ORA-04031: unable to allocate … shared memory
--------------------------------------------------------------------------------
Symptom:
The Oracle error:
ORA-04031: unable to allocate nnn bytes of shared memory
Cause:
More shared memory is needed than was allocated. SGA private memory has been exhausted.
Fragmentation of shared pool memory is a common problem and ORA-04031 is commonly a result of such fragmentation. Application programmers usually get this error while attempting to load a big package or while executing a very large procedure and there is not sufficient contiguous free memory available in the shared pool. This may be due to fragmentation of the shared pool memory or insufficient memory in the shared pool.
Possible remedies:
Use the dbms_shared_pool package to pin large packages.
Attempt to reduce the use of shared memory.
Increase the initialisation parameter ‘SHARED_POOL_SIZE’.
--------------------------------------------------------------------------------
Alternate symptom
An error of the form (Oracle 8.1.5):
ORA-04031: unable to allocate NNNNN bytes of shared memory ("large pool","unknown object","large pool hea","PX msg pool")
Cause:
This error indicates that Oracle is unable to allocate memory from the ‘large’ pool.
To determine the number of free bytes in the ‘large’ pool execute the following SQL:
SELECT NAME, SUM(BYTES) FROM V$SGASTAT WHERE POOL='LARGE POOL' GROUP BY ROLLUP (NAME);
Possible Remedy:
To resolve the problem, consider increasing the value for ‘LARGE_POOL_SIZE’.
ERROR:
ORA-00604: error occurred at recursive SQL level 2
ORA-04031: unable to allocate 4048 bytes of shared memory ("shared
pool","TRIGGER$SYS","sga heap","state objects")
ORA-00604: error occurred at recursive SQL level 1
ORA-04031: unable to allocate 4048 bytes of shared memory ("shared
pool","unknown object","sga heap","state objects")
DB를 관리하면서 다음과 같은 에러를 직면할때가 있느데 이럴 경우에는 신속하게
대처할 수 있는 방법
1. 오래된 세션을 끊어서 shared pool 에 잡고 있는 메모리를 해제 시켜준다.
2. alter system flush shared_pool; 명령어를 통해 메모리 조각모임을 해준다.
장기적인 대책은
단편화 시키는 SQL를 찾아내고 바인딩 변수화 시킨다.
ORA-04031 의 경우 shared pool 내에 메모리 조각화에 따라서 연속된 parsing 공간을 제공하지 못하기 때문에 발생하는 에러입니다.
다시 말해서 parsing 에러가 발생하는 것입니다.
이를 해소 해주기 위한 방법으로
개체가 큰 자주 사용되는 프로시져등을 메모리에 pined 해주면 되며,
shared pool 사이즈를 늘려 주는것이 가장 좋으며,
상황이 여의치 않는 경우 단편화된 shared pool 의 조각화을 다시 flush 해주는 방법
등이 있습니다.
SQL> alter system flush shared_pool;
shared pool 의 hit 율을 잘 분석해 보시고 오라클의 권장사항에 따라서 튜닝 가이드 라인을 정하는게 중요합니다.
너무 크게 줘서 free size 가 너무 많이 남는 경우 즉 hit 율은 좋은데, free size 가 너무 큰 경우는 메모리 낭비를 하게 되며, 각각의 o/s 에 따라서 paging 이나 swap 이 발생할 가능성이 있으니, 튜닝후 적적할 모니터를 통해서 사이즈를 잡아 가는 것이 좋습니다.
SQL> select name, bytes/1024/1024 "Size in MB" from v$sgastat where name='free memory';
NAME Size in MB
-------------------------- ----------
free memory 451.496498
free memory .5859375
free memory .03125
즉 오라클의 동적 뷰들의 대부분은 current 한 내용이 아닌 축적용으로 평균치를 나타 내기 때문에 의미가 없습니다.
======================================================================================================================
Ora-00604 또는 Ora-04031 에러 메세지 발생했을 때 아래 내용에 따라 오류를 조치하기 바랍니다.
1. 발생 원인
Shared Pool의 사용 가능한 Memory 가 시간이 흐름에 따라 작은 조각으로 분할되어 진다는 것이다.
그래서 큰 부분의 Memory 를 할당하려 한다면 Shared Memory가 부족하다는 ORA-4031 Error가 발생한다.
즉, 전체적으로는 많은 양의 사용 가능한 Space가 있다 하더라도 충분한 양의 연속적인 공간이 없으면 이 Error가 발생한다.
2. 조치 방법
DB를 관리하면서 다음과 같은 에러를 직면할때가 있느데 이럴 경우에는 신속하게 대처할 수 있는 방법
1. 오래된 세션을 끊어서 shared pool 에 잡고 있는 메모리를 해제 시켜준다.
2. alter system flush shared_pool; 명령어를 통해 메모리 조각모임을 해준다.
3. Shared_Pool에 크기가 큰 프로그램을 Keep 을 시켜준다.
장기적인 대책은 단편화 시키는 SQL를 찾아내고 바인딩 변수화 시킨다.
이를 해소 해주기 위한 방법으로 개체가 큰 자주 사용되는 프로시져등을 메모리에 pined 해주면 되며,
shared pool 사이즈를 늘려 주는것이 가장 좋으며, 상황이 여의치 않는 경우 단편화된 shared pool 의 조각화을
다시 flush 해주는 방법과 인스턴스를 내렸다 올리는 방법도 있습니다.
SQL> alter system flush shared_pool;
======================================================================================================================
ORA-4031의 솔루션은 그 원인에 따라 다양한 방법이 있습니다.
먼저 ORA-4031가 발생하는 원인은, SHARED_POOL을 관리하는 과정에, 많은 조각화(Fragment)가 발생하고 Free Memory가 아주 적은 상태에서, 커다란 SQL(PL/SQL)이 Memory로 Load 될 때 공간이 부족해서 발생할 수 있습니다.
이 ora-4031 Error가 발생하게 되면, Shared pool의 관리가 원활히 되지 않아, 이후에 수행되는 모든 SQL이 error가 발생합니다. 그러므로 이는
반드시 예방되어야 합니다.
이러한 Memory관리상의 문제를 해결하기 위해 조치 할 수 있는 것은 아래의 것들이 있습니다.
1. v$sql 내의 Literal SQL이 많은지 확인한다.
많은 경우 Literal SQL을 사용하는 SQL을 찾아서 공유 할수 있도록 Bind Variable을 사용토록 하면 됩니다.
=> Literal SQL을 찾는 방법.
select substr(sql_text, 1, 40) "SQL",
count(*) cnt,
sum(executions) "TotExecs",
sum(sharable_mem) mem,
min(first_load_time) start_time,
max(first_load_time) end_time,
max(hash_value) hash
from v$sqlarea
where executions < 5 --> 수행 횟수가 5번 이하인 것.
group by substr(sql_text, 1, 40)
having count(*) > 30 --> 비슷한 문장이 30개 이상.
order by 2 desc;
2. v$sql 내의 sharable Memory가 큰것들을 확인 한다.
1M byte이상의 SQL이 있다면 확인 후 SQL의 복잡도를 줄인다(recursive call을 많이 한다든지..). 대부분의 경우 크기가 큰 것들은 일반 SQL이 아니라 PL/SQL이므로 이러한 것들은 Memory에서 내려오지 않도록 Pin을 시키는 방법도 있습니다. (그렇다고 memory에서 완전히 안내려 오는 것은 아닙니다.)
=> PL/SQL을 Memory에 Pin시키는 방법.
execute dbms_shared_pool.keep('SCOTT.HELLO_WORLD');
3. SHARED_POOL_SIZE와 SHARED_POOL_RESERVED_SIZE의 크기를 늘린다.
항상 Shared pool의 Free가 여유가 있도록 shared_pool_size를 크기를 좀 늘리시고
특히 Shared_pool_reserved_size의 크기를 100M정도 되도록 지정하세요. 경험적으로 shared_pool_reserved_size가 100M정도 지정하면 ora-4031가 많이 발생하지는 않더군요.
Free공간 확인 .
SELECT free_space, avg_free_size, used_space,
avg_used_size, request_failures, last_failure_size
FROM v$shared_pool_reserved;
4. 이것이 진짜 마약처럼 잘 듯는 방법인데, 9i부터는 Shared_pool의 관리를 좀더 효율적으로 하고 System의 CPU를 효과적으로 사용하기 위해 하나의 heap memory를 사용하던 것을 subheap으로 나누어 관리를 하고 있지요. 이렇게 sub-heap으로 나누어 관리하다 보니 작은 공간이 sub heap에 동시에 있더라도 이를 잘 활용하지 못해서 발생하는 경우가 있습니다. 이러한 이유로 ORA-4031 Error의 원인이 되는 경우가 종종 있습니다.
현재 시스템이 Multi CPU인 경우에는 아마도 1보다 큰 값으로 되어 있을 겁니다.
그래서 아래의 Query로 조회해 본 후 그 값이 1보다 큰 값이라면 init.ora에서
_kghdsidx_count=1로 지정한 후 restart해서 사용해 보세요. 어지간해서 ORA-4031가발생 하지 않을 겁니다.
select x.ksppinm, y.ksppstvl
from x$ksppi x , x$ksppcv y
where x.indx = y.indx
and x.ksppinm like '_kghdsidx_count%' escape ''
order by x.ksppinm;
==========================================
결과 수치 값 예
==========================================
select x.ksppinm, y.ksppstvl
from x$ksppi x , x$ksppcv y
where x.indx = y.indx
and x.ksppinm like '_kghdsidx_count%'
order by x.ksppinm
KSPPINM KSPPSTVL _kghdsidx_count
--------------------------------------------------------------------------------
4
shared pool flush 시키기
SQL> alter system flush shared_pool;
출처 : OTN - Technical Bulletins
No. 10095
ORA-4031 조치 방법 과 DBMS_SHARED_POOL STORED PROCEDURE 사용법
==============================================================
Purpose
-------
다음과 같은 작업 수행 시 Oracle 이 Shared pool 에서 연속적인
메모리 부분을 찾지 못해 ORA-4031 에러를 발생시키는 것을 볼 수 있다.
. PL/SQL Routine
. Procedure 수행 시
. Compile 시
. Forms Generate 또는 Running 시
. Object 생성하기 위해 Installer 사용 시
본 자료에서는 이러한 에러에 대한 대처 방안을 설명 하고자 한다.
Problem Description
-------------------
Error 발생의 주된 원인은 Shared Pool의 사용 가능한 Memory 가 시간이
흐름에 따라 작은 조각으로 분할되어 진다는 것이다. 그래서 큰 부분의
Memory 를 할당하려 한다면 Shared Memory가 부족하다는 ORA-4031 Error가
발생한다. 즉, 전체적으로는 많은 양의 사용 가능한 Space가 있다 하더라도
충분한 양의 연속적인 공간이 없으면 이 Error가 발생한다.
1. Shared Pool과 관련된 인스턴스 파라미터
다음 3가지 파라미터는 본 자료를 이해 하는데 매우 중요하다.
* SHARED_POOL_SIZE - Shared Pool 의 크기를 지정 한다. 정수를 사용하며
"K" 나 "M" 을 덧붙일 수 있다.
* SHARED_POOL_RESERVED_SIZE - 공유 풀 메모리에 대한 대량의 연속 공간
요청에 대비해서 예약하는 영역의 크기를 지정한다. 이 영역을 사용하기
위해서는 SHARED_POOL_RESERVED_MIN_ALLOC 보다 큰 영역 할당 요청이어야
한다. 일반적으로 SHARED_POOL_SIZE 의 10% 정도를 지정한다.
* SHARED_POOL_RESERVED_MIN_ALLOC - 예약 메모리 영역의 할당을 통제한다.
이 값보다 큰 메모리 값이 할당 요청되었을 때 공유 풀의 free list 에
적합한 메모리 공간이 없으면 예약된 메모리 공간의 리스트에서 메모리를
할당해 준다. 이 값은 8i부터는 내부적으로만 사용된다.
Workaround
-----------
Re-start the instance
Solution Description:
---------------------
이 Error 해결방안을 살펴 보면 다음과 같다.
1. 혹시 알려진 제품 문제에 해당 되지 않는지 확인 한다.
* BUG 1397603: ORA-4031 / SGA memory leak of PERMANENT memory occurs
for buffer handles. (Workaround: _db_handles_cached=0, Fixed: 8172,
901 )
* BUG 1640583: ORA-4031 due to leak / cache buffer chain contention
from AND-EQUAL access. (Fixed: 8171,901 )
* BUG 1318267: INSERT AS SELECT statements may not be shared when they
should be if TIMED_STATISTICS. It can lead to ORA-4031. (Workaround:
_SQLEXEC_PROGRESSION_COST=0, Fixed: 8171, 8200)
* BUG 1193003: Cursors may not be shared in 8.1 when they should be
(Fixed: 8162, 8170, 901)
2. Object를 Shared Pool에 맞추어 Fragmentation을 줄인다.
(Dbms_Shared_Pool Procedure 이용)
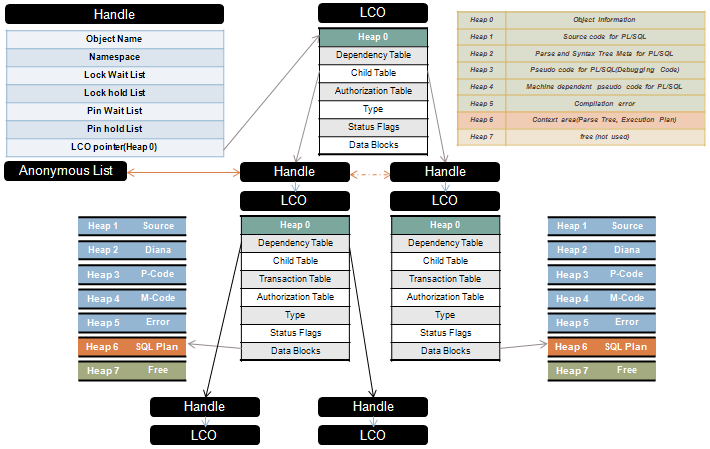
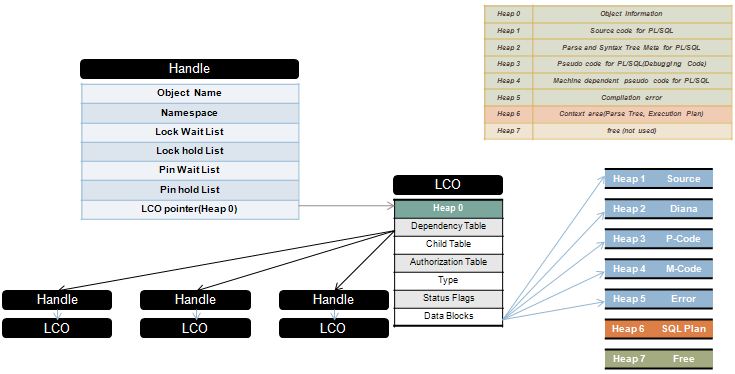
다음은 크기가 크고 빈번히 access되는 package들임.
standard packages
dbms_standard
diutil
diana
dbms_sys_sql
dbms_sql
dbms_utility
dbms_describe
pidl
dbms_output
dbms_job
3. Shared Pool 을 효율적으로 사용하도록 Application Program을 조절한다.
4. 메모리 할당을 조정한다.
우선 다음 쿼리로 library cache 문제인지 shared pool reserved space 문제인지 진단한다.
SELECT free_space, avg_free_size, used_space,
avg_used_size, request_failures, last_failure_size
FROM v$shared_pool_reserved;
만일 REQUEST_FAILURES is > 0 and LAST_FAILURE_SIZE is >
SHARED_POOL_RESERVED_MIN_ALLOC
이면 ORA-4031 은 Shared Pool 의 연속 공간 부족의 결과이다.
해결책: SHARED_POOL_RESERVED_MIN_ALLOC 값을 증가 시켜서 shared pool
reserved space 에 올라가는 오브젝트의 수를 줄인다. 그리고
SHARED_POOL_RESERVED_SIZE 와 SHARED_POOL_SIZE 를 충분히 확보
해 준다.
만일 REQUEST_FAILURES is > 0 and LAST_FAILURE_SIZE is <
SHARED_POOL_RESERVED_MIN_ALLOC
이거나
REQUEST_FAILURES is 0 and LAST_FAILURE_SIZE is <
SHARED_POOL_RESERVED_MIN_ALLOC
이면 ORA-4031 은 library cache 내의 연속된 공간 부족의 결과 이다.
해결책: SHARED_POOL_RESERVED_MIN_ALLOC 을 줄여서 shared pool reserved
space 를 보다 쉽게 사용할 수 있도록 해준다. 그리고 가능하면
SHARED_POOL_SIZE 를 증가시킨다.
5. DBMS_SHARED_POOL STORED PROCEDURE 사용법
이 stored package는 dbmspool.sql을 포함하며 7.0.13 이상 version에서 사용
가능하다. 이는 다음과 같이 3가지 부분으로 나누어 진다.
Procedure sizes(minsize number):
-> Shared_Pool_size 안에서 정해진 Size 보다 큰 Object를 보여준다.
Procedure keep(name varchar2, flag char Default 'P'):
-> Object (Only Package)를 Shared Pool 에 유지한다. 또한 일단 Keep한
Object는 LRU Algorithm에 영향을 받지 않으며
"Alter System Flush Shared_Pool" Command 에 의해 Package 의 Compiled
Version 이 Shared Pool에서 Clear되지 않는다.
Procedure unkeep(name varchar2):
-> keep() 의 반대 기능이다
이 Procedure들과 사용법에 대해 보다 더 자세한 정보를 위해서는 $ORACLE_HOME/rdbms/admin/dbmspool.sql script 또는 오라클 레퍼런스매뉴얼을 참조하기 바람.
Reference Documents
-------------------
<NOTE:146599.1> Diagnosing and Resolving Error ORA-04031.
No. 19876
(V7.X ~ V9.2)예제를 통한 ORA-4031 ERROR 실제 사례의 분석(SHARED POOL)
=====================================================================
Purpose
-------
이 자료는 ORA-4031 에러가 발생하는 여러가지 case 가운데 사이즈가 큰 PL/SQL Routine 또는 Procedure가 메모리에 로드되기 위하여
주로 발생하는 ORA-4031 사례에 대한 예제와 분석을 소개하는 자료이다.
Problem Description
-------------------
Procedure, function, package 등의 library가 shared pool 영역에 할당되려고 할 때 ORA-4031 에러가 발생하는 경우가 있다. 이 때
shared memory를 많이 차지하는 query를 어떻게 추적하는지 사례를 통해 알아보기로 한다.
Workaround
----------
restart instance or flush shared pool
keep large objects in memory
Solution Description
--------------------
SYS.X$KSMLRU 와 SYS.X$KSMSP 는 shared pool memory의 사용 현황을
보여주는 오라클의 base table들이다.
1. SYS.X$KSMLRU
SYS.X$KSMLRU 를 보면
이 fixed table은 shared pool 영역에 cache되기 위해 다른 object를 밀어낸(aged out) allocation들에 대한 정보를 담고 있다.
이 table을 통해 어떤 object가 많은 공간을 메모리에 차지하면서 할당되었는지 알 수 있는데, 한 번 조회하고 나면 조회된 정보는 테이블에서 remove된다.
KSMLRCOM 부분이 'MPCODE'나 'PLSQL%' 로 시작한다면, 큰 사이즈의 PL/SQL object가 shared pool 영역에 load된 것이므로,
이 procedure는 memory에 keep되어지면 좋다는 결론이 나오는데, SYS.X$KSMLRU 를 조회한 결과를 보아야 한다.
SYS.X$KSMLRU에 만약 아무것도 조회되지 않는다면, 그러니까, 큰 object가 memory에 load되기 위해 다른 object가 aged out된 것은 없다는 것을 의미한다.
이 fixed table의 column에는 다음과 같은 것이 있다.
=================================================================
KSMLRSIZ : allocate된 연속된 memory size.
이 크기가 5K가 넘으면 문제될 소지가 있다고 보고,
10K가 넘으면 심각한 문제가, 20K가 넘으면 매우 심각한
문제를 야기할 수 있으므로 주의가 필요하다.
KSMLRNUM : 이 object의 할당으로 인하여 flush되었던 object의 갯수.
KSMLRHON : load되고 있는 object의 이름.(PL/SQL or a cursor)
KSMLROHV : load되고 있는 object의 hash value.
KSMLRSES : 이 object를 load한 session의 SADDR 값.
=================================================================
2. SYS.X$KSMSP
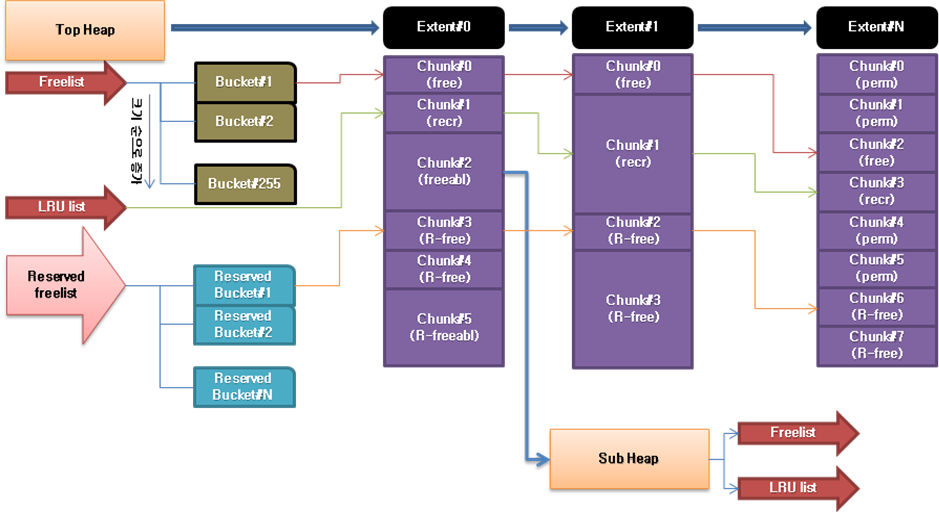
SYS.X$KSMSP 뷰를 조회하면 shared pool 영역의 free space와 flush할 수 있는 freeable space에 대한 조각이 얼마인지 확인할 수 있다.
ORA-4031 오류가 발생했을 때, V$SGASTAT 뷰를 통해서는 shared pool 영역의 전체 free space만 확인 가능하지만, 이 뷰를 조회하면
memory space 조각에 대한 정보도 볼 수 있다.
이 fixed table의 column에는 다음과 같은 것이 있다.
(Allocate된 chunk 하나 당 하나의 row가 생성된다.)
=================================================================
KSMCHCLS : CHUNK의 CLASS
(free : free, freeable : freeable, perm : permanent,
recr : recreatable)
KSMCHSIZ : CHUNK의 사이즈
KSMCHCOM : CHUNK에 대한 속성을 나타내는 간단한 text comment
KSMCHPTR : 메모리 상에서 LOCATION에 대한 HEX value
=================================================================
SQL> select ksmchcls, MAX(ksmchsiz), SUM(ksmchsiz)
from sys.x$ksmsp
group by ksmchcls;
KSMCHCLS MAX(KSMCHSIZ) SUM(KSMCHSIZ)
-------- ------------- -------------
R-free 671600 6044400
R-freea 40 720
free 16105472 106453784
freeabl 124176 5391136
perm 15650000 31052280
recr 6496 2052048
6 rows selected.
Example
-------
SQL> select ksmchcls, MAX(ksmchsiz), SUM(ksmchsiz)
from sys.x$ksmsp
group by ksmchcls;
KSMCHCLS MAX(KSMCHSIZ) SUM(KSMCHSIZ)
-------- ------------- -------------
R-free 138716800 139574016
R-freea 8152 236200
free 21712 987208
freeabl 50680 234508992
perm 47020752 53054992
recr 12168 30352488
6 rows selected.
SQL> select * from X$KSMLRU
where KSMLRSIZ > 0;
ADDR INDX INST_ID KSMLRCOM KSMLRSIZ KSMLRNUM KSMLRHON KSMLROHV KSMLRSES
---------------- --------- --------- -------------------- --------- --------- -------------------------------- --------- ----------------
C0000000472FA428 0 1 PAR.C:parchk:page 2120 8 BEGIN PRD_WS_NEXT2( ... 3.325E+09 C00000002B8DA980
C0000000472FA470 1 1 KQLS MEM BLOCK 2288 8 WGQCT 4.034E+09 C00000002B867680
C0000000472FA4B8 2 1 seldef : kkmset 2552 8 SELECT MJCD,fun_aa_nm1(mjcd)... 850201559 C00000002B915F80
C0000000472FA500 3 1 lazdef : kkmset 2568 8 SELECT MJCD,fun_aa_nm1(mjcd)... 265721063 C00000002B8DA980
C0000000472FA548 4 1 lazdef : kkmset 2664 8 select mjnm,mjcd,sum(jg1) j... 1.594E+09 C00000002B85FB00
C0000000472FA590 5 1 idndef : prsexl 3112 3 SELECT /*+ rule */ * FROM sy... 4.285E+09 C00000002B8FF680
C0000000472FA5D8 6 1 BAMIMA: Bam Buffer 3896 8 YYCAT_T1 1.175E+09 C00000002B857600
C0000000472FA620 7 1 state objects 4080 8 0 C00000002B8C9600
C0000000472FA668 8 1 BAMIMA: Bam Buffer 4168 168 BEGIN PRD_WS_NEXT2( ... 4.036E+09 C00000002B8BE180
C0000000472FA6B0 9 1 library cache 4232 40 SELECT /*+NESTED_TABLE_GET_R... 2.607E+09 C00000002B856300
10 rows selected.
위의 결과에서 주목해야 할 부분은 KSMLRNUM 값이 큰 수치(168, 40)를 보이는
Procedure(168)와 SQL(40)이다.
KSMLRNUM 값이 높다는 것은 이 object의 할당으로 인하여 flush되었던 object
의 갯수가 그 만큼 많다는 것이므로, 이 Procedure 또는 Function은 메모리
에 keep되어질 필요가 있음을 의미한다.
Shared_pool에 Procedure를 Keep하는 방법과 여러 사용자 간에 주로 사용하
는 SQL 문을 공유하기에 관한 자료는 <Bulletin:11776>을 참조하도록 한다.
Reference Documents
-------------------
<Note:61623.1>
<Note:146599.1>
<Note:62143.1>
No. 19876
(V7.X ~ V9.2)예제를 통한 ORA-4031 ERROR 실제 사례의 분석(SHARED POOL)
=====================================================================
Purpose
-------
이 자료는 ORA-4031 에러가 발생하는 여러가지 case 가운데 사이즈가
큰 PL/SQL Routine 또는 Procedure가 메모리에 로드되기 위하여
주로 발생하는 ORA-4031 사례에 대한 예제와 분석을 소개하는 자료이다.
Problem Description
-------------------
Procedure, function, package 등의 library가 shared pool 영역에
할당되려고 할 때 ORA-4031 에러가 발생하는 경우가 있다. 이 때
shared memory를 많이 차지하는 query를 어떻게 추적하는지 사례를
통해 알아보기로 한다.
Workaround
----------
restart instance or flush shared pool
keep large objects in memory
Solution Description
--------------------
SYS.X$KSMLRU 와 SYS.X$KSMSP 는 shared pool memory의 사용 현황을
보여주는 오라클의 base table들이다.
1. SYS.X$KSMLRU
SYS.X$KSMLRU 를 보면
이 fixed table은 shared pool 영역에 cache되기 위해 다른 object를
밀어낸(aged out) allocation들에 대한 정보를 담고 있다.
이 table을 통해 어떤 object가 많은 공간을 메모리에 차지하면서
할당되었는지 알 수 있는데, 한 번 조회하고 나면 조회된 정보는
테이블에서 remove된다.
KSMLRCOM 부분이 'MPCODE'나 'PLSQL%' 로 시작한다면,
큰 사이즈의 PL/SQL object가 shared pool 영역에 load된 것이므로,
이 procedure는 memory에 keep되어지면 좋다는 결론이 나오는데,
SYS.X$KSMLRU 를 조회한 결과를 보아야 한다.
SYS.X$KSMLRU에 만약 아무것도 조회되지 않는다면,
그러니까, 큰 object가 memory에 load되기 위해 다른 object가
aged out된 것은 없다는 것을 의미한다.
이 fixed table의 column에는 다음과 같은 것이 있다.
=================================================================
KSMLRSIZ : allocate된 연속된 memory size.
이 크기가 5K가 넘으면 문제될 소지가 있다고 보고,
10K가 넘으면 심각한 문제가, 20K가 넘으면 매우 심각한
문제를 야기할 수 있으므로 주의가 필요하다.
KSMLRNUM : 이 object의 할당으로 인하여 flush되었던 object의 갯수.
KSMLRHON : load되고 있는 object의 이름.(PL/SQL or a cursor)
KSMLROHV : load되고 있는 object의 hash value.
KSMLRSES : 이 object를 load한 session의 SADDR 값.
=================================================================
2. SYS.X$KSMSP
SYS.X$KSMSP 뷰를 조회하면 shared pool 영역의 free space와 flush할
수 있는 freeable space에 대한 조각이 얼마인지 확인할 수 있다.
ORA-4031 오류가 발생했을 때, V$SGASTAT 뷰를 통해서는 shared
pool 영역의 전체 free space만 확인 가능하지만, 이 뷰를 조회하면
memory space 조각에 대한 정보도 볼 수 있다.
이 fixed table의 column에는 다음과 같은 것이 있다.
(Allocate된 chunk 하나 당 하나의 row가 생성된다.)
=================================================================
KSMCHCLS : CHUNK의 CLASS
(free : free, freeable : freeable, perm : permanent,
recr : recreatable)
KSMCHSIZ : CHUNK의 사이즈
KSMCHCOM : CHUNK에 대한 속성을 나타내는 간단한 text comment
KSMCHPTR : 메모리 상에서 LOCATION에 대한 HEX value
=================================================================
SQL> select ksmchcls, MAX(ksmchsiz), SUM(ksmchsiz)
from sys.x$ksmsp
group by ksmchcls;
KSMCHCLS MAX(KSMCHSIZ) SUM(KSMCHSIZ)
-------- ------------- -------------
R-free 671600 6044400
R-freea 40 720
free 16105472 106453784
freeabl 124176 5391136
perm 15650000 31052280
recr 6496 2052048
6 rows selected.
Example
-------
SQL> select ksmchcls, MAX(ksmchsiz), SUM(ksmchsiz)
from sys.x$ksmsp
group by ksmchcls;
KSMCHCLS MAX(KSMCHSIZ) SUM(KSMCHSIZ)
-------- ------------- -------------
R-free 138716800 139574016
R-freea 8152 236200
free 21712 987208
freeabl 50680 234508992
perm 47020752 53054992
recr 12168 30352488
6 rows selected.
SQL> select * from X$KSMLRU
where KSMLRSIZ > 0;
ADDR INDX INST_ID KSMLRCOM KSMLRSIZ KSMLRNUM KSMLRHON KSMLROHV KSMLRSES
---------------- --------- --------- -------------------- --------- --------- -------------------------------- --------- ----------------
C0000000472FA428 0 1 PAR.C:parchk:page 2120 8 BEGIN PRD_WS_NEXT2( ... 3.325E+09 C00000002B8DA980
C0000000472FA470 1 1 KQLS MEM BLOCK 2288 8 WGQCT 4.034E+09 C00000002B867680
C0000000472FA4B8 2 1 seldef : kkmset 2552 8 SELECT MJCD,fun_aa_nm1(mjcd)... 850201559 C00000002B915F80
C0000000472FA500 3 1 lazdef : kkmset 2568 8 SELECT MJCD,fun_aa_nm1(mjcd)... 265721063 C00000002B8DA980
C0000000472FA548 4 1 lazdef : kkmset 2664 8 select mjnm,mjcd,sum(jg1) j... 1.594E+09 C00000002B85FB00
C0000000472FA590 5 1 idndef : prsexl 3112 3 SELECT /*+ rule */ * FROM sy... 4.285E+09 C00000002B8FF680
C0000000472FA5D8 6 1 BAMIMA: Bam Buffer 3896 8 YYCAT_T1 1.175E+09 C00000002B857600
C0000000472FA620 7 1 state objects 4080 8 0 C00000002B8C9600
C0000000472FA668 8 1 BAMIMA: Bam Buffer 4168 168 BEGIN PRD_WS_NEXT2( ... 4.036E+09 C00000002B8BE180
C0000000472FA6B0 9 1 library cache 4232 40 SELECT /*+NESTED_TABLE_GET_R... 2.607E+09 C00000002B856300
10 rows selected.
위의 결과에서 주목해야 할 부분은 KSMLRNUM 값이 큰 수치(168, 40)를 보이는
Procedure(168)와 SQL(40)이다.
KSMLRNUM 값이 높다는 것은 이 object의 할당으로 인하여 flush되었던 object
의 갯수가 그 만큼 많다는 것이므로, 이 Procedure 또는 Function은 메모리
에 keep되어질 필요가 있음을 의미한다.
Shared_pool에 Procedure를 Keep하는 방법과 여러 사용자 간에 주로 사용하
는 SQL 문을 공유하기에 관한 자료는 <Bulletin:11776>을 참조하도록 한다.
Reference Documents
-------------------
<Note:61623.1>
<Note:146599.1>
<Note:62143.1>
출처 : Tong - exospace님의 Oracle통
 \
\

 관련 자료
관련 자료