출처 : http://scidb.tistory.com/entry/%EC%98%A4%EB%A0%8C%EC%A7%80%EB%82%98-TOAD%EC%97%90%EC%84%9C-Predicate-Information%EC%9D%84-%EC%B0%B8%EC%A1%B0%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
지인으로부터 아래와 같은 질문을 받았다.
질문 : Predicate Information을 참조하려면 DBMS_XPLAN 패키지를 사용해야만 합니까?
저희 개발자들은 DBMS_XPLAN 패키지를 사용할 권한이 없습니다.
따라서 오렌지나 TOAD에서 간단히 볼 수 있는 방법이 필요합니다. 가능 합니까?
답변 : 볼 수 있습니다. 단 PLAN_TABLE을 볼수 있는 권한은 있어야 합니다.
요청: 그건 있습니다. 방법을 블로그에 올려주시면 나머지 사람들도 볼수 있겠네요. 올려주시죠.
이렇게 해서 이글을 작성 하게 되었다. 이런 질문을 받았다는 것은 2가지 의미로 해석할 수 있다. 첫번째, 의외로 오렌지나 TOAD의 기능을 모르는 사람이 많이 있을 수 있다는 의미다. 두번째, 튜닝에 필요한 권한이 개발자에게 없다는 안타까움 이다. 이 정책은 매우 아쉬운 선택이며 앞으로 개선되기를 기대해본다. 하지만 수정이 필요한 법이나 악법도 법이므로 수정되기 전까진 따라야 한다.
Predicate Information과 관련된 가장 흔한 오류는 10046 이벤트 + tkprof를 사용하면 Predicate Information을 볼수 있다고 착각 하는 것이다. 절대 볼수 없다.
Predicate Information이 뭐지?
Predicate Information이란 인덱스 scan 시의 컬럼 액세스 정보, 조인정보, filter 정보를 각 Opreation 단위로 나타낸 것이다. 아래의 예제를 보자.
explain plan for
SELECT /*+ LEADING(e) USE_NL(d) */
e.employee_id, e.first_name, e.last_name, e.email, e.salary
FROM employee e, department d
WHERE e.department_id = d.department_id
AND e.job_id = 'SH_CLERK';
select * from table(dbms_xplan.display);
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 860 | 3 (0)|
|* 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEE | 20 | 860 | 3 (0)|
|* 2 | INDEX RANGE SCAN | EMP_JOB_IX | 20 | | 1 (0)|
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("E"."DEPARTMENT_ID" IS NOT NULL) --> FILER 정보가 출력됨
2 - access("E"."JOB_ID"='SH_CLERK') --> INDEX SCAN 정보 혹은 JOIN 정보가 출력됨
FILTER와 ACCESS 정보는 중요하다
위에서 출력된 Predicate Information을 보면 FILTER 와 INDEX SCAN 정보를 정확히 볼 수 있다. 특히 인덱스가 여러 개의 컬럼으로 구성된 경우 몇 번째 컬럼까지 액세스 되었는지 보려면 Predicate Information이 필수적인 것이다. 예를 들어 인덱스가 COL1 + COL2 + COL3로 되어 있는데 Predicate Information에서 INDEX를 SCAN에 사용된 컬럼이 하나뿐이고 COL2와 COL3는 테이블의 FILTER로 풀린다면 성능에 문제가 될 수 있다. 따라서 Predicate Information을 확인 하는 것은 매우 중요한 것이다.
문제는 이처럼 중요한 정보를 DBMS_XPLAN 패키지를 사용하지 않고 'TOAD나 오렌지에서 어떻게 볼수 있냐' 이다.
지금부터 따라 해보기 바란다.
1. TOAD에서 Predicate Information 보기
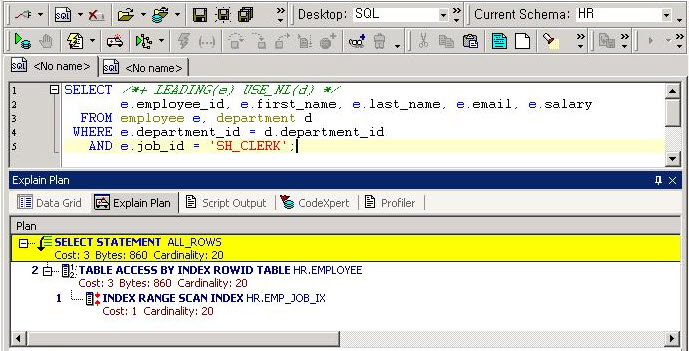
그러면 위와 같은 화면이 출력될 것이다. 위의 화면에서는 Predicate Information가 없다. 지금부터 Predicate Information을 추가해보자.
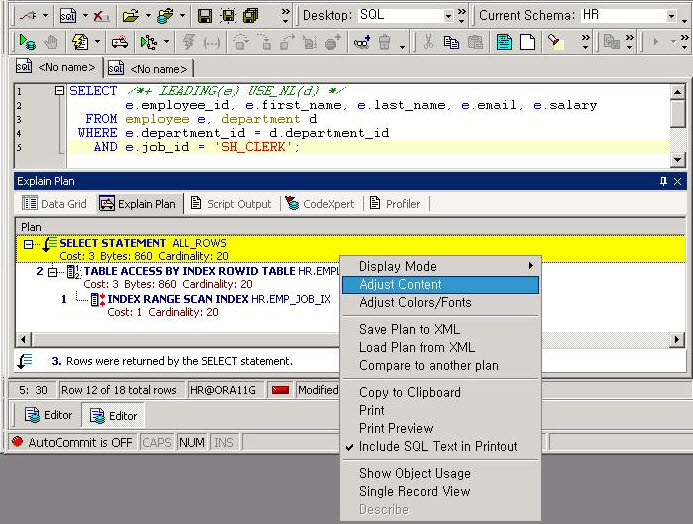
먼저 TOAD 화면의 하단(Explain Plan) 탭에서 오른쪽 버튼을 클릭한다. 연이어 Adjust Content를 선택한다.
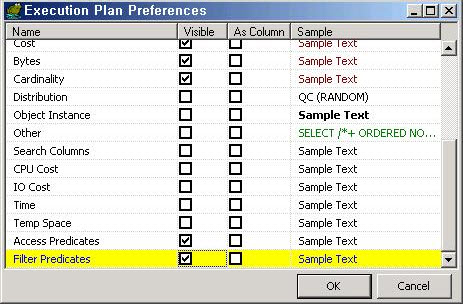
그러면 위와 같은 화면이 뜨는데 여기서 Access Predicates와 Filter Predicates의 Visible 항목을 체크하고 OK를 클릭한다.
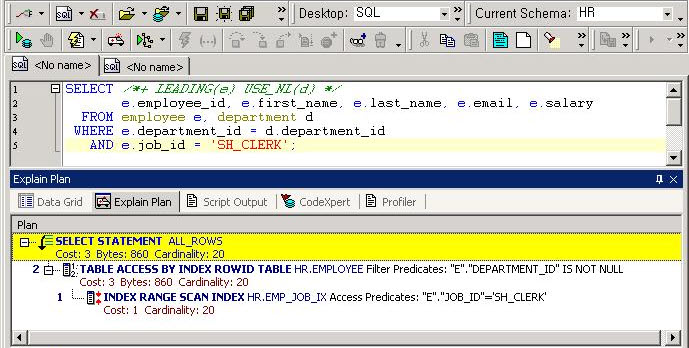
위와 같이 TOAD에서 Access Predicates와 Filter Predicates가 깔끔하게 출력되었다.
2. 오렌지에서 Predicate Information 보기
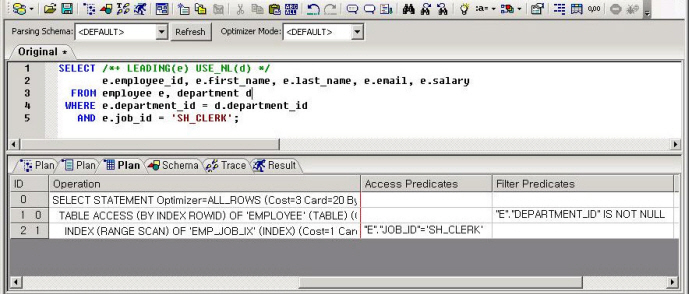
확인하는 습관이 필요해
이로써 어디서든 무엇을 사용하든 버튼 클릭 만으로 Predicate Information을 볼 수 있게 되었다. 이제부터 Predicate Information을 애용하기 바란다. 특히 Index Scan 시에 몇번째 컬럼까지 이용하였는지 확인하는 습관이 필요하다.
PS :
필자는 TOAD나 오렌지의 제조사나 판매사와는 상관없는 사람이다. 단지 가끔 이용할 뿐...
'ORACLE > ORACLE TOOL' 카테고리의 다른 글
| Orange-국내 기술로 개발된 오라클 개발 지원 및 튜닝 도구 (0) | 2009.11.23 |
|---|---|
| SQL * Plus 명령어 & 환경 시스템 변수 (0) | 2009.09.04 |
| Toad 에서 null 값 노란색으로 표시하기 (0) | 2009.08.21 |
| Oracle DB로 보는 데이터베이스 인터페이스의 발전 (0) | 2009.07.10 |
| toad 에서 explain plan 보기 (1) | 2009.03.27 |


































