OWI를 활용한 shared pool 진단 및 튜닝
아직도 Shared pool 설정에 어려움을 느끼십니까?
작성자 : 한민호(blubeard@nate.com)
필자가 Oracle Internal에 관심을 가지게 된 것은 얼마 되지 않지만 공부를 하면서 이렇게 자료를 만들어 정리를 해보는 것도 좋은 경험이 되고 여러 사람들과 지식을 공유하고 싶었기 때문에 OKM에 기고하게 되었다.
SGA에서 shared pool만큼 사이즈를 설정하기 어려운 Parameter가 없다. 그리고 이 shared pool의 크기는 너무 커도, 너무 작아도 문제가 된다. 즉, 얼마나 적절히 설정하느냐에 따라 DB의 성능을 좌우하게 된다. Parameter만 잘 설정해도 성능이 좋아진다니 이렇게 편하고 좋은 튜닝 방법이 어디 있을까 하는 생각도 든다. 하지만 shared pool의 크기를 아무 지식과 진단 없이 적절히 설정하기란 여간 까다로운 일이 아닐 수 없다. 특히 Row cache와 Library cache는 크기를 각각 설정하는 것이 불가능하기 때문에 초보자에겐 이런 것들이 어려움으로 다가올 수 있다. Shared pool을 자세히 알아 봄으로써 그러한 걱정들을 이번 기회에 덜 수 있다면 훌륭한 DBA가 되는데 도움이 되리라 생각된다. 이에 Shared Pool을 설정함에 있어 진단의 지표로 OWI를 사용할 것이다.
- Wait Event의 중요성
Programming을 해본 사람이라면 동기화 문제에 대해 매우 잘 알고 있을 것이다. Oracle역시 수많은 Transaction에 의해 작업이 되기 때문에 이 때 발생하는 동기화 문제들을 해결하기 위해 수 많은 Latch, Lock, Pin을 사용하고 있다. 이 동기화란 것은 Serial한 작업이기 때문에 성능에 막대한 영향을 주게 된다. Wait Event는 이러한 동기화 작업에 있어서 Critical Section에 들어가지고 못하고 대기하는 작업들의 대기시간 동안 발생하는 이벤트이다. 이 때문에 Wait Event 발생을 줄이는 것은 중요한 일이고 이를 잘 분석하여 Tuning하는 것은 매우 효과적인 방법인 것이다. 그럼 이제 Shared Pool을 Wait Event의 관점에서 진단하고 분석해보기로 하겠다.
- Shared pool의 목적
Shared pool에 대해 간략히 설명을 해보자면 shared pool의 목적은 실행된 Cursor를 공유하여 CPU나 memory를 효율적으로 사용하는 데 있다. Cursor란 SQL의 경우 실행할 때 필요한 실행계획 같은 실행 정보를 담고 있는 SGA상에 할당된 Heap Memory를 말한다. 물론 공유 할 수 있는 것들은 다양하다. 공유할 수 있는 정보들을 나열하자면 SQL구문, 실행계획, PL/SQL소스와 그것들의 실행정보, table, view 같은 object 등이 있다. 이것들을 공유한다면 동일한 PL/SQL이나 SQL을 실행함에 있어 매번 실행계획을 만들며 hard parsing이 일어나는 부하를 예방할 수 있다.
- Shared pool의 구성요소
shared pool을 구성하고 있는 구성요소에 대해 알아보겠다. 우선 shared pool의 구성요소는 4가지로 나뉜다. Process목록, Session목록, Enqueue목록, Transaction목록 등이 할당된 Permanent Area와 SQL문을 수행하는데 필요한 모든 객체 정보를 관리하는 Library cache, dictionary 정보를 관리하는 Row Cache, 그리고 마지막으로 동적 메모리 할당을 위한 공간인 Reserved Area로 나눌 수 있다.
- Heap Manager를 통한 메모리 관리
메모리에 대한 할당 및 해제 작업은 Heap Manager를 통해 동적으로 관리가 된다. 이 Heap Manager에 대해 간략히 알아보면 Top-level의 Heap과 그 하위에 여러 개의 Sub-Heap을 포함하는 구조를 이루고 있다. 이 Heap은 또한 linked list구조의 Extent들로 구성이 되어 있으며 Extent는 여러 개의 chunk로 구성되어있다. 실제적으로 chunk의 사용 현황에 대해 알고 싶다면 X$KSMSP라는 View를 통해 관찰 할 수 있을 것이다.
- Chunk의 관리
Chunk는 4가지 상태로 관리가 된다. 그 4가지 상태는 Free, Recreatable, Freeable, Permanent다. 이러한 chunk들의 상태에 따라 linked list가 구성되는 것이다. 상태의 이름만으로도 그것이 어떤 상태인지 알 수 있을 것이다. 더 정확히 설명 하자면 Free는 즉시 사용 가능한 상태를 말한다. 이 Free 상태의 chunk들로 묶여 있는 linked list가 free list인 것이다. 구체적으로 설명하면 이것은 255개의 bucket이 있고 각 bucket당 free chunk들이 linked list구조로 연결되어있다. 이때 bucket은 각각의 정해진 기준의 크기 이하의 chunk들로만 구성되어 있다. 이러한 이유로 bucket이 아래로 갈수록 chunk들의 크기가 크다. Recreatable은 재생성 가능한 상태이다. 뒤에서 다시 설명하겠지만 이것은 unpinned(현재 사용되고 있지 않은)일 때 재사용이 가능하다. 쉽게 말하자면 이것은 사용이 되었었지만 다시 사용될 확률이 낮아져서 재사용이 가능한 상태가 된 것이며, 현재 사용 중이 아니라면 chunk를 재사용할 수 있도록 이러한 상태의 chunk를 묶어 LRU list로 관리한다. (관련 뷰 : X$KGHLU) 그리고 Freeable은 session이나 call 동안에만 필요한 객체를 저장하고 있는 상태이며 이는 session등이 금방 끊길 수도 있기 때문에 chunk가 필요할 때 할당의 대상이 되지는 못한다. Permanent는 말 그대로 영구적인 객체를 저장하고 있는 상태이며 이것 역시 사용할 수 없는 chunk다.
실제 Heap Dump를 이용하면 R이 앞에 붙어서 상태가 정의 되어 있는 것을 볼 수 있는데 이것은 SHARED_POOL_RESERVED_SIZE란 Parameter를 통해 발생한 chunk들이다. 이 chunk도 적절히 사용하면 매우 중요한 튜닝 요소가 될 수 있다. 이것에 대해 oracle 매뉴얼에서는 PL/SQL block이 많이 사용되는 경우를 예로 들고 있다. 즉, 이것은 large chunk를 위해 할당된 공간인 것이다. Parameter를 정해 주지 않는다면 설정된 shared_pool_size의 5%가 default value로 분류된다. Steve Adams의 Oracle Internal이나 매뉴얼에서도 5000byte 이상의 큰 object를 위한 공간이라고 설명한다. 이는 large chunk가 요구되지 않는다면 굳이 설정할 필요가 없다는 말도 되는 것이다. 이러한 튜닝 요소에 초점을 맞추어 설정하면 되는 parameter인 것이다. 이것들 역시 linked list로 관리되며 명칭은 Reserved Free list라고 부른다.
(아래 그림 1을 참조한다면 이해하는 데에 도움이 될 것이다.)
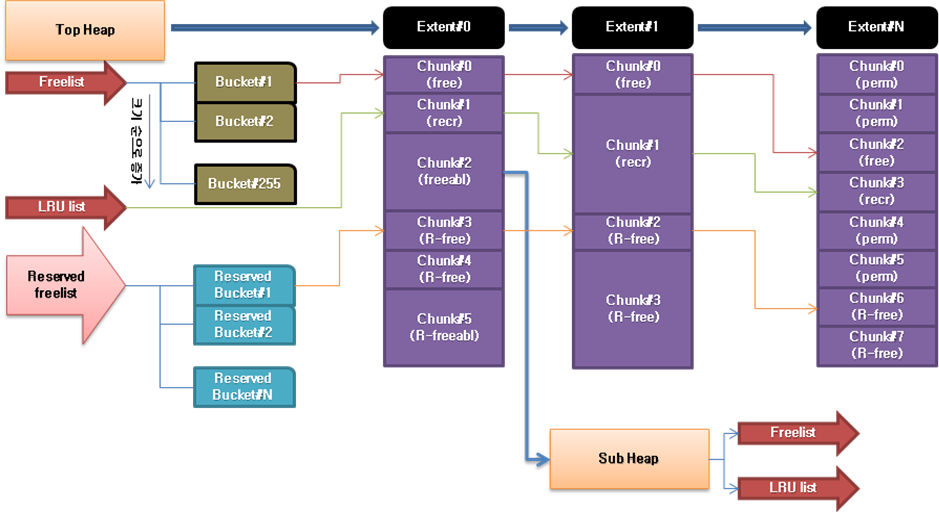
[그림 1] Shared Pool Heap 구조(출처 : Advanced OWI in Oracle 10g / ㈜엑셈)
정리를 해보자면 chunk는 사용할 수 있는 것과 없는 것으로 나눌 수 있다. 그 중에 실제 chunk 할당 과정에서 latch경합을 벌여 Wait Event가 발생하기 때문에 free list와 LRU list에서 관리되고 있는 chunk들에 주목을 할 필요가 있을 것이다. 왜냐하면 운영 시 peak time때의 할당된 chunk의 총 크기가 곧 shared pool의 size를 적절히 결정하는 데에 중요한 역할을 하기 때문이다. 이것에 대한 설명은 Wait Event의 발생과 연관 지어 이야기 해 보겠다.
- Shared Pool의 관리
Chunk를 할당하는 과정에서 반드시 필요한 것이 shared pool latch의 획득이다. 하지만 이러한 shared pool latch는 아쉽게도 shared pool당 단 1개 밖에 존재하지 않는다. 이것은 즉, chunk를 동시에 할당 받아야 할 상황이라면 이것을 획득하는 과정에서 경합을 벌이게 된다는 의미이다. 무엇 때문에 이렇게 shared pool latch 수를 적게 만들어 놓았는지 정확히 알 수는 없지만 여러 개를 만들어 놓았다면 역시나 동기화 문제를 관리하는데 있어 어려움이 있기 때문이 아닐까 싶다. 다행히도 Oracle 9i부터는 Hidden Parameter인 _KGHDSIDX_COUNT를 이용하여 하나의 shared Pool을 7개까지의 Sub-Pool로 나누어 관리하는 것이 가능해졌다. 그리고 더 반가운 소식은 각각의 Sub-pool당 독자적인 free list, LRU list, shared pool latch를 가짐으로 인해 부족했던 자원에 대한 경합을 그나마 감소시킬 수 있게 되었다. 그러나 경합은 감소했을지 몰라도 CPU의 개수나 SHARED_POOL_SIZE가 충분히 크지 않다면 ORA-4031에러의 발생위험이 1개의 shared pool로 관리됐을 때보다 더 높다는 것이다. 그래서 권장하는 방법이 CPU 4개에 SHARED_POOL_SIZE가 250m이상일 때 Sub-pool을 사용하는 것이다. 한 때는 하나의 Sub-pool에 할당 가능한 chunk공간이 없으면 다른 Sub-pool에 사용 가능한 free chunk가 있음에도 찾지 못했던 버그도 있었다. shared pool latch에 대해 좀 더 알아보자면 실제적으로 shared pool latch를 소유하는 시간이 shared pool latch를 대기하게 하는 중요한 이유이다. 때문에 latch를 획득한 후에 일어나는 작업들을 알면 경합의 포인트를 알 수 있을 것이다.
- Chunk의 할당과정
Shared pool latch를 획득하게 되면 우선 free chunk를 찾기 위해 free list를 탐색한다. 그리고 적절한 free chunk가 있다면 할당을 받지만 없다면 LRU list를 탐색하게 된다. 이것마저도 찾지 못한다면 Reserved Free List를 탐색하고 이것 역시 실패하면 Spare Free Memory를 탐색하게 된다. 이 모든 과정이 실패가 되었을 때 ORA-4031에러가 발생하게 되는 것이다. 이 과정에서 할당을 받게 된다면 딱 필요한 크기만 할당을 받고(split) 나머지는 다시 free list에 등록이 되기 때문에 free list가 할당이 된다고 해서 반드시 짧아지는 것은 아니다. 그리고 적절한 chunk를 찾기 위해 위에서와 같이 여러 과정은 거치지만 이 과정은 생각보다 매우 빠른 시간 안에 이루어진다. 하지만 이것들이 다수의 작업이 된다면 경합에 대한 wait time은 피부로 느껴질 것이다. 여기서 이제껏 언급이 없었던 Spare Free Memory에 대해 궁금해하는 분이 많을 꺼 같아 간단하게 설명하자면(이 내용은 Steve Adams의 Oracle Internal에 내용이 있다) instance가 start up 되었을 때 shared pool size에 정해진 크기의 절반만이 shared pool에 할당된다. 이것은 성능을 극대화 하는데 에도 연관이 있으리란 생각이 든다. Chunk의 수가 줄면 그 만큼 free list가 짧아지기 때문에 그에 대한 탐색시간도 짧아지고 shared pool latch의 소유 시간 역시 짧아지기 때문에 메모리를 숨겨놓지 않았을까 생각된다. 위의 과정들을 미루어 짐작해볼 때 shared pool latch의 소유시간은 free list의 길이와 얼마나 빨리 적절한 chunk를 찾느냐에 따라서 결정된 다는 것을 알 수 있을 것이다. 그럼 free list의 길이가 길어지는 것은 어떠한 경우 일까? 바로 그것은 chunk split가 다량으로 발생하여 단편화(fragmentation) 되었을 때이다. 이러한 경우 free list의 길이가 길어지게 되는 것이다. 단편화는 hard parsing에서 일어나는 것인데 hard parsing에 대해 모르는 독자들을 위하여 간단히 설명하면 처음 실행하는 SQL문이 있다면 이것에 대한 실행정보를 저장하고 있는 Heap Memory 할당이 필요한데 이 Heap이 바로 chunk인 것이다. 이러한 실행계획을 만들고 chunk에 할당하는 과정은 매우 부하가 있기 때문에 hard parsing이라고 이름 붙여진 것이다. 이런 과도한 단편화로 인해 shared pool latch의 경합만 가중 시키는 것이 아니다. 큰 chunk 할당이 요구되는 hard parsing이 이루어 질 때 적절한 free chunk를 찾지 못하여 ORA-4031에러를 유발하게 된다.
- Shared Pool Size 설정
지금까지 설명했던 것들을 가지고 shared pool size에 대해 결론을 내 보면, 첫째로, memory가 무조건 크다는 생각으로 shared pool을 늘리면 안 된다고 볼 수 있다. 이것은 오히려 free list의 길이만 늘어나게 되기 때문이다. 그리고 V$SGASTAT를 통해 확인한 shared pool의 free memory가 작다고 해서 SHARED_POOL_SIZE를 늘려서는 안 된다. Free memory는 단지 free chunk의 합이기 때문이다. 이는 즉 LRU list, reserved list, spare memory도 있기 때문에 크게 문제가 되는 것은 아니라는 말이다. 지금까지 설명한 것을 고려해 본다면 적절한 크기를 정하는 데는 매우 도움이 될 것이다. 만약 초보 DBA라면 Oracle에서 제공하는 advice를 이용하는 것도 괜찮은 방법일 듯싶다. OEM구성을 하여 Enterprise Manager를 보면 memory tab에서 shared pool 부분의 advice버튼만 클릭하면 적절한 shared pool 크기에 대한 지침을 제공하고 있다.(그림 2를 참조하시오) 이것이 아주 정확한 척도가 되지는 못할지라도 초보 DBA에게는 매우 매력 있는 기능임에는 틀림이 없다. 이 지침은 되도록이면 peak time 이후에 이용하는 것을 권장한다.
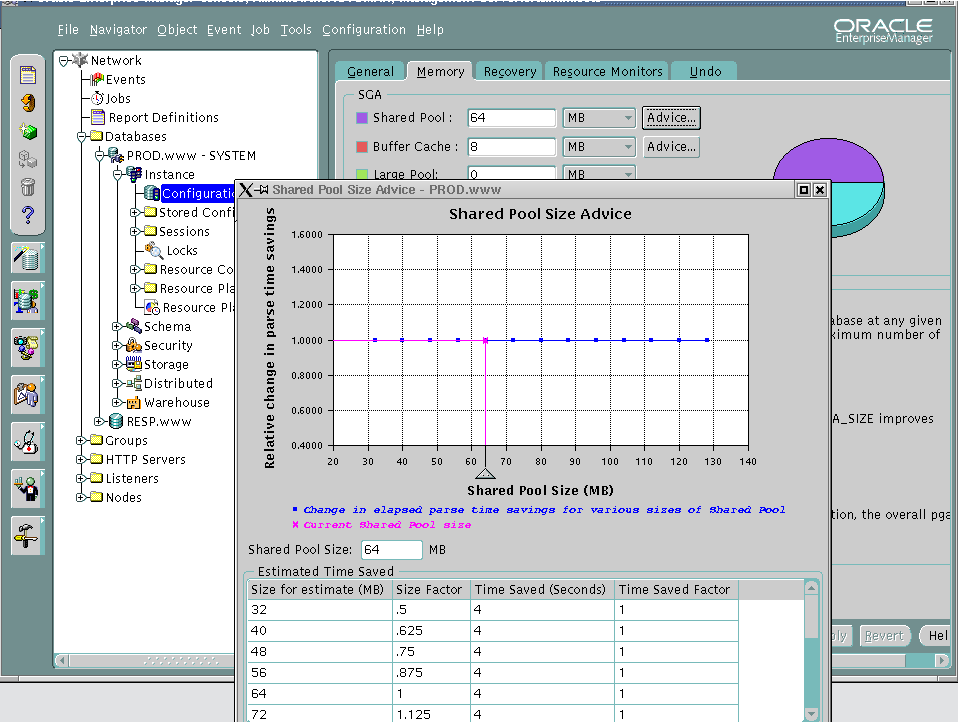 \
\
[그림 2] Enterprise Manager의 Shared pool advice
Shared Pool Size를 적절히 줄이게 되면 free list 탐색시간의 감소로 인해 hard parsing에 의한shared pool latch의 경합을 줄이는 효과를 볼 수 있지만 ORA-4031에러의 위험이나 상주할 수 있는 공유 객체의 수가 줄어들어 LRU list를 자주 이용하기 때문에 오히려 부가적인 hard parsing을 발생시킬 수 있음에 유의해야 한다. 이때 오르내리는 객체가 프로시저나 패키지라면 그 부하는 상당할 것이다. 이에 대비하여 DBMS_SHARED_POOL.KEEP을 이용하여 메모리에 고정시키는 방법도 매우 유용하다. Shared pool을 flush해도 내려가지 않기 때문이다. Shared pool latch가 발생하는 것을 가장 줄일 수 있는 방법은 bind변수의 사용이나 CURSOR_SHARING Parameter를 설정하는 것이다. CURSOR_SHARING parameter는 SQL문장을 자동으로 bind변수치환을 해주는 변수이다. 위에서 언급했던 Flush Shared pool에 대하여 잠시 설명을 하고 가면 alter system flush shared_pool;이란 명령을 통해 shared pool을 flush 시킬 수 있다. 이 작업은 단편화된 free chunk에 대해 coalesce 작업이 이루어 지기 때문에 유용하지만 NOCACHE 옵션이 없는 sequence가 있다면 예상치 못한 gap이 생길 수도 있기 때문에 유의해야 한다.
- Library Cache Latch와 Shared Pool Latch의 관계
Shared pool을 튜닝 하는데 있어 반드시 shared pool latch 획득만이 문제가 되는 것은 아니다. 바로 shared pool latch 획득 이전에 library cache latch의 획득이 먼저 있기 때문이다. 이것을 비롯한 parsing에 대해 좀더 이해를 돕기 위해 아래의 그림 3을 참조하기 바란다.
|
작업 |
Hard Parsing |
Soft Parsing |
|
Syntax, Semantic, 권한체크 |
∨ |
∨ |
|
Library cache latch 획득 |
∨ |
∨ |
|
Library cache 탐색 |
∨ |
∨ |
|
LCO가 있다면 Library cache latch 해제 |
|
∨ |
|
Shared Pool latch 획득 |
∨ |
|
|
할당 가능한 Chunk탐색 및 Chunk할당 |
∨ |
|
|
Shared Pool latch 해제 |
∨ |
|
|
Parse Tree 및 Execution Plan 생성 |
∨ |
|
[그림 3] parsing시 shared pool latch와 library cache latch
그림 3를 보면 알 수 있듯이 hard parsing이 soft parsing 보단 부하가 큰 작업 임을 알 수 있다. 또한 library cache latch와 shared pool latch 획득 시점을 미루어 보아 동시에 많은 세션이 library cache latch를 획득하려고 하게 되면 이것에 대한 병목 현상으로 shared pool latch에 대한 경합은 상대적으로 줄어들 수 있을 것이란 예상도 가능하다. 그렇다면 이렇게 shared pool latch에 영향을 주는 library cache latch에 대해서도 자세히 알아볼 것이다.
- Library Cache의 구조와 관리
Library cache에 할당 받는 Heap memory는 shared pool latch를 걸고 할당 받은 free chunk이다. 이때 Library Cache Manager(KGL)에 의해 관리되는데 이는 내부적으로 Heap Manager(KGH)를 이용하는 것이다. 이때 할당된 free chunk는 LCO(Library Cache Object)와 handle을 저장하는데 사용된다. Library Cache Memory는 크게 hash function, bucket, handle list, LCO로 구성되어 있다. 하나씩 설명을 해보면 hash function은 bucket을 결정하기 위한 연산을 수행하는 함수로 보면 된다. 객체에 따라 SQL의 경우 SQL TEXT를 그대로 numeric 값으로 변환하여 bucket을 결정하고 SQL외의 객체들은 schema, object name, DB link를 numeric 값으로 변환하여 bucket을 결정한다. Bucket의 성장은 LCO의 크기가 매우 많아져서 성장이 불가피할 때 성장하게 되는데 이때 대략 2배 크기의 소수로 확장하게 된다. 그리고 bucket의 초기 값은 _KGL_BUCKET_COUNT로 설정이 가능하다.
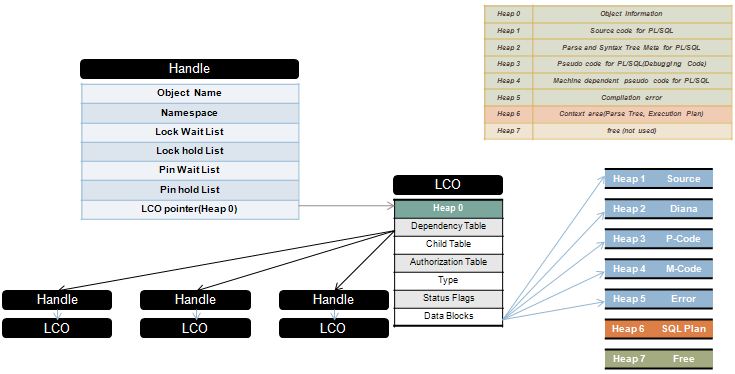
아래 그림 4, 5는 필자가 그린 handle과 LCO의 구조, 그리고 그것에 대한 간략한 설명이다.
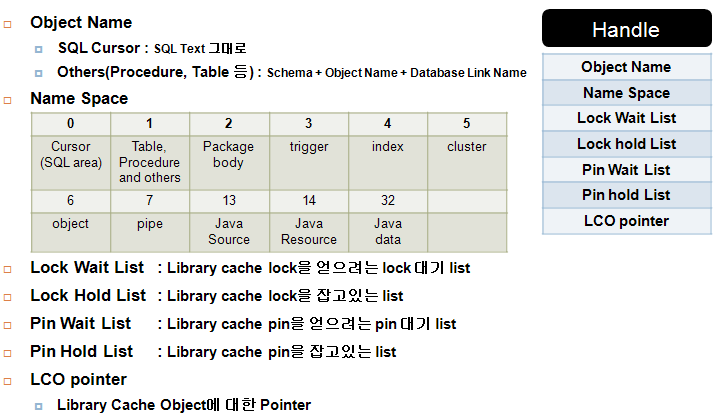
[그림 4] Handle의 구조

[그림 5] LCO의 구조
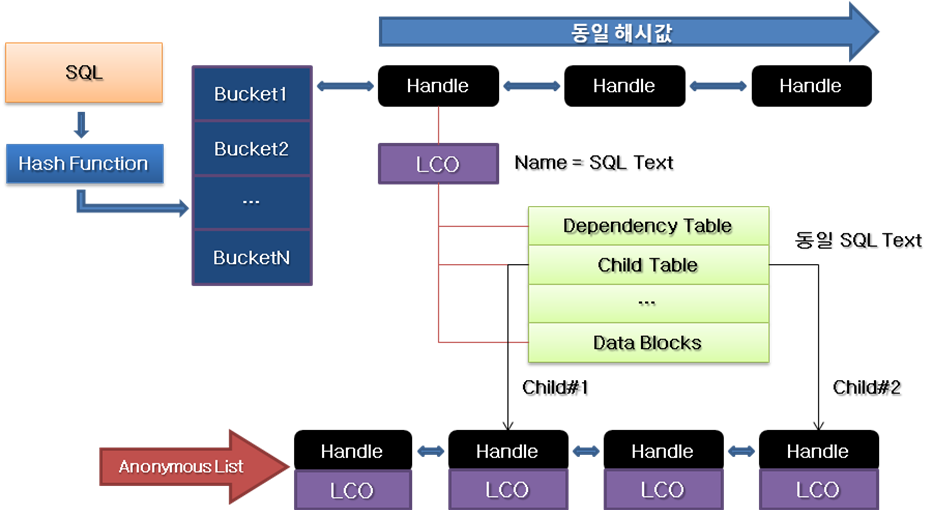
[그림 6] Library cache 구조 (출처 : Advanced OWI in Oracle 10g / ㈜엑셈)
위의 그림 4, 5를 숙지하였다면 handle이 무엇이고 LCO가 무엇인지, 또 이것이 저장하는 정보에 대하여 알 수 있었을 것이라고 예상 된다. 이제 그림 6을 보면 대략적인 구조가 머리 속에 들어 올 것이다. 여기서 특징적인 것은 SQL의 경우 child table을 갖는 다는 점이고 그 child table이 저장하고 있는 실제적 자식 handle과 LCO는 익명 리스트로 관리되고 있다는 점이다. 물론 PL/SQL의 경우는 조금 다르다. 이것의 구조는 그림 7,8을 보면 좀더 명확히 알 수 있다.
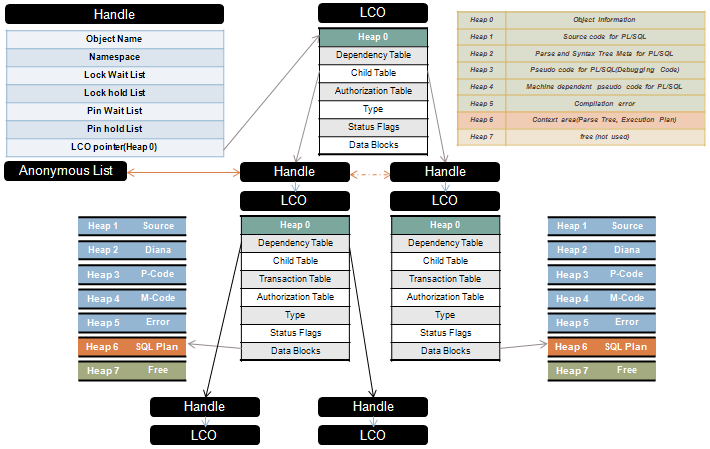
[그림 7] SQL의 LCO구조
[그림 8] PL/SQL의 LCO구조
PL/SQL과 일반 SQL은 Heap Memory를 사용하는데 있어서도 차이점이 있다는 것을 금방 알 수 있을 것이다.
- Oracle의 놀라운 메커니즘 Invalidation 자동화
Oracle의 장점 중 하나인 invalidation 자동화에 대해 잠시 설명을 해 보겠다. 이에 대한 내용이 자세히 언급된 곳은 많지 않았을 것이다. 우선 그림 7을 보면 SQL LCO의 구조에 대해 잘 보여주고 있다. Parent LCO와 두 개의 child LCO가 보일 것이다. 보통 이런 방식으로 저장되는 경우는 각각 다른 schema에 같은 이름의 table을 가지고 있을 때 동일한 SQL을 query할 수 있을 것이다. 쉽게 예를 들면 scott1과 scott2란 두 user가 있는데 이들이 각각 emp라는 table을 가지고 있고 select * from emp;라는 동일한 query를 두 user가 전송했을 때 이러한 구조로 LCO가 생성되게 되는 것이다.
이때 child LCO의 Dependency Table에는 scott1의 경우 scott1.emp table의 LCO를 참조하고 cott2의 경우 scott2.emp table의 LCO를 참조하게 되는 것이다.
이 참조 과정에서 handle의 lock hold/wait list, pin hold/wait list를 이용하게 된다. 이때 중요한 것이 바로 lock이다. 참조하는 LCO의 lock을 shared mode로 잡아 사용하고 해제하는 것이 아니라 null mode로 유지하는 것이다. 이것이 바로 나중에 참조하는 table이 변경되었을 때 이 lock list를 없애 버림으로 인해 SQL Cursor(select * from emp;)를 따로 어떤 프로세스를 통해 invalidation한 상태로 만들지 않고 자동으로 invalidation하게 하는 것이다.
- Library cache에서 발생하는 Wait Event 소개
그럼 이제는 library cache에서 발생하는 주요 Wait Event들에 대해 알아보자. library cache에서 일어나는 자주 발생하는 Wait Event에는 3가지가 있다. 그것은 latch:library cache, library cache lock event, library cache pin event이다. 이것은 명칭에서도 알 수 있듯이 latch, lock, pin을 소유하기 위해 대기하는 event 이다. 이 동기화 자원들에 대하여 자세히 알아보자.
- Library Cache Latch
우선 library cache latch에 대해 알아보면 이 latch는 library cache 영역을 탐색하고 관리하는 모든 작업을 보호하는 데에 그 목적이 있다. Latch의 수는 일반적으로 shared pool latch의 수 보다는 많다. 왜냐하면 CPU개수보다 큰 소수 중 가장 작은 소수로 설정되어 있기 때문이다. 이 때문에 library cache latch를 획득하려는 프로세스가 CPU개수 보다 적다면 library cache latch 자원은 손쉽게 획득하는 대신에 shared pool latch를 가지고 경합할 확률이 높을 것이고 library cache latch의 개수보다 많은 프로세스가 획득하려 한다면 library cache latch를 가지고 경합을 하느라 shared pool latch의 경합은 상대적으로 줄어들 수 있다. 그렇다면 이러한 library cache latch 경합을 가중시키는 작업엔 어떤 것이 있을까? 바로 hard parsing이나 soft parsing이 과다한 경우와 자식 LCO가 많아 anonymous list의 탐색시간이 증가하는 경우이다. 그리고 SGA영역이 page out되는 극히 드문 경우를 예로 들어 볼 수 있다. 이에 대한 해결 책으로 PL/SQL block 내에서 자주 실행되는 SQL에 대해서는 Static SQL을 사용하면 된다.(Dynamic SQL은 안됨) LCO를 pin하여 soft parsing 없이도 cursor를 계속 재사용 할 수 있는 효과를 볼 수 있다.
그리고 SESSION_CACHED_CURSORS Parameter를 이용하여 3회 이상 수행된 SQL에 대해서는 PGA영역에 cursor의 주소 값과 SQL text를 저장하여 cursor 탐색 시 성능향상을 기대할 수 있다.(library cache latch도 획득해야 하고 soft parsing도 발생하지만 library 탐색시간이 매우 짧기 때문에 성능향상이 된다.) 하지만 application에서 SQL 수행 시 마다 log on/off하는 경우 이 parameter는 세션이 끊어지면 소용이 없기 때문에 성능 향상을 기대하기 어렵다. 때문에 connection pool을 함께 이용하는 것이 현명한 방법이다. 그리고 마지막으로 SGA영역의 page out의 경우는 잘 발생하지 않지만 만약을 대비해서 LOCK_SGA값을 TRUE로 하여 고정시켜 놓는 것이 좋다.
- Library Cache Lock
Library cache lock(관련 뷰 : X$KGLLK, 10g-DBA_DDL_LOCKS, DBA_KGLLOCK)에 대해 설명하면 이것은 handle에 대해 획득하는 lock이라 볼 수 있다. 이것의 목적은 동일 object의 접근 및 수정에 대해 다른 client들로부터 예방하는 것이다. Lock은 세가지 모드를 갖게 되는데 shared, exclusive, null mode가 있다. Shared로 획득하는 경우는 parsing과 실행단계이고 exclusive는 procedure 생성이나 변경의 경우, recompile시와 table 변경의 경우가 있다. 보통 참조하는 LCO에 대해 exclusive모드와 shared모드로 각각 획득하려는 경합으로 인해 waiting이 발생하게 된다. null mode는 보통 실행 후에 참조하는 객체에 대해 null mode로 lock을 소유하게 된다.
- Library Cache Pin
마지막으로 library cache pin(관련 뷰 : X$KGLPN, 10g-DBA_KGLLOCK)에 대해 설명하면 Heap data에 pin을 꽂아 변경되지 않도록 보장하는데 그 목적이 있다. 이것은 반드시 library cache lock을 획득한 후에 획득해야 한다. 이것은 shared와 exclusive 두 mode가 지원되며 이렇게 획득하는 경우를 살펴보면, shared mode로 획득하는 경우는 Heap Data를 읽을 때 pin을 걸어 object들의 변경을 예방하며 exclusive mode로 획득하는 경우는 Heap Data를 수정할 때이다. Heap data를 수정하는 경우는 procedure recompile이나 hard parsing 발생 시 execution plan을 세우는 과정에서 참조하는 LCO가 변경되면 안되기 때문에 pin을 걸어 보호한다.
이때 발생하는 library cache lock이나 library cache pin은 V$SESSION_WAIT의 P1, P2, P3 column과 X$KGLOB View를 이용하여 object 정보를 구할 수 있다. P1=handle address, P2=lock address, P3=mode*100+namespace (lock mode : 1=null, 2=shared, 3=exclusive)이기 때문에 V$SESSION_WAIT을 조회하여 P1값을 구한 후 P1과 X$KGLOB의 kglhdadr column과 비교하여 kglnaobj column을 query해서 object의 이름을 구할 수 있다.
- 맺음말
위의 library caches에 관한 내용들을 종합적으로 정리해서 결론을 내려보면 Wait Event를 통해 그 Event가 왜 발생하였는가를 인지할 수 있다면 정확한 진단 역시 가능함을 알 수 있다. 그리고 덧붙여 내부적인 Event의 발생과정을 아는 것이 튜닝을 하게 될 때 넓은 시야를 가질 수 있도록 도와주고 좀더 효율적이고 정확한 튜닝을 할 수 있는 계기가 되리라 확신한다.
참고자료
OWI를 활용한 오라클 진단 & 튜닝 / ㈜엑셈 역
Advanced Oracle Wait Interface in 10g / 저자 조동욱 / ㈜엑셈
Oracle 8i Internal Services for Waits, Latches, Locks, and Memory / Steve Adams / O’Reilly
Manual
Oracle Database Concepts 10g R2
Oracle Database Reference 10g R2
Oracle Database Performance Tuning Guide 10g R2'ORACLE > TUNING' 카테고리의 다른 글
| SGA/PGA 튜닝 시 고려(검토)할 오라클 factor (0) | 2011.12.16 |
|---|---|
| SHARED POOL SIZE의 계산방법 (0) | 2011.11.23 |
| Oracle Session별 Trace 생성 방법 (0) | 2011.10.21 |
| SQL TRACE (0) | 2011.10.21 |
| [SQL튜닝] 오라클 CPU 많이 차지하는 쿼리 찾기 (0) | 2011.03.28 |
