJ_ST2 =
'1'
AND A.GAGIGONG_GB IN('2','3')
AND NOT
EXISTS(SELECT 'X'
FROM IRMS_SNG_MAS G
WHERE G.WONJ_ST2 = '1'
AND G.GAGIGONG_GB IN('2','3')
AND
(G.MANGI_IL < :current_il AND NVL(G.SIL_BAL,0) = 0)
AND G.SNG_NO = A.SNG_NO
AND
G.SNG_SEQ = A.SNG_SEQ)
<부정형을 긍정형으로 변경>
+ MANGI_IL이 NULL값을 가질때 반드시 참이 되도록 해야 됨.
SELECT :current_il,
A.SNG_NO,
A.SNG_SEQ,
A.JI_HANDO,
A.JI_HAN_BAL,
FROM
IRMS_SNG_MAS A
WHERE A.WONJ_ST2 = '1'
AND
A.GAGIGONG_GB IN('2','3')
AND NOT
(NVL(A.MANGI_IL,'99991231') < :CURRENT_IL AND NVL(A.SIL_BAL,0) = 0)
<테스트 테이브>
TEST_AJ01
TEST_AJ02
<데이타>
TEST_AJ01
========================
NO MARRY_DT
-------------------
1
20030405
2 20030405
3 20030405
<null>
<null>
<null> 20030408
TEST_AJ02
========================
NO MARRY_DT
-------------------
1
20030405
2 20030405
3 20030405
<null>
20030408
# NULL값을 가진 컬럼의 값은 <null>이라고 표현하였음
<테스트 SQL문>
1)
SELECT *
FROM TEST_AJ01 A
WHERE A.NO NOT IN (SELECT NO FROM TEST_AJ02)
==결과== --
0건
No rows returned
2)
SELECT *
FROM TEST_AJ01 A
WHERE NOT EXISTS
(SELECT 'X' FROM TEST_AJ02 B WHERE A.NO = B.NO)
==결과== -- 2건
<null> <null>
<null> 20030408
==========================================================================================================================
==========================================================================================================================
TEST1 테이블의 데이터 중 TEST2에 속하지 않는 데이터만 가져오기 ( NOT IN, NOT EXISTS, JOIN,
UNION 으로 해결 )
중복되지 않는 데이터만 가져와서 INSERT 하거나
중복되는 데이터만 가져와서 UPDATE 할 때 사용할 수도 있다.
CREATE TABLE TEST1 (
IDX INTEGER,
NAME VARCHAR(100)
)
CREATE TABLE TEST2 (
IDX INTEGER,
NAME VARCHAR(100)
)
INSERT INTO TEST1 VALUES (1, 'A')
INSERT INTO TEST1 VALUES (2,
'B')
INSERT INTO TEST1 VALUES (3, 'C')
INSERT INTO TEST1 VALUES
(4, 'D')
INSERT INTO TEST1 VALUES (5, 'E')
INSERT INTO TEST2 VALUES (3, 'C')
INSERT INTO TEST2 VALUES (4,
'D')
INSERT INTO TEST2 VALUES (5, 'E')
INSERT INTO TEST2 VALUES
(6, 'F')
INSERT INTO TEST2 VALUES (7, 'G')
SELECT * FROM TEST1
SELECT * FROM TEST2
-- NOT IN
SELECT *
FROM TEST1
WHERE IDX NOT IN (
SELECT IDX
FROM TEST2 )
-- NOT EXISTS
SELECT *
FROM TEST1 A
WHERE NOT EXISTS (
SELECT *
FROM TEST2 B
WHERE A.IDX = B.IDX )
-- SYBASE JOIN
SELECT *
FROM (
SELECT
A.*
, B.IDX B_IDX
FROM TEST1 A
, TEST2 B
WHERE
A.IDX *= B.IDX
) A
WHERE B_IDX IS NULL
-- ANSI JOIN
SELECT *
FROM TEST1 A
LEFT JOIN TEST2 B
ON A.IDX =
B.IDX
WHERE B.IDX IS NULL
-- UNION ALL
SELECT A.IDX, A.NAME
FROM (
SELECT NAME
, COUNT(*) CNT
, COUNT(CASE WHEN GBN = 'A'
THEN 1 END) A_CNT
, IDX
FROM (
SELECT 'A' AS GBN
, A.*
FROM TEST1 A
UNION ALL
SELECT 'B'
, B.*
FROM TEST2 B
) A
GROUP BY IDX, NAME
) A
WHERE A.CNT < 2
AND A_CNT = 1
출처 : http://blog.naver.com/tyboss?Redirect=Log&logNo=70051601411