cursor_sharing 파라미터에 대한 테스트
오라클 데이터베이스의 파라미터 중 cursor_sharing의 value는 exact, similar, force의 값을 가진다. 값의 설정에 따른 영향도와 정확한 동작 방식을 확인하고자 테스트 진행
테스트 시나리오
child cursor이 생기지 않는 형식의 테스트(bind peeking 사용)
1. 테스트 데이터 생성(num의 값이 unique한 10만건 테이블, 인덱스 생성)
2. cursor_sharing 변경(exact, similar, force)
3. 10개의 JOB 등록(각 JOB은 1만번의 루프를 수행하며 루프 마다 ‘where num = 값’의 조건절 중 값이 리터럴하게 변경되면서 수행)
4. 모니터링
child cursor가 생기는 방식의 테스트(bind peeking 사용)는 위의 방식과 동일한 방식으로 진행되지만 조건절을 ‘where num between A and 값’ 형식으로 값을 변경해 가면서 테스트 진행한다.
사용스크립트
simulation_hard_parsing.sh
|
#!/bin/bash ## $1 =>
Sample Data Row Count ## 등록되는 job을
10 개로 함 ## Hard
Parsing Simulation sqlplus
/nolog <<EOF CONN / AS
SYSDBA GRANT
EXECUTE ON DBMS_SCHEDULER to HR; DECLARE BEGIN FOR C IN 1 ..
10 LOOP
SYS.DBMS_SCHEDULER.DROP_JOB('HR.TEST_SCHEDULE' || '_' ||
C); END
LOOP; END; / CONN
HR/HR -- Make
Test Data @/home/oracle/script/make_sample_data.sql ALL_OBJECTS TEST
$1 -- Index 생성하여 index scan 유도 CREATE
INDEX TEST_IDX ON TEST(NUM,OBJECT_NAME) TABLESPACE
USERS; -- Creation
Procedure for Load DEFINE
P_TOTAL = $1 CREATE OR
REPLACE PROCEDURE CURSOR_SHARING_TEST(P_CNT IN NUMBER DEFAULT 0
) AS V_NUM
NUMBER; V_OBJECT_NAME
VARCHAR2(128); V_OBJECT_ID NUMBER; V_CNT
NUMBER; V_STMT
VARCHAR2(4000); BEGIN V_CNT
:= P_CNT; FOR C IN 1 ..
&P_TOTAL/10 LOOP V_CNT := V_CNT +
1; V_STMT := 'SELECT NUM, OBJECT_NAME, OBJECT_ID
FROM TEST WHERE NUM = ' || V_CNT; EXECUTE IMMEDIATE V_STMT INTO V_NUM, V_OBJECT_NAME,
V_OBJECT_ID; END
LOOP; END; / -- Register
10 Test Schedules CONN / AS
SYSDBA EXECUTE
DBMS_STATS.GATHER_TABLE_STATS (OWNNAME => 'HR',TABNAME => 'TEST' ,
METHOD_OPT => 'for all columns size skewonly' ,DEGREE => 4
,CASCADE => TRUE
); EXEC
DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT; ALTER SYSTEM SET CURSOR_SHARING =
EXACT; ALTER
SYSTEM FLUSH SHARED_POOL; ALTER
SYSTEM FLUSH BUFFER_CACHE; DECLARE BEGIN FOR C IN 1 ..
10 LOOP BEGIN
SYS.DBMS_SCHEDULER.CREATE_JOB(JOB_NAME
=> 'HR.TEST_SCHEDULE' || '_' || C
,JOB_TYPE =>
'STORED_PROCEDURE'
,JOB_ACTION =>
'HR.CURSOR_SHARING_TEST'
,START_DATE =>
CURRENT_TIMESTAMP
,JOB_CLASS =>
'DEFAULT_JOB_CLASS' ,COMMENTS => 'cursor_sharing value
test'
,AUTO_DROP =>
FALSE
,NUMBER_OF_ARGUMENTS => 1
,ENABLED =>
FALSE );
SYS.DBMS_SCHEDULER.SET_ATTRIBUTE(NAME => 'HR.TEST_SCHEDULE' || '_' ||
C
,ATTRIBUTE =>
'logging_level'
,VALUE =>
DBMS_SCHEDULER.LOGGING_FULL
);
SYS.DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE(JOB_NAME => 'HR.TEST_SCHEDULE' || '_' ||
C
,ARGUMENT_POSITION => 1 ,ARGUMENT_VALUE =>
&P_TOTAL/10 * C
);
SYS.DBMS_SCHEDULER.ENABLE('HR.TEST_SCHEDULE' || '_' ||
C); END; END
LOOP; END; / EXIT EOF |
ALTER SYSTEM SET CURSOR_SHARING=EXACT 부분을 바꾸어 가면서 테스트 진행
simulation_hard_parsing_child.sh
|
#!/bin/bash ## $1 =>
Sample Data Row Count ## 등록되는 job을
10 개로 함 ## Hard
Parsing Simulation sqlplus
/nolog <<EOF CONN / AS
SYSDBA GRANT
EXECUTE ON DBMS_SCHEDULER to HR; DECLARE BEGIN FOR C IN 1 ..
10 LOOP
SYS.DBMS_SCHEDULER.DROP_JOB('HR.TEST_SCHEDULE' || '_' ||
C); END
LOOP; END; / CONN
HR/HR -- Make
Test Data @/home/oracle/script/make_sample_data.sql ALL_OBJECTS TEST
$1 -- Index 생성하여 index scan 유도 CREATE
INDEX TEST_IDX ON TEST(NUM,OBJECT_NAME) TABLESPACE
USERS; -- Creation
Procedure for Load DEFINE
P_TOTAL = $1 CREATE OR
REPLACE PROCEDURE CURSOR_SHARING_TEST(P_CNT IN NUMBER DEFAULT 0
) AS V_NUM
NUMBER; V_OBJECT_NAME
VARCHAR2(128); V_OBJECT_ID NUMBER; V_CNT
NUMBER; V_STMT
VARCHAR2(4000); BEGIN V_CNT
:= P_CNT; FOR C IN 1 ..
&P_TOTAL/10 LOOP V_CNT := V_CNT +
1; V_STMT := 'SELECT COUNT(*) FROM TEST WHERE NUM
BETWEEN ' || P_CNT || ' AND ' ||
V_CNT; EXECUTE IMMEDIATE V_STMT INTO V_NUM; END
LOOP; END; / -- Register
10 Test Schedules CONN / AS
SYSDBA EXECUTE
DBMS_STATS.GATHER_TABLE_STATS (OWNNAME => 'HR',TABNAME => 'TEST' ,
METHOD_OPT => 'for all columns size skewonly' ,DEGREE => 4 ,CASCADE
=> TRUE ); EXEC
DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT; ALTER SYSTEM SET CURSOR_SHARING =
EXACT; ALTER
SYSTEM FLUSH SHARED_POOL; ALTER
SYSTEM FLUSH BUFFER_CACHE; DECLARE BEGIN FOR C IN 1 ..
10 LOOP BEGIN
SYS.DBMS_SCHEDULER.CREATE_JOB(JOB_NAME
=> 'HR.TEST_SCHEDULE' || '_' || C
,JOB_TYPE =>
'STORED_PROCEDURE'
,JOB_ACTION =>
'HR.CURSOR_SHARING_TEST'
,START_DATE =>
CURRENT_TIMESTAMP
,JOB_CLASS =>
'DEFAULT_JOB_CLASS'
,COMMENTS => 'cursor_sharing
value test'
,AUTO_DROP =>
FALSE
,NUMBER_OF_ARGUMENTS => 1
,ENABLED =>
FALSE
);
SYS.DBMS_SCHEDULER.SET_ATTRIBUTE(NAME => 'HR.TEST_SCHEDULE' || '_' ||
C ,ATTRIBUTE =>
'logging_level'
,VALUE =>
DBMS_SCHEDULER.LOGGING_FULL
);
SYS.DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE(JOB_NAME => 'HR.TEST_SCHEDULE' || '_' ||
C
,ARGUMENT_POSITION => 1
,ARGUMENT_VALUE => &P_TOTAL/10 *
C
); SYS.DBMS_SCHEDULER.ENABLE('HR.TEST_SCHEDULE'
|| '_' || C); END; END
LOOP; END; / EXIT EOF |
리터럴 SQL 문장이 between을 사용하는 형태로 바뀌었다.
make_sample_data.sql
|
-- usage :
1 => Source Table, 2 => Target Table 3 => target Total
Rows define
cnt=idle DROP TABLE
&2 PURGE; CREATE
TABLE &2 AS SELECT
1 NUM, ROWNUM SOURCE_NUM, A.* FROM
&1 A WHERE
1 = 2; COLUMN
TBL_CNT NEW_VALUE CNT SELECT COUNT( * ) TBL_CNT FROM
&1; INSERT INTO
&2 SELECT
A.NUM, B.* FROM
(SELECT LEVEL
NUM FROM
DUAL CONNECT BY LEVEL <= &3) A, (SELECT ROWNUM - 1 NUM,
A.*
FROM &1 A)
B WHERE
MOD(A.NUM, &CNT) = B.NUM ORDER BY
A.NUM; COMMIT; |
테스트 중 측정할 데이터 리스트
l AWR Report
l ASH Report
l EM Performance Graph
l OS 레벨의 vmstat 정보
테스트 결과1 (child cursor이 생기지 않는 시나리오)
먼저 EM의 성능 그래프를 확인해 보자.
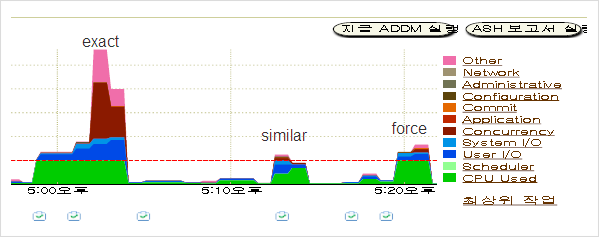
성능 그래프를 확인해 보면 역시 예상대로 exact 부분에서 wait 현상이 발생하는 것을 확인할 수 있다.
EAXCT
AWR Report를 살펴 보자
Load Profile
|
Load
Profile ~~~~~~~~~~~~
Per Second Per
Transaction
---------------
--------------- Redo size: 5,209.31
29,990.00 Logical reads: 1,398.13
8,049.05 Block changes: 16.93
97.48 Physical reads: 21.92
126.21 Physical writes: 5.00
28.76 User calls: 4.18
24.07 Parses: 393.62
2,266.07 Hard parses: 375.25
2,160.33 Sorts: 15.11
87.00 Logons: 0.12
0.67 Executes: 424.32
2,442.79 Transactions: 0.17 |
역시 리터럴 SQL들은 다른 SQL문으로 받아 들여 Hard parse 수치가 높게 나온다.
Instance Efficiency Percentages
|
Instance
Efficiency Percentages (Target 100%) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 100.00
Redo NoWait %:
100.00 Buffer Hit
%: 98.43 In-memory Sort %: 100.00 Library Hit %:
61.36 Soft Parse %: 4.67 Execute to Parse %: 7.23 Latch Hit %: 99.93 Parse CPU
to Parse Elapsd %: 14.10 % Non-Parse CPU:
58.98 |
역시 Library Hit율이 떨어진다.
Top 5 Timed Events
|
Top 5 Timed
Events
Avg %Total ~~~~~~~~~~~~~~~~~~
wait
Call Event Waits Time (s)
(ms) Time Wait
Class ------------------------------ ------------ ----------- ------ ------
---------- CPU
time
206
13.3 db file
sequential read 4,788 103 21
6.6 User
I/O os thread
startup 100 85
852 5.5
Concurrenc latch:
library cache 3,541 58 16
3.7 Concurrenc cursor:
mutex X 6 51
8447 3.3
Concurrenc |
Event 중에 latch: library cache에 대한 event가 많음을 확인할 수 있다.
Time Model Statistics
|
^LTime
Model Statistics
DB/Inst: ORCL/ORCL Snaps:
69-70 -> Total
time in database user-calls (DB Time):
1544.8s ->
Statistics including the word "background" measure background
process time, and so do not contribute to the DB
time statistic ->
Ordered by % or DB time desc, Statistic name Statistic
Name
Time (s) % of DB Time ------------------------------------------ ------------------
------------ sql execute
elapsed time
1,555.0
100.7 parse time
elapsed
1,220.3
79.0 hard parse
elapsed time
508.4
32.9 DB CPU
206.1
13.3 PL/SQL
execution elapsed time 19.6
1.3 connection
management call elapsed time
15.3
1.0 PL/SQL
compilation elapsed time 4.1
.3 hard parse
(sharing criteria) elapsed time
0.8
.1 repeated
bind elapsed time
0.2
.0 hard parse
(bind mismatch) elapsed time
0.1 .0 sequence
load elapsed time
0.0
.0 DB
time
1,544.8
N/A background
elapsed time
221.1
N/A background
cpu time 1.9
N/A |
Time Model의 통계를 확인해 보면 역시나 Hard Parse에 많은 부분을 사용하는 걸 확인할 수 있다.
ASH Report 역시 비슷한 결과에 해당하는 내용이 있다.
SIMILAR
Load Profile
|
Load
Profile ~~~~~~~~~~~~
Per Second Per
Transaction
---------------
--------------- Redo size: 2,690.38
22,573.94 Logical reads: 1,233.33
10,348.35 Block changes: 8.17
68.58 Physical reads: 17.18
144.13 Physical writes: 1.41
11.81 User calls: 4.13 34.61 Parses: 363.36
3,048.84 Hard parses: 2.68
22.45 Sorts: 11.68
97.97 Logons: 0.11
0.90 Executes: 386.53
3,243.26 Transactions:
0.12 |
같은 테스트지만 Hard parse 부분이 많은 부분 없어진 걸 확인할 수 있다. 파라미터 값을 similar로 변경하여 테스트에 사용한 리터럴 SQL이 동일한 문장은 아니지만 같은 플랜을 사용하게끔 인식이 되는 것이다. 그래서 이미 Library Cache에 존재하는 parsing 정보를 사용하기에 Hard parse를 하지 않게 되었다. 이하의 결과에도 마찬가지의 정보를 보여준다.
Instance Efficiency Percentages
|
Instance
Efficiency Percentages (Target 100%) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 100.00
Redo NoWait %:
100.00 Buffer Hit
%: 98.61 In-memory Sort %: 100.00 Library Hit %:
97.66 Soft Parse %: 99.26 Execute to Parse %: 5.99 Latch Hit %: 99.76 Parse CPU
to Parse Elapsd %: 27.30 % Non-Parse CPU:
91.17 |
Library Hit율이 97%까지 올라간 결과를 확인할 수 있다.
Top 5 Timed Events
|
Top 5 Timed
Events
Avg %Total ~~~~~~~~~~~~~~~~~~ wait
Call Event Waits Time (s)
(ms) Time Wait
Class ------------------------------ ------------ ----------- ------ ------
---------- CPU
time
53
13.9 db file
sequential read 4,218 25 6
6.7 User
I/O library
cache load lock 17 3
195 0.9
Concurrenc os thread
startup 13 3
253 0.9
Concurrenc log file
parallel write 123 3 23
0.7 System
I/O |
latch: library cache에 대한 event가 사라진 것을 확인할 수 있다.
Time Model Statistics
|
^LTime
Model Statistics
DB/Inst: ORCL/ORCL Snaps:
71-72 -> Total
time in database user-calls (DB Time):
378.6s ->
Statistics including the word "background" measure background
process time, and so do not contribute to the DB
time statistic ->
Ordered by % or DB time desc, Statistic name Statistic
Name
Time (s) % of DB Time ------------------------------------------ ------------------
------------ sql execute
elapsed time
386.4
102.1 parse time
elapsed
86.6
22.9 DB CPU 52.6
13.9 PL/SQL
execution elapsed time 38.0
10.0 hard parse
elapsed time
21.6
5.7 PL/SQL
compilation elapsed time
4.8
1.3 connection
management call elapsed time
0.4
.1 repeated
bind elapsed time
0.2
.1 hard parse
(sharing criteria) elapsed time
0.2
.0 failed
parse elapsed time 0.2
.0 sequence
load elapsed time
0.0
.0 DB
time
378.6
N/A background
elapsed time 12.0
N/A background
cpu time
1.6
N/A |
전체적으로 parsing과 관련된 시간이 줄어든 것을 확인할 수 있으며 이를 통해 sql execute elapsed time이 줄어 든 것이 확인 가능하다. 결론적으로 DB time 자체가 줄어드는 성능적인 이득을 취하게 된다. 이것을 다르게 말하면 전체적으로 시스템의 Response Time이 확연히 증가함을 말한다. End 유저는 확실한 성능 차이를 체감하게 될 것이다.
ASH Report로 마찬가지의 결과를 보여주고 있다.
FORCE
Load Profile
|
Load
Profile ~~~~~~~~~~~~
Per Second Per
Transaction
---------------
--------------- Redo size: 2,340.54
21,036.32 Logical reads: 966.83
8,689.63 Block changes: 8.08
72.63 Physical reads: 13.81
124.08 Physical writes: 1.17
10.50 User calls: 2.42
21.71 Parses: 278.51
2,503.18 Hard parses: 2.97
26.66 Sorts: 9.02
81.08 Logons: 0.08
0.76 Executes: 297.61
2,674.82 Transactions:
0.11 |
similar 의 경우와 비슷한 수치를 보이고 있다.
Instance Efficiency Percentages
|
Instance
Efficiency Percentages (Target 100%) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 100.00
Redo NoWait %:
100.00 Buffer Hit
%: 98.58 In-memory Sort %: 100.00 Library Hit %:
97.35 Soft Parse %: 98.94 Execute to Parse %: 6.42 Latch Hit %: 99.91 Parse CPU
to Parse Elapsd %: 33.57 % Non-Parse CPU:
93.78 |
similar 의 경우와 비슷한 수치를 보이고 있다.
Top 5 Timed Events
|
Top 5 Timed
Events
Avg %Total ~~~~~~~~~~~~~~~~~~
wait
Call Event Waits Time (s)
(ms) Time Wait
Class ------------------------------ ------------ ----------- ------ ------
---------- CPU
time 77
13.2 db file
sequential read 4,384 20 5
3.4 User
I/O job
scheduler coordinator slav
1 8 7984
1.4
Other Streams AQ:
qmn coordinator wa 1 5
4884 0.8 Other os thread
startup 13 4
276 0.6
Concurrenc |
latch: library cache에 대한 event가 사라진 것을 확인할 수 있다.
Time Model Statistics
|
^LTime
Model Statistics
DB/Inst: ORCL/ORCL Snaps:
73-74 -> Total
time in database user-calls (DB Time):
585.2s ->
Statistics including the word "background" measure background
process time, and so do not contribute to the DB
time statistic ->
Ordered by % or DB time desc, Statistic name Statistic
Name
Time (s) % of DB Time ------------------------------------------ ------------------
------------ sql execute
elapsed time
597.6
102.1 parse time
elapsed 122.9
21.0 DB CPU
77.4
13.2 PL/SQL
execution elapsed time 44.4
7.6 hard parse
elapsed time
21.8 3.7 PL/SQL
compilation elapsed time 3.4
.6 hard parse
(sharing criteria) elapsed time
0.7
.1 connection
management call elapsed time
0.2
.0 repeated
bind elapsed time
0.2
.0 failed
parse elapsed time 0.1
.0 sequence
load elapsed time
0.1
.0 hard parse
(bind mismatch) elapsed time
0.0
.0 DB
time
585.2
N/A background
elapsed time
27.2
N/A background
cpu time
2.3
N/A |
similar 때와 비슷한 상황으로 분석된다.
테스트 결과2 (child cursor이 생기는 시나리오)
child cursor의 발생 상황에 대해서 먼저 정의가 필요하다. cursor_sharing 파라미터의 값이 similar일 경우 오라클은 실행계획이 같다고 판단이 되는 경우 동일한 형태의 리터럴 SQL 문장에 대해서 같은 문장으로 인식하고 사용하게끔 한다. 하지만 실행계획은 같지만 포함된 통계정보가 다를 경우 같은 문장으로는 인식을 하지만 재사용을 하는 것이 아니라 child cursor을 생성하여 수행하게 된다. 여기에는 여러 변수가 작용할 수 있다. Bind peeking과 히스토그램, 옵티마이저의 방식 등등이 영향을 미치게 된다.
테스트 시스템은 bind peeking을 사용하며 CBO 방식을 사용했으며 child cursor이 발생하는 환경으로 세팅을 완료했다.
다음은 테스트 결과를 보도록 하겠다.
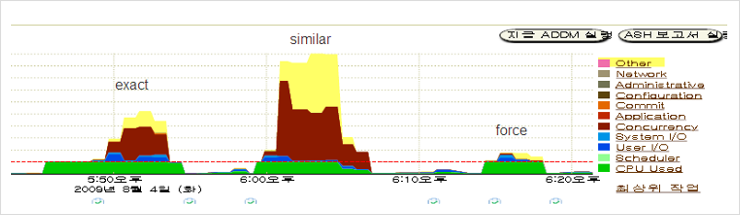
Similar의 경우 오히려 더 많은 wait event가 발생한 것을 확인할 수 있다.
exact, force인 경우 테스트1의 경우와 비슷한 레벨로 보이고 similar에서는 오히려 성능이 더 떨어지는 그래프를 보이고 있다. 결론적으로 similar인 경우에 대해서는 테스트를 완료할 수 없었다. Child cursor이 3만개 이상 발생하자 Job slave가 terminated 되고 오라클 600에러를 내면서 작업이 fail로 끝나게 된다.
결론
cursor_sharing 파라미터의 경우 많은 부분이 해당 value인 exact, similar, force에 대한 용어적 해석을 통한 접근으로 정확하지 않은 표현으로 가이드 되는 경우가 많다.
테스트의 출발은 위 value가 정확히 어떤 기준으로 동작하는지 확인 하는 것이었다.
Similar인 경우 실행계획이 같은 문장에 한해서는 같은 문장으로 인식하고 library cache에 로딩되어 있는 정보를 그대로 사용한다. 하지만 플랜에 포함된 통계정보가 다르다고 판단이 되는 실행계획일 경우 child cursor을 생성하여 사용하게 된다. 즉 similar인 경우 통계정보까지도 동일한 형태의 실행계획일 경우에 child cursor을 생성하지 않고 사용하게 된다. 반면 force인 경우는 실행계획만 같다면 similar와 다르게 같은 문장으로 인식하여 cache된 정보를 재사용하게 한다.
그렇다면 파라미터에 대해선 어떻게 사용해야할까..?
이는 상황에 따라서 다르겠지만 여러가지를 종합적으로 고려를 해야한다. 분명 가이드는 exact 이다. 그리고 bind 변수 사용에 대해 최대한 권장을 해야한다. 임시방편 격으로 similar, force를 사용 가능하다. 하지만 이것도 고려 사항이 있다. Similar인 경우 child cursor가 발생하는 형식으로 된다면 시스템은 버티기가 힘들 것이다. 즉 사이드 이펙트가 없는 상황일 경우에 쓸만하다는 것이다. 그렇다면 force를 쓰는게 더 낫지 않겠냐는 반문이 나올 것이다. 하지만 이도 문제 요소가 있다. 데이터의 분포가 균등하지 못한 경우 사용되는 변수의 값이 어떤 것이냐에 따라서 적합한 실행계획이 다른 바뀔 것이다. Force의 경우 이런 케이스를 커버하지 못한다는 단점이 있는 것이다.
[출처]
cursor_sharing
파라미터에 대한 테스트|작성자
명품
관
'ORACLE > TUNING' 카테고리의 다른 글
| EXPLAIN PLAN(실행계획) 이란 (0) | 2010.01.12 |
|---|---|
| Statspack Report 간단 분석 방법 (0) | 2009.12.17 |
| Literal SQL 조회하는 방법 (0) | 2009.12.05 |
| DML 과 PARALLEL의 관계 (0) | 2009.11.06 |
| Oracle dump 뜨는 방법 (0) | 2009.05.08 |












