Toad를 이용한 DB튜닝방법
DBA에게 유용한 Toad의 숨은 기능 찾기
박중수 | 엔커블루 기술본부 대표 컨설턴트
기업에서의 데이터 증가는 기하급수적으로 늘어나고 있으며 그에 따른 데이터베이스 성능도 대용량을 처리할 수 있도록 발전하고 있다. 따라서 데이터베이스 관리자는 예전과 달리 데이터베이스의 운영을 매뉴얼하게 할 수 있는 상태에 직면해 있으며, 자동화된 모니터링 및 Alert!s로 안정적인 서비스에 대응할 수 있는 툴을 원하고 있다. 이러한 요구사항을 위한 토드의 GUI 환경에서의 데이터베이스 모니터링 기능을 살펴보자.
데이터베이스 개발에 있어 토드(Toad)를 사용하는 사람들은 일반적으로 “토드는 개발자들을 위한 개발 툴”이란 생각을 많이 한다. 즉 단순히 SQL 문장이나 PL/SQL 문장을 빠르고 쉽게 개발할 수 있고, 데이터베이스 객체의 생성 및 변경 작업을 GUI 환경에서 간단하게 수행하며 소스코드 상의 문제점들을 자동으로 찾아주고, 디버깅 기능을 통해 개발자들의 수고를 덜어 줄 수 있는 툴 정도로만 인식하고 있는 것이다. 하지만 토드를 좀 더 세밀하게 들여다보면 개발자만을 위한 툴이 아닌 데이터베이스를 관리(management)하는 DBA(Database Administrator)가 사용할 수 있는 다양한 기능들이 숨겨져 있다. 이 글에서는 토드에 숨겨진 유용한 기능에 대해 소개하고자 한다.
DBA의 역할은 무엇일까?
DBA는 현재 운영되고 있는 시스템, 데이터베이스, 애플리케이션, 네트워크, 서비스 등의 다양한 환경을 구성하고 설치, 보안, 운영 및 설계나 개발 단계에 직, 간접적으로 참여해 전체 구성이 원활하게 유지되도록 하는 업무를 담당하고 있다.
이러한 업무를 수행하다 보면 원하는 서비스가 제대로 동작하지 못하고 특정 부분에 대한 장애가 발생하거나 알 수 없는 그 무엇인가에 의해 성능이 원하는 만큼 나오지 않을 경우도 있다. 특히 DBA에게 내·외적 요소에 의한 뜻하지 않는 돌발상황으로 인해 소비되는 시간이나 노력은 가장 큰 부담이다. 이럴 경우 DBA는 누군가가 현재의 시스템이나 데이터베이스의 부하 없이 효율적으로 문제점을 찾아내어 원인 파악을 해주고 문제점을 해결할 방법을 제시해 준다면 하늘로 날아갈 것 같은 기분을 느낄 것이다.
실제 DBA들은 이로 인해 발생하는 비용을 최소화하기 위해 툴을 사용한다. 하지만 문제점을 감지하는 툴, 문제점을 분석하는 툴, 문제점을 해결하는 툴에 이르기까지 다양한 툴 도입에 따라 발생하는 비용 부담과 함께 툴을 효과적으로 사용하고 있는가를 생각해보면 힘이 빠질 수밖에 없다.
이 글에서는 툴을 효과적으로 사용할 수 있는 정보를 제공하기 위해 가장 널리 사용되는 토드라는 데이터베이스 개발 툴을 선택했다. 특히 토드는 개발 툴 위주로 개발이 됐지만 ‘DBA 모듈’이라는 옵션 기능이 있어 토드 하나만 갖고도 데이터베이스를 최적의 상태로 유지할 수 있는 기능이 있다. 물론 전문적으로 감지·분석·해결에 초점을 맞춘 방대한 툴과의 비교는 어렵겠지만 그래도 적은 비용으로 문제를 해결할 수 있는 솔루션이 있다면 좋지 않겠는가.
DB의 문제점을 발견하라!
토드를 구입했다고 해서 DBA 기능을 전부 사용할 수 있는 것은 아니다(‘토드 DBA 모듈’은 옵션 제품이다). 제품을 구입할 당시에 DBA 모듈이라는 제품을 추가적으로 구입해야 사용이 가능하다. 하지만 개발 위주의 작업이 아닌 전사적인 방법으로 토드를 사용할 것이라면 추천할 만한 사항이라고 생각한다. 그러면 자신이 사용하고 있는 토드를 갖고 이 DBA 기능을 어떻게 사용할 수 있을까?
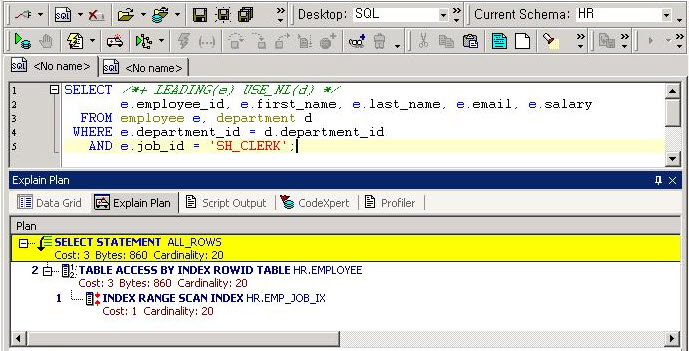
확인할 수 있는 가장 간단한 방법은 토드의 메인 메뉴 중에서 DBA 메뉴를 클릭해 보면 그 아래 리스트가 길게 나와 있느냐 짧게 나와 있느냐에 따라 확인할 수 있다. <화면 1>처럼 길게 리스트가 나온다면 DBA의 기능을 최적의 상태에서 사용할 수 있다는 뜻이다. 그럼 토드의 DBA 기능을 Detect, Diagnostic, Resolve라는 3개의 단계에 초점을 맞추어 살펴보자.
<화면 1> DBA 메뉴

데이터베이스에 문제가 발생하면 DBA는 일단 원인부터 파악한다. 하지만 어느 부분이 문제가 있는지를 감지하기란 사막에서 모래알을 찾는 것만큼 어려운 일이다. 토드에서 지원하고 있는 DBA 기능 중에서 데이터베이스 모니터(Database Monitor), 헬쓰 체크(Health Check), 인스턴스 매니저(Instance Manager)를 통해 현재의 데이터베이스 상태를 감지할 수 있다.
데이터베이스 모니터
우선 데이터베이스 운영자는 데이터베이스의 성능을 높이기 위해 물리적인 I/O의 병목현상을 제거함으로써 시스템의 메모리와 CPU 자원의 경합을 줄이며 안정적인 서비스를 제공할 수 있다. 그리고 데이터베이스 운영자는 각 세션들에서 발생되는 Wait Event(네트워크 통신이나 I/O 요청 또는 데이터베이스의 특정 자원을 여러 프로세스가 동시에 액세스할 때 발생하는 경합에 의한 대기)의 원인을 제거함으로써 원활한 응답속도를 유지해야 한다.
데이터베이스 모니터 기능은 데이터베이스의 Data Dictionary (V$SYSSTAT, V$SYSTEM_EVENT)를 이용해 메모리, I/O, Latch, 세션 그룹으로 나눠 관련 정보를 추출해 <화면 2>와 같이 9가지 그룹으로 사용자가 Refresh Rate(Interval)를 적용해 주어진 시간에 따라 변화되는 모습을 한 화면에서 볼 수 있다. 이에 성능과 관련된 문제점을 쉽게 파악할 수 있으며, 성능에 지장을 초래한 SQL의 진단 또는 초기 파라미터를 조정할 수 있다.
<화면 2> 데이터베이스 모니터

◆ 데이터베이스 모니터의 주요 기능
① Auto Refresh 설정 기능
② Refresh Rate 설정 기능
③ Alert!s에 대한 Propagation 기능
④ 데이터베이스의 Data Dictionary(V$) 정보 그래픽 디스플레이 기능
이터베이스 모니터의 그래프 정보
① Logical I/O : 논리적인 I/O는 SGA(메모리)에 존재하는 데이터베이스 블럭의 Change, Current, Consistent Read들에 대한 통계 추이의 정보
② Physical I/O : 물리적인 I/O는 데이터파일(디스크)의 해당 블럭을 읽어 SGA(메모리)로 올리거나 또는 메모리에서 변경된 블럭을 데이터파일(디스크)로 작성, 그리고 LGWR에 의해서 온라인 리두(redo) 로그 파일로 작성되는 통계 추이의 정보
③ Event Wait : 데이터베이스는 시스템 또는 세션별로 발생하는 Wait 이벤트 통계 정보를 누적해 기록하는데 풀 스캔(Full Scan)시 I/O를 요청하고 대기하는 ‘Mulit-block Read’, 인덱스 스캔시 I/O를 요청하고 대기하는 ‘Single-block Read’, 테이블 스캔시 버퍼 캐시를 거치지 않는 ‘Direct Patch Read’ 등의 통계 추이의 정보
④ Sessions : Sessions는 데이터베이스에 접속한 모든 세션들을 활동 세션(active), 백그라운드 세션(system), 아이들(Idle) 세션으로 분류해 표현한 정보
⑤ all Rates : 사용자가 요청한 SQL에 대한 구문 분석(parse), 실행(execute), 변경 정보 영구저장(commit), 변경 정보 취소(rollback) 정보
⑥ Miss Rates : 데이터베이스의 대표적인 성능 지표인 버퍼 캐시(Buffer Cache) 미스율, 라이브러리/딕셔너리 미스율(SQL Area), 래치 미스율(Latch)의 정보
⑦ SGA Memory Usage : SGA에 할당된 메모리의 사용률에 대한 정보(Shared Pool, 버퍼 캐스, 로그 버퍼)
⑧ Shared Pool : SGA에 할당된 메모리 중 SQL에 대한 공유 메모리의 Detail 사용률에 대한 정보(라이브러리 캐시, 딕셔너리 캐시, Misc Area 등)
⑨ Index Query % : 데이터베이스에서 사용된 SQL 중 쿼리에 대해 인덱스 사용(Indexed %)과 미사용(Non-Indexed %)에 대한 정보
데이터베이스 모니터의 Alert!
그렇다면 DBA는 현재 데이터베이스가 문제점이 있는지의 여부를 판단하기 위해 항상 데이터베이스 모니터링 툴을 보고만 있어야 하는가? 그렇다면 진정한 탐지 툴(Detection Tool)이라고 할 수가 없을 것이다. 이를 위해 Alert! 기능을 제공한다. 토드 옵션의 데이터베이스 모니터를 찾아보면 모니터링하고자 하는 앞의 9가지 항목들에 대해 임계치(Thresholds)를 설정해 해당 임계치에 도달하면 Alert!를 DBA에게 보여줄 수 있도록 지정할 수도 있다. 그러면 토드가 설치되어 있는 PC의 맨 아래에 Toad Database Monitor라는 아이콘이 나타나서 DBA에게 신호를 보내준다.
헬쓰 체크
데이터베이스 구축 후 시간이 지남에 따라 데이터의 크기는 현저하게 증가하게 되고 또한 다양한 문제점들이 나타나게 되는데, 인스턴스에서 발생하는 문제점들을 DBA가 찾아서 조치하기에는 시간과 비용이 만만치 않다. 이에 DBA는 C 검사를 원하는 항목(SGA, Analyze, Extent, JOB……)들에 대해 조건을 설정한다. 해당 조건을 만족하는 내용에 대해 자동으로 체크해 결과를 보여준다면 DBA의 역할은 그만큼 줄어들 것이며, 이를 통해 데이터베이스에 지장을 초래할 수 있는 원인들을 미연에 방지할 수 있다.
◆ 헬쓰 체크의 주요 기능
① 전체의 아이템을 수행하거나 특정한 아이템만 선택해 체크할 수 있다.
② 분석 결과에 대한 리포트
③ SGA 사용 내역
④ Unanalyzed Segments(테이블, 인덱스, 파티션 테이블/인덱스)
⑤ 100개가 넘는 Extent를 소유한 세그먼트
⑥ JOB의 Broken, Sysdate보다 이전의 JOB, Long running JOB 등
<화면 3>은 토드의 헬쓰 체크 기능을 수행한 화면이다. 여기에는 Checks and Options, Other Settings, Report Output 등 3가지 탭으로 구성되어 있는데, Check and Options 탭에서 이미 지정되어 있는 다양한 인스턴스 체크 사항 중에서 원하는 항목을 지정하고 그에 따른 값을 입력하고 실행하면 Report Output 탭에 Health Check를 수행한 결과를 보여준다.
<화면 3> 데이터베이스 헬쓰 체크

인스턴스 매니저
이 기능은 현재 동작 중인 데이터베이스의 인스턴스에 커넥션을 자동으로 수행해 Startup 상태인지 Shutdown 상태인지를 체크할 수 있으며, 토드에서 직접 Startup/Shutdown 명령을 수행하거나 Init 파라미터 파일을 빌딩(building)할 수도 있다.
<화면 4> 인스턴스 메니저

DB의 문제점을 분석하라!
데이터베이스의 문제점을 파악했으면 과연 이 문제점의 원인은 무엇이며, 현재 데이터베이스 성능에서 병목현상(Bottleneck)이 발생하는 영역은 어디인지에 대해 자세하게 분석해야 한다.
분석 작업은 시작해야 하는 포인트가 중요하다. 예를 들어, 오라클 데이터베이스에서 현재 심각하게 성능이 다운되는 현상이 발생하고 있다면 과연 이 문제가 메모리 쪽인지, I/O 쪽인지, I/O라면 데이터파일인지 리두 로그 파일인지를 파악해야 한다. 메모리라면 Shared Pool인지 데이터베이스 버퍼 캐시인지 리두 로그인지 판단해야 한다. DBA 입장에서 특정 문제점이 발생한 영역을 알 수 있다면 그 부분을 집중적으로 분석해 문제점을 해결해야 하는데, 토드는 이러한 분석을 쉽게 할 수 있는 다양한 기능들을 갖고 있다.
Database Probe
데이터베이스의 구성은 크게 메모리(SGA), 프로세스, 데이터파일(Online Redo Logfile, User Datafile)로 구성되며 서버 프로세스와 백그라운드 프로세스에 의해 자동적으로 운영된다. Database Probe는 <화면 5>와 같이 3개의 그룹으로 나뉘어 각 그룹별로 중요한 정보를 보여주게 된다.
<화면 5> Database Probe

먼저 프로세스 부분은 전용 서버 프로세스와 공유 서버 프로세스의 수 및 병렬 처리 내용과 데이터베이스 서버 프로세스가 사용하는 독점 메모리인 PGA 메모리의 사용 현황의 관계를 보여주고 있으며, 메모리(SGA) 부분은 서버 프로세스가 데이터를 처리하는 버퍼 캐시, SQL과 PL/SQL 문장을 저장하기 위한 Shared Pool, 공유 서버의 세션 정보를 저장하는 Large Pool, 데이터 블럭의 변경된 정보(Before/After)를 저장하는 리두 로그 버퍼, 자바 프로그램을 이용하는 영역의 Java Pool의 사용률을 보여주며, 마지막으로 데이터파일 부분은 파일의 크기와 현재까지의 사용률을 그래픽하게 처리하고 있어 데이터베이스의 전반적인 리소스를 얼마나 사용하고 있는지를 시각적으로 판단해 데이터베이스의 초기 파라미터 및 데이터파일의 크기 또는 리두 로그 파일의 크기 및 개수 등을 조정하는 데 필요한 정보를 제공한다.
◆ Database Probe의 주요 기능
① SGA 각 영역의 Hit Ratio 및 사용률 및 Wait/Retry 정보
② 전용 서버 프로세스 및 공유 서버 프로세스의 수 및 PGA 정보
③ 데이터파일의 전체 크기 및 사용률
Top Session Finder
현재 시스템에서 특정 리소스를 많이 사용하는 오라클 세션들을 발췌해 탑 리스트(Top List)로 보여준다. 앞의 Database Probe를 이용해 현재 데이터베이스 측면을 분석했으면, 그 내부에서 작업 중인 세션들에 대한 자세한 정보를 분석해야 할 것이다. 하지만 그 많은 세션들을 일일이 분석하기란 여간 힘든 일이 아니다. 그 중에서 시스템의 리소스를 많이 사용하는 세션이 문제점을 갖고 있기 때문에, 그에 따른 이벤트 정보를 토대로 탑 세션을 발췌한다. 예를 들어 CPU를 많이 사용하는 탑 세션, I/O를 많이 발생시키는 탑 세션처럼 DBA가 원하는 시스템 리소스 측면을 강조한 기능이라고 할 수 있다. <화면 6>에서는 세션들 중에서 ‘session logical reads’, 즉 논리적인 읽기가 큰 세션부터 내림차순으로 정렬된 정보를 Dataset 형태로 제공하고 있다.
<화면 6> Top Session Finder

◆ Top Session Finder의 주요 기능
① CPU, 메모리, 커서(CURSORS) 등과 같은 자원 그룹별로 문제 세션을 검색
② 데이터베이스 세션 정보의 결과를 Dataset 형태나 Pie Chart 형식으로 제공
세션 브라우저
세션 브라우저 기능은 데이터베이스에 접속 중인 모든 세션들에 대해 총괄적으로 세션 액티비티(Session Activity)를 분석하기 위해 제공된 기능이다. <화면 7>은 특정 세션의 Wait Event에 대한 상세 정보를 ‘Current Waits’와 ‘Total Waits’로 분리해 제공하고 있다. 특정 세션을 선택하면 다음과 같은 상세정보를 동적으로 추출할 수 있다.
<화면 7> 세션브라우저

- 세션 : 선택한 세션의 ID, 프로그램, 모듈, Machine, OS 유저, DB 유저 등의 정보를 제공
- 프로세스 : 선택한 세션의 프로세스 정보 제공
- I/O : 선택한 세션이 발생시킨 I/O 정보인 읽기/쓰기 정보 제공
- Waits : 선택한 세션에서 발생한 Wait Event 정보 제공
- Current Statement : 선택한 세션에서 수행 중인 SQL 문장 정보 제공
- Open Cursors : 선택한 세션이 오픈한 커서 정보 제공
- Access : 선택한 세션이 액세스한 객체 정보 제공
- Locks : 세션 잠금 정보 제공
- RBS Usage : 선택한 세션이 사용한 롤백 세그먼트(Rollback Segment) 정보 제공
- Long Ops : 선택한 세션이 배치(Batch)성 작업을 수행했을 경우 현재까지 진행된 상황에 대한 정보 제공
- Statistics : 선택한 세션에 대한 통계 정보 제공
OS 유틸리티
이 기능은 데이터베이스 측면이 아닌 데이터베이스가 동작 중인 시스템(OS) 부분의 정보를 분석하고자 할 경우 사용한다. 유닉스나 윈도우 계열의 OS를 사용할 경우 또는 해당 OS에 해당되는 정보를 분석하고자 할 경우 유용하게 사용할 수 있다. <화면 8>은 CPU의 사용률을 시스템, 사용자를 구분해 사용되고 있는 정보와 프로세스 정보 및 디스크 I/O에 대한 정보를 그래프로 제공하고 있어, 시스템의 전반적인 자원 사용율을 나타내고 있다.
<화면 8> OS 유틸리티 메뉴

<화면 9> 유닉스 모니터

DB상의 문제점을 어떻게 해결할 것인가?
데이터베이스의 문제점을 감지(detect)하고 분석(diagnostic)했으면, 그에 따른 행동을 취해야 한다. 일반적으로 제시하는 해결방안은 시스템 튜닝, 데이터베이스 튜닝, 애플리케이션 튜닝, SQL Statement 튜닝으로 구분할 수 있는 데, 토드에서는 문제점을 해결하기 위한 다양한 기능이 존재한다.
테이블 스페이스와 테이블 스페이스 맵
이는 데이터베이스의 논리적 구조를 이루는 가장 핵심적인 요소이다. 데이터베이스의 데이터가 존재하는 물리적인 데이터파일과 연결되어 있으며, 그 안에 세그먼트, 익스턴트(Extent), 블럭이라는 구조가 존재하고 있다. 만약 테이블 스페이스의 공간이 부족하거나, 데이터파일에 Fragmentation이 발생해 장애가 발생한 경우라면 해당 테이블 스페이스의 공간을 늘려주는 작업과 그 안에 존재하는 Fragmentation을 Coalesce하는 작업을 수행해 다시 재구성하는 문제를 생각해야 할 것이다. 또한 이로 인해 I/O Wait가 발생해 성능이 떨어지는 원인이 된다면 해당 데이터파일도 다시 재구성하거나 재구축하는 절차를 수행해야 한다. 이러한 과정을 손쉽게 수행할 수 있도록 하는 기능이 바로 테이블 스페이스 기능이다.
토드에서 테이블 스페이스와 데이터파일에 대한 정보를 변경할 수 있으며, 프리 스페이스(Free Space)와 해당 테이블 스페이스에 존재하는 객체 정보를 확인할 수 있다.
그리고 뒤에 있는 Space History와 I/O History 탭에서는 특정 테이블 스페이스나 데이터파일에 대한 Capacity Plan 정보를 확인할 수 있다. <화면 10>은 데이터베이스의 각 테이블 스페이스에 대해 할당된 크기와 가장 큰 연속된 공간 및 프리 스페이스를 보여주고 있다. 만약에 특정 세그먼트의 크기가 부족해 확장될 때 ‘MAX Mb’의 값보다 크다면 확장하지 못하고 에러가 발생하게 된다. 따라서 DBA는 이러한 정보로 각 테이블 스페이스에 속한 오브젝트 중 MAX 값보다 큰 테이블이나 인덱스가 존재한다면 해당 테이블 스페이스에 데이터파일을 추가한다거나 다음 익스턴트의 크기를 줄이기 위해 테이블과 인덱스의 NEXT 옵션을 변경해야 할 것이다.
<화면 10> 테이블 스페이스 예

또한 특정 테이블 스페이스의 물리적인 구조 중에서 가장 작은 단위인 블럭들을 그래픽하게 보여줘 해당 테이블 스페이스의 객체가 차지하고 있는 블럭의 갯수나 세그먼트 정보를 자세하게 확인할 수도 있으며, 데이터파일에 존재하는 Fragmentation도 분석해 Coalesce 과정을 수행할 수 있는데, 이 기능은 <화면 11>의 테이블 스페이스 맵을 활용해 수행할 수 있다.
<화면 11> 테이블 스페이스 예

컨트롤 파일과 리두 로그 매니저
물리적인 데이터베이스 구조인 컨트롤 파일(Control File)과 리두 로그 파일(Redo Log File)에 대한 정보를 확인할 수 있으며, 로그 스위치(Log Switch), 리두 로그 파일 변경 작업, 아카이브 스타트/스톱(Archive Start/Stop)과 같은 특정 작업을 직접 수행할 수 있다. 컨트롤 파일은 데이터베이스의 물리적인 구조에 대한 정보를 저장하고 있으며 각 타입별로 레코드 세션(Record Section)을 사용하게 된다. <화면 12>에서의 컨트롤 파일의 상세내용을 보면 각 세션(“REDO LOG”, “DATAFILE”…)별로 최대 레코드를 갖고, 또한 사용량을 표시하는데, 만약 각 세션의 토탈 레코드들과 사용된 레코드가 동일하게 되면 더 이상 해당 세션에 대한 자원 할당을 할 수 없게 되므로 컨트롤 파일을 재생성해야 된다. 그리고 이러한 정보를 미리 확인해 대처할 수 있다.
<화면 12> 컨트롤 파일 관리

<화면 13> 칸트롤 파일과 리두 로그 매니저

Log Switch Frequency Map
<화면 14>는 하루를 1시간 그룹으로 구분해 각 시간대별로 로그 스위치의 발생 정도를 나타내어 트랜잭션 양을 파악할 수 있으며, 또한 하루 중에 가장 트랜잭션이 많은 시간대를 파악해 그 시간대에 발생할 수 있는 작업(Batch Job) 등을 다른 시간대로 변경해 수행할 수 있도록 하고 있다. Log Switch Frequency Map 기능은 현재 데이터베이스에서 발생하는 로그 스위치의 회수를 체크해 보여준다.
<화면 14> Log Switch Frequency Map

시간대별로 몇 번의 로그 스위치가 발생했는지 파악할 수 있으며 가장 많은 로그 스위치가 발생한 시간이 언제인지를 확인해 DBA로 하여금 로그 파일의 재구성과 리두 로그 버퍼의 크기에 대한 어드바이스를 받을 수 있도록 정보를 제공하고 있으며, 이를 통해 인스턴스에서 체크포인트의 발생 빈도를 예측할 수 있도록 해준다. DBA는 이 정보를 토대로 SGA 메모리의 최적화 상태를 점검할 수 있다.
Rebuild Objects
테이블 스페이스에 대한 문제를 해결하다 보면 그 안에 존재하는 특정 객체에 대해 다시 재구성해야 하는 경우가 발생한다. 테이블 스페이스 레벨에서만 문제가 해결되면 가장 좋겠지만 실제로는 데이터가 존재하는 테이블이나 인덱스 쪽에 더 무게를 둘 수밖에 없게 된다. 이 기능을 이용해 특정 테이블이나 인덱스 또는 특정 유저, 테이블 스페이스에 해당하는 객체에 대해 일괄적으로 또는 개별적으로 Rebuild 과정을 진행할 수 있다.
Repair Chained Rows
데이터베이스의 block_size가 적거나 특정 테이블의 Row가 데이터베이스 블럭의 크기보다 큰 경우에 UPDATE 문장이 발생하는 테이블에 종종 발생되는 Chaining이나 마이그레이션이 일어나게 되는데, 이렇게 하나의 Row가 여러 블럭에 걸쳐 있으면 데이터베이스의 성능이 떨어지기 마련이다. 이 기능은 데이터베이스의 특정 테이블에서 Chaining이나 마이그레이션이 발생할 경우 해당 테이블을 분석해 Chained Row를 해결하고자 제공하는 기능이다. <화면 15>는 ‘CHAIN_TEST’ 테이블에 Chain된 Row가 약 3만 건 정도가 발생한 것인데, 화면 오른쪽에 ‘Repair’ 버튼을 누르면 Chained Row를 제거할 수 있게 된다.
<화면 15> Repair Chanined Rows

Export/Import! Utility Wizard와 SQL*Loader Wizard
Export/Import! Utility Wizard와 SQL*Loader Wizard는 오라클의 Export/Import! 명령과 SQL*Loader를 Wizard 를 통해 쉽게 구현할 수 있도록 제공하는 기능이다. Export/Import!를 이용해 일반적으로 해당 객체를 재구성하는 과정을 거치게 되는데 GUI 환경에서 누구나 손쉽게 사용할 수 있도록 제공하고 있으며, 테이블, 유저, 테이블 스페이스, 데이터베이스 모드를 모두 지원한다. 또한 SQL*Loader의 모든 기능을 지원해 컨트롤 파일을 구성할 경우 이미 지정되어 있는 많은 옵션들을 간단하게 설정할 수 있다.
Server Statistics
이 기능은 현재 인스턴스에 대해 통계 정보를 분석해 보여주며, 인스턴스 내부에 발생하는 다양한 항목들을 DBA가 확인할 수 있다.
Analysis, Waits, Latched, Session, Instance Summary 등의 5가지 탭을 통해 전체 데이터베이스의 통계 정보를 파악한다. 또한 데이터베이스에서 통계치의 값이 어떠한지에 대해 분석해 DBA에게 제시해 준다. 이를 통해 현재 통계정보의 부정확한 값들에 대한 어드바이스를 제시해 DBA로 하여금 최적의 인스턴스 상태를 유지할 수 있는 방향을 제시한다. DBA는 <화면 16>에서 빨간색으로 표시되어 있는 값들에 대해 체크해 인스턴스 환경을 수정할 수 있다.
<화면 16> Server Statistics, 데이터베이스의 대표적인 성능 지수들의 현재 값

이 외에 토드에서 지원되는 문제를 해결할 수 있는 기능을 보면 다음과 같다.
◆ Oracle Parameter and NLS Parameter : Server Statistics 기능에서 제시한 내용을 기준으로 특정 데이터베이스 파라미터를 수정할 경우, 이 기능을 사용해 쉽게 변경할 수 있다.
◆ New Database Wizard : 이 기능은 새로운 데이터베이스를 생성하기 위해 Create Database 명령을 수행하도록 하는 기능이다. DBA가 새로운 데이터베이스를 생성(create)하고자 할 경우 쉽게 GUI 환경에서 생성할 수 있도록 도와주는 위저드 기능이다.
◆ Compare Schema and Compare Database : 서로 다른 데이터베이스끼리 비교를 하거나 특정 스키마들끼리의 비교처럼 DBA가 특정 작업을 수행하기 이전과 이후에 대한 비교 작업을 수행할 경우 적용한다.
데이터베이스 브라우저 기능이란?
지금까지 DBA 기능에 대해 각 기능별로 소개를 했다. 하지만 DBA가 이 모든 기능들을 일일이 하나씩 확인한다면 이것 또한 너무 불편할 것이다.
이를 위해 토드에서는 데이터베이스 관리를 위해 필요한 내용들을 종합적으로 구성해 하나의 화면에서 확인하고 설정할 수 있도록 통합관리 체제로 관리하고 있다. 이 기능이 바로 데이터베이스 브라우저(Database Browser)이다. <화면 17>처럼 데이터베이스 브라우저는 하나의 데이터베이스를 기준으로 정보를 제공하는 것이 아니라 현재 네트워크 상에 존재하는 모든 데이터베이스를 한눈에 확인할 수 있도록 중앙집중 방식을 선택하고 있다. DBA가 A DB, B DB 등을 분산해 관리한다면 업무 효율성도 떨어질 뿐만 아니라 그로 인해 발생하는 시간과 노력에 대한 비용도 한이 없을 것이다. 데이터베이스 브라우저는 다음의 다양한 탭을 갖고 있다.
<화면 17> 데이터베이스 브라우저

◆ 데이터베이스 브라우저의 다양한 탭
- 오버뷰(Overview) : SGA 크기, Shared Pool의 크기, Hit Ratio, Event Wait 정보 확인
- 인스턴스 : 인스턴스 정보 확인
- 데이터베이스 : 데이터베이스 정보 확인
- Options : 해당 데이터베이스에 설정되어 있는 제품의 옵션 리스트 확인
- 파라미터 : 데이터베이스 파라미터 정보 확인
- 세션 : 현재 데이터베이스에 연결되어 있는 세션 정보 확인
- 탑 세션 : 현재 연결되어 있는 세션 중에서 탑 세션 리스트 확인
- RBS 액티비티 : 롤백 세그먼트의 액티비티 정보 확인
- Space Usage : 각 테이블 스페이스의 스토리지 파라미터 정보와 스페이스 정보 확인
- 데이터파일 I/O : 각 데이터파일의 토탈 사이즈, 프리 사이즈(Free Size)와 내부 블럭마다의 읽기/쓰기 회수 등에 대한 정보 확인
SQL 튜닝 엑스퍼트
SQL 튜닝 엑스퍼트는 토드의 DBA 모듈에 포함되어 있는 기능은 아니며, 토드의 엑스퍼트 튜닝 모듈(Xpert Tuning Module)에 있는 기능이다.
DBA가 시스템 퍼포먼스 튜닝만 수행하는 것이 아니라 그 안에서 동작하는 애플리케이션 튜닝에 더욱 많은 시간을 소비할 것이기 때문에 토드를 이용해 이 부분을 해결할 수 있는 방법을 제시하고자 한다. 데이터베이스를 운영하다 많이 접하게 되는 문제는 바로 잘못 작성된 SQL 문장이 될 것이다. 토드의 엑스퍼트 에디션은 현재 데이터베이스에서 잘못 작성되어 성능이 다운되는 요인이 되고 있는 SQL 문장을 찾아 가장 최적의 SQL 문장으로 바꿔주는 기능을 갖고 있다.
SQL 튜닝 엑스퍼트 기능은 SQL 에디터나 프로시저 에디터(Procedure Editor)에서 SQL 문장이나 PL/SQL 문장을 대상으로 개발시에 최적의 SQL과 PL/SQL을 만들고 싶을 경우이거나, 실행했으나 반응 시간(Response Time)이 너무 높게 나타나서 현재 환경에 맞는 최적의 문장을 만들고 싶을 경우 사용한다. 일단 SQL 에디터와 프로시저 에디터 아이콘 버튼을 실행하면 SQL 튜닝 엑스퍼트라는 화면으로 이동할 수 있다. SQL 튜닝 엑스퍼트 화면의 왼쪽에는 네비게이터 패널(Navigator Panel)이라는 것이 있는데, 이 네비게이터 패널의 순서에 따라 SQL 튜닝 과정을 진행하면 된다. 다음은 SQL 튜닝 엑스퍼트에서 SQL 튜닝 과정을 진행하는 절차이다.
1단계, SQL Detail
여기서는 SQL 에디터나 프로시저 에디터에서 수행 중인 SQL 문장을 드래그해 Execution Plan과 해당 SQL 문장에 나타난 객체의 정보를 확인할 수 있다. Execution Plan을 통해 현재 SQL 문장이 어떻게 수행될 것이지 예측할 수 있으며, 해당 테이블에 생성되어 있는 인덱스나 컬럼의 정보를 확인할 수 있다.
<화면 18> SQL Detail Window

2단계, View Advice
이 부분은 현재의 SQL 문장에 대해 Execution Plan의 정보만 갖고 튜닝 액션을 결정할 수가 없을 경우 개발자나 DBA에게 현재 환경에 적합한 가장 최적의 SQL 솔루션을 제공한다.
<화면 19> View Advice Window

- Auto Tune : 이는 오라클 옵티마이저가 판단한 근거를 기준으로 자동으로 현재 SQL 문장에 맞는 최적의 솔루션 리스트를 제공한다. 이는 튜닝 초보자에게 적합한 것으로 SQL 튜닝에 대한 지식이 없더라도 튜닝 솔루션을 찾을 수 있게 한다.
- Advice : 이는 현재 환경에 적합한 Advice List를 보여줌으로써 어느 정도 숙련된 튜너가 자기가 생각한 튜닝 솔루션과 일치하는 사항을 찾아 수행할 수 있도록 정보를 제공한다.
- Manual Tune : 토드의 SQL 튜닝 엑스퍼트에게 의존하지 않고 직접 SQL 문장을 코딩하는 경우 사용한다.
3단계, Compare Scenario
Advice에서 선택한 사항을 토대로 Original SQL 문장과 Advice SQL 문장의 Explain Plan과 SQL 문장을 기준으로 비교할 수 있도록 정보를 제공한다.
<화면 20> Compare Scenario Window

4단계, Execution Scenario
Compare Scenario 스텝까지는 직접 SQL 문장을 실행하지 않은 상태에서 간접적으로 비교를 수행한 것에 반해 이 부분은 직접 Original SQL 문장과 Advice SQL 문장을 실행해 비교할 수 있는 정보를 제공한다. 만약 Trace 정보를 만들고 싶다면 옵션으로 지정할 수도 있다.
실행 과정이 끝나면 Original SQL과 Advice SQL에 대해 그래픽하게 비교할 수 있는 그림이 나타나며 이를 통해 시각적으로 최적의 솔루션을 찾을 수 있다.
<화면 21> Advice 적용 후 성능 향상 기대치 비교

- Index Advice : 만약 View Advice 단계에서 선택한 Advice가 인덱스를 추가·삭제·변경하는 작업이었다면 이번 단계에서는 인덱스에 대한 DDL 명령을 수행해야 한다. 하지만 이를 적용했을 경우 다른 SQL 문장이 영향을 받을 수 있기 때문에 조심스럽게 접근해야 할 것이다. 따라서 실제로는 실행시에 인덱스에 대한 DDL 명령을 수행하지 않고 버추얼하게 수행해 현재 데이터베이스에 영향을 주지 않는 선에서 비교할 수 있도록 정보를 제공한다.
- Rewrite : View Advice 단계에서 선택한 Advice가 문장을 바꾸는 선에서 제공되고 있다면, 현재 Original SQL문장을 대신할 수 있는 대체 SQL 문장을 선택한 경우이다. 이를 통해 현재 과정을 진행하면 Original SQL과 Advice SQL을 전부 실제로 실행하는 과정을 거치게 된다.
- Other Advice : DDL Advice나 SQL Rewrite가 아닌 다른 내용들을 제시한 것을 선택한 경우가 해당된다.
5단계, Execution Results
실행한 내용을 토대로 그 결과를 보여주며 실행시에 생성된 통계 정보를 비교할 수 있다. 토탈 CPU, Elapsed Time, Logical Read, Physical Read 등의 많은 통계 정보를 서로 비교할 수 있다.
6단계, Best Practice
앞의 Advice에서 선택한 사항을 토대로 실제 실행과정을 거친다. 예를 들어, 인덱스 생성 Advice를 선택했다면 4번 단계에서는 가상적으로 생성해 비교를 수행했는데, 이를 비교 검토 후 적용하는 과정이라고 생각하면 된다. 또한 추가적으로 수행할 때 더 적합한 내용들이 있다면, 예를 들어 분석 작업 같은 내용이 여기에 포함될 수 있는데 최적의 상태가 될 수 있는 리스트를 제시하면 튜너는 여기에서 원하는 내용을 선택할 수 있다.
7단계, Tuning Resolution
지금까지 진행해온 모든 사항을 기본으로 해 Original SQL과 Advice SQL에 대해 어느 정도 성능 효과를 보였는지를 확인할 수 있다.
토드의 다양한 기능을 습득하기 바라며
지금까지 토드에서 제공하는 DBA 모듈에 대한 일부 기능을 소개했다. 토드라는 툴은 너무나 많은 기능들을 갖고 있기 때문에 사용자의 입장에서 어떤 기능들이 토드에 있는지조차 모르는 경우가 다반사라고 생각한다. 이렇게 토드에는 숨겨진 많은 기능들이 독자의 업무에 도움이 될 수 있으면 하는 바람이다.
제공 : DB포탈사이트 DBguide.net